{kind=link}
Working with Kaggle's Deep NLP Chatbot Dataset https://www.kaggle.com/samdeeplearning/deepnlp
The trained model is created within deep_nlp_module.py. This is where all the data extraction and preprocessing happens as well as the feature extraction. If you actually want to have a chat with the chatbot, you can clone this project, making sure that the file paths remain the same! All the code for the primitive chatbot can be found in artificial_agent.py.
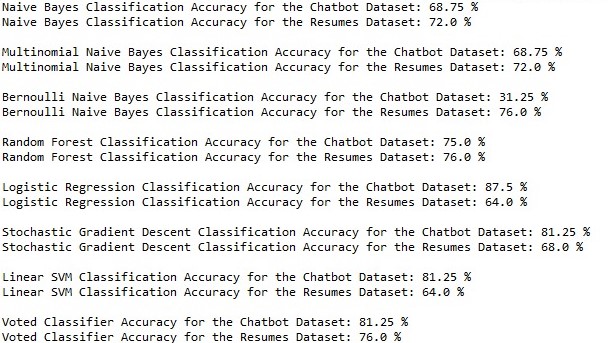
If you want to see the accuracy measures of the all models, make sure you run deep_nlp_program.py, However, an image of the reported accuracies is given below:
To run any code, you can use an IDE or simply calling the .py file from the command line "python ./{filename}.py". Make sure that you are in the directory that contains the .py file before running it from the command line!
I decided to use python for this implementation because it is an extremely powerful language when it comes to data analysis and has extensive libraries about machine learning algorithms and natural language manipulation.
After playing around the Kaggle dataset, I found that the dataset itself was not organized to my liking, and in order to tackle the problem at hand, I had to preprocess the data. First, I took both datasets and tokenized them by words using nltk. Then, using the English language stopwords, I removed any words that have no impact on the classification of the model I am going to implement.
This wasn't enough; however, I still need to extract useful features about the data. So, I extracted the top most commonly used words in the dataset and used those as my features. Through more data preprocessing, I changed the tokenized words in each sample of the dataset into a dictionary of key-value pairs, where the keys are the most common words and the values are booleans: True when the key is a word in the sample.
Finally, I was able to train my data against several models. The basic idea was if a most common word regularly appeared in a certain class in comparison to another, the model will then classify any sample with that word into that predetermined class.
Naive Bayes: It seems like a good starting point to assume that my data points are independent of each other. Needless to say, the Naive Bayes algorithm could have performed better, but given its naive assumption that's expected.
Multinomial & Bernoulli Naive Bayes: Just like Naive Bayes but with a different distribution, I hoped this might improve predictive accuracy, but there was not much difference, except for even a worse result when using Bernoulli for the Chatbot/Therapy dataset.
Random Forest, Logistic Regression, SGD Classification & Linear SVM: With the idea of improving classification accuracy in mind, I ventured out to try some of the most popluar classification algorithms. Some performed very well, but were still subject to the nature of the dataset itself. The problem still remained that some of these algorithms were volatile, i.e. producing a different accuracy every time.
SOLUTION: Voted Classifier: By choosing the top performing algorithm on each dataset, I created my own classifier class that runs every test sample against those top classifiers and takes their vote on the outcome. The most commonly classified class is the "true" class of the provided test sample. This indeed did increase accuracy, but not by as much as I had hoped.