
To augment our application data, we want to pull the full list of all behavioral health facilities in NYC into our platform. With than information, we can see which clinics from the city's master list are active in our platform to be used for data science modeling.
There are 2 components of the application. Both are designed to run inside individual docker containers.
- Spring Batch Application - Contains a docker/Dockerfile and uses gradle docker plugin to generate the image.
- MySQL Databse with 2 databases - A folder mysql/ exists in the project. This folder contains the init script used by the docker compose file for the project. The schema is created for the NYC_DATA and QUARTET_DATA, with some QUARTET data already populated.
Follow these steps to get the application running.
> cd projectdir
# To start the mysql container
> docker-compose up
#After mysql starts up, build spring boot docker image
> gradle clean build
> java -jar build/libs/qtdataloader-0.1.0.jar
#Note - Alternative for last two steps
> gradle buildDocker
> docker run <container_id>
- After running the application, the loadMasterdata job will load the data from the JSON api and add it to the NYC_MASTER_CLINIC_DATA table in the master_data database.
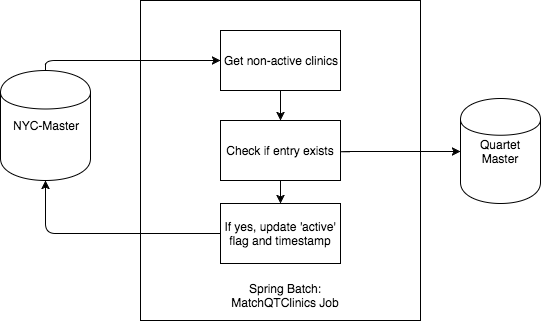
- The matchQtClinics job will match quartet data from the CLINIC_DATA table in the qt database to the master data. Since the quartet data has been preloaded with a few entries, after the job ends, a few of the clinics on the NYC_MASTER_CLINIC_DATA table should have active flag set to true.
In order to create a scheduled synchronus job to sync data between the NYC gov data source and database, a spring batch application is created. The application consists of two jobs, both use a quartz cron trigger to run them.
- importMasterClinicData - Reads the clinic data from the JSON stream provided as the API, for each data tuple- create
a unique id called hash_id as
hash(lower(name_1), lower(name_2), zip)and writes the data in batches of 10 inserting only if unique key not present. This runs every 30 seconds as per the present config, would be changed to nightly.
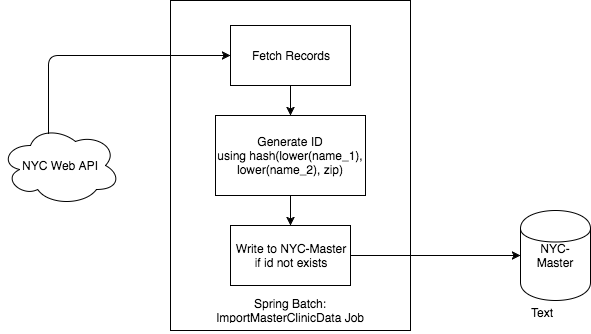
- matchQtClinics - This job loads the unmatched clinics from the NYC data list, if a clinic is present in the quartet datastore, it updates the active flag on the master_data store as 'active' by referencing the hash_id. The match is done using the unique key of name, name_2, zip. This runs every 1 minute as per the present config, would be changed to nightly.
This database contains the NYC_MASTER_CLINIC_DATA table which will hold the master list of NYC clinics. The database will also serve as the database for Spring Batch tables. Below is the schema for NYC_MASTER_CLINIC_DATA.
| id | name_1 | name_2 | street_address | latitude | longitude | city | zip | created_at | active | hash_id |
|---|---|---|---|---|---|---|---|---|---|---|
- Primary Key - ID
- Unique Key - name_1,name_2, zip
- Unique Key - hash_id
This databse contains the clinic_data table. This table is assumed to store the Quartet clinic info in the below schema.
| id | name_1 | name_2 | street_address | city | zip | created_at |
|---|---|---|---|---|---|---|
- Primary Key - ID
- Unique Key - name_1,name_2, zip
Spring Batch Application Properties
| Property | Description |
|---|---|
| quartz.enabled | Flag to enable or disable cron |
| loadMaster.cron | Cron expression for LoadMasterData job |
| quartetMatch.cron | Cron expression for quartetMatch job |
| app.datasource.[main, qt].[url,username, password] | Data source specific info for main_data and qt datasource |
| api.url | API Url to fetch master data from |
| smtp.enabled | Flag to enable/disable smtp emails |
| smtp.[to,from].email | To and From notification SMTP emails |
| smtp.[host,user,password, port] | SMTP specific flags for notification email |
| smtp.password | SMTP password for the account |
-
An initial load of the full data set into a new data store housed within our infrastructure
This load is done via a synchronous batch job reading data from the API and writing to the database only if the the key does not exist.
-
How would structure the schema to make it easily accessible to all other internal systems?
The schema is stored in a MySQL database, since the specified schema is standardized by the NYC data source. It is stored in a data based called NYC-Master, with fields like name_1, name_2, city, zip etc.
-
Establishing a nightly job to pull in the new facilities added to this master list and update our data store
The data pull job which runs at startup has a nightly cron trigger. Using quartz, the job is pulled from the jobRepository and run. Upon the nightly runs, all data is pulled from the API, but only newer data is written to the databse. This distiction is done by creating an id using the
hash(lower(name_1), lower(name_2), zip)in lower_case. -
Identifying any clinic in this NYC master list that match active clinics within Quartet. Assume there is a Quartet data store that has clinic names, addresses, and zip of the active clinics on our platform
The matchQtClinics job fetches rows from the NYC master table which are not active, checks if an entry with the same name, zip and address is present in the quartet data source. If so, it adds an active flag on the NYC-Master table.
-
What considerations would you make to improve matches and eliminate false positives?
In order to improve matches and eliminate false positive, we can run a nightly job on the Quartet-Master table where we create a unique id using the common function
hash(lower(name_1), lower(name_2), zip). This would reduce the chances of dirty data giving false positives. -
How/where would you store this match?
If a clinic gets matches, a flag is set on the NYC-Master table with a timestamp
matched_at. Since the rows are indexed on the flagactiveit will be easy for another source to pull the matched clinics from NYC-Master. -
Monitoring and alerting to let you know if the nightly update and match jobs fail
Using a
JobExecutionListenerSupportclass, upon completion of a job, a Javamail email is sent out to the required email address providing details of the successful/failed jobs. As of now, the application logs the success message. If a SMTP server is setup, the details can be added in application.properties and smtp.enabled can be switched to true. This is done independently for both match and update jobs.
What if instead of a nightly feed, data was streamed to you in real time? Talk about how you may change your design to support such a need - diagrams help too!
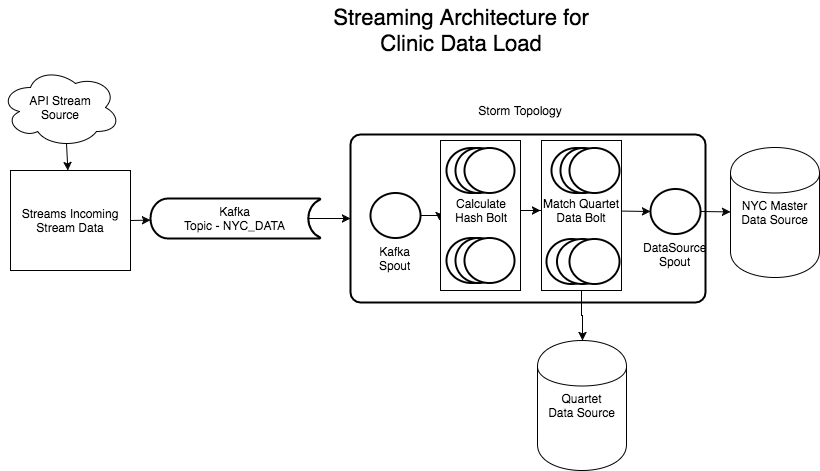
As depected in the above diagram, when using a streaming architecture, we will use a queuing system such as Kafaka to separate producers and consumers. The Kafka stream will then be fed into a Storm Topology. Here, a set of bolts will be responsible for calculating the hash_id for the incoming clinic data. In the next set of bolts, for each tuple we will query the quartet data source and update the tuple as active or inactive. The Spout will then load the data to the master data store.