![]()



Biblioteca Python para cálculo de capacidade de carga de fundações profundas utilizando métodos semi-empíricos da literatura geotécnica brasileira.
| Método | Ano | Coeficientes |
|---|---|---|
| Aoki-Velloso | 1975 | K, α, F1, F2 |
| Aoki-Velloso Laprovitera | 1988 | α corrigidos por tipo de estaca |
| Décourt-Quaresma | 1978 | Np, Nl, α, β |
| Teixeira | 1996 | α, β simplificados |
Ideal para scripts e backend.
pip install calculus-coreInclui Streamlit, Pandas e Altair.
pip install "calculus-core[streamlit]"git clone https://github.com/usuario/calculus-core.git
cd calculus-core
uv sync --all-extrasfrom calculus_core import get_calculator_instance, Estaca, PerfilSPT
# Criar perfil SPT (suporta profundidades fracionárias)
perfil = PerfilSPT(nome_sondagem='SP-01')
perfil.adicionar_medidas([
(1.0, 3, 'argila_arenosa'),
(2.0, 6, 'areia_argilosa'),
(3.0, 12, 'areia'),
(4.0, 15, 'areia'),
(5.0, 18, 'areia'),
])
# Criar estaca
estaca = Estaca(
tipo='pré_moldada',
processo_construcao='deslocamento',
formato='circular',
secao_transversal=0.3, # diâmetro em metros
cota_assentamento=3.0,
)
# Calcular
calculator = get_calculator_instance('aoki_velloso_1975')
resultado = calculator.calcular(perfil, estaca)
print(f"Resistência de Ponta: {resultado.resistencia_ponta:.2f} kN")
print(f"Resistência Lateral: {resultado.resistencia_lateral:.2f} kN")
print(f"Capacidade de Carga: {resultado.capacidade_carga:.2f} kN")
print(f"Carga Admissível: {resultado.capacidade_carga_adm:.2f} kN")O projeto inclui catálogos pré-definidos para todos os tipos de estacas:
from calculus_core.domain import EstacaFactory
# Listar tipos disponíveis
tipos = EstacaFactory.listar_tipos_estaca()
# ['pre_moldada', 'escavada', 'helice_continua', 'raiz', 'franki', 'omega', 'metalica']
# Criar estaca do catálogo
estaca = EstacaFactory.criar_helice_continua('HELICE_500', cota_assentamento=4)
estaca = EstacaFactory.criar_metalica('HP_310x79', cota_assentamento=4)
estaca = EstacaFactory.criar_pre_moldada('CIRCULAR_330', cota_assentamento=3)
# Listar perfis disponíveis
perfis = EstacaFactory.listar_perfis_por_tipo('helice_continua')
# ['HELICE_300', 'HELICE_350', 'HELICE_400', ...]# Busca exata (erro se não encontrar)
medida = perfil.obter_medida(2.0, estrategia='exata')
# Mais próxima (padrão)
medida = perfil.obter_medida(2.3, estrategia='mais_proxima')
# Camada anterior (conservador)
medida = perfil.obter_medida(2.5, estrategia='anterior')
# Interpolação linear
medida = perfil.obter_medida(2.25, estrategia='interpolar')
# N_SPT médio em intervalo
media = perfil.obter_n_spt_intervalo(1.0, 5.0, metodo='media')Para comparar cenários, utilize as funções da API de lote:
from calculus_core import (
calcular_todos_metodos_uma_estaca,
calcular_um_metodo_todas_estacas,
calcular_todos_metodos_todas_estacas,
serializar_resultados
)
# 1. Comparar todos os métodos para uma estaca
resultados = calcular_todos_metodos_uma_estaca(perfil, estaca)
# 2. Comparar tipos de estaca para um método
resultados = calcular_um_metodo_todas_estacas(
perfil,
metodo='aoki_velloso_1975',
cota_assentamento=10
)
# 3. Matriz completa de comparação
resultados = calcular_todos_metodos_todas_estacas(
perfil,
cota_assentamento=3
)
# Converter para lista de dicionários (compatível com JSON/Pandas)
dados = serializar_resultados(resultados)
# Exemplo: Usando com Pandas (opcional)
import pandas as pd
df = pd.DataFrame(dados)A biblioteca suporta dados de Cone Penetration Test (CPT) e conversão para SPT equivalente:
from calculus_core.domain.soil_investigation import (
PerfilCPT,
converter_cpt_para_spt
)
# Criar perfil CPT
cpt = PerfilCPT(nome_sondagem='CPT-01')
cpt.adicionar_medidas([
(1.0, 2.5, 50.0), # prof(m), qc(MPa), fs(kPa)
(2.0, 3.0, 60.0),
(3.0, 3.5, 70.0),
(4.0, 4.0, 80.0),
(5.0, 4.5, 90.0),
])
# Converter para SPT (Correlação de Robertson 1983)
spt_equivalente = converter_cpt_para_spt(cpt, 'robertson_1983')
# Usar perfil convertido nos cálculos tradicionais
resultado = calculator.calcular(spt_equivalente, estaca)src/calculus_core/
├── domain/ # Lógica de negócio pura
│ ├── model.py # Entidades (Estaca, PerfilSPT)
│ ├── value_objects.py # Objetos de valor
│ ├── calculation/ # Estratégias de cálculo
│ ├── pile_types.py # Tipos específicos de estaca
│ ├── pile_catalogs.py # Catálogos pré-definidos
│ ├── soil_types.py # Sistema de mapeamento de solos
│ ├── soil_investigation.py # Perfil CPT e conversões
│ └── method_registry.py # Registro de métodos
│
├── adapters/ # Infraestrutura
│ └── coefficients/ # Provedores de coeficientes
│
├── service_layer/ # Casos de uso
│ └── services.py # Serviços de aplicação
│
├── entrypoints/ # Interfaces externas
│ ├── cli.py # Interface de linha de comando
│ └── streamlit_app/# Interface web
│
└── bootstrap.py # Raiz de Composição (Composition Root)
from calculus_core.domain.method_registry import register_method
from calculus_core.domain.calculation import MetodoCalculo
@register_method(
method_id='meu_metodo_2024',
name='Meu Método',
version='2024',
description='Minha implementação',
reference='Referência bibliográfica',
authors=['Autor'],
supported_pile_types=['all'],
supported_soil_types=['all'],
)
class MeuMetodoCalculator(MetodoCalculo):
def calcular(self, perfil_spt, estaca):
# Implementação
passO sistema de mapeamento de solos permite que cada método use sua própria classificação:
from calculus_core.domain import map_soil_type, TipoSoloCanonical
# Tipo canônico
solo = TipoSoloCanonical.AREIA_ARGILOSA
# Mapear para método específico
nome_av = map_soil_type(solo, 'aoki_velloso') # 'areia_argilosa'
nome_dq = map_soil_type(solo, 'decourt_quaresma') # 'areia'# Rodar todos os testes
uv run pytest
# Com cobertura
uv run pytest --cov=calculus_core
# Testes específicos
uv run pytest tests/test_domain.py -vuv run calculus-app
# Abre interface Streamlit em http://localhost:8501Abaixo estão algumas capturas de tela da interface web do Calculus-Core:
 Visão geral do aplicativo e seleção de módulos.
Visão geral do aplicativo e seleção de módulos.
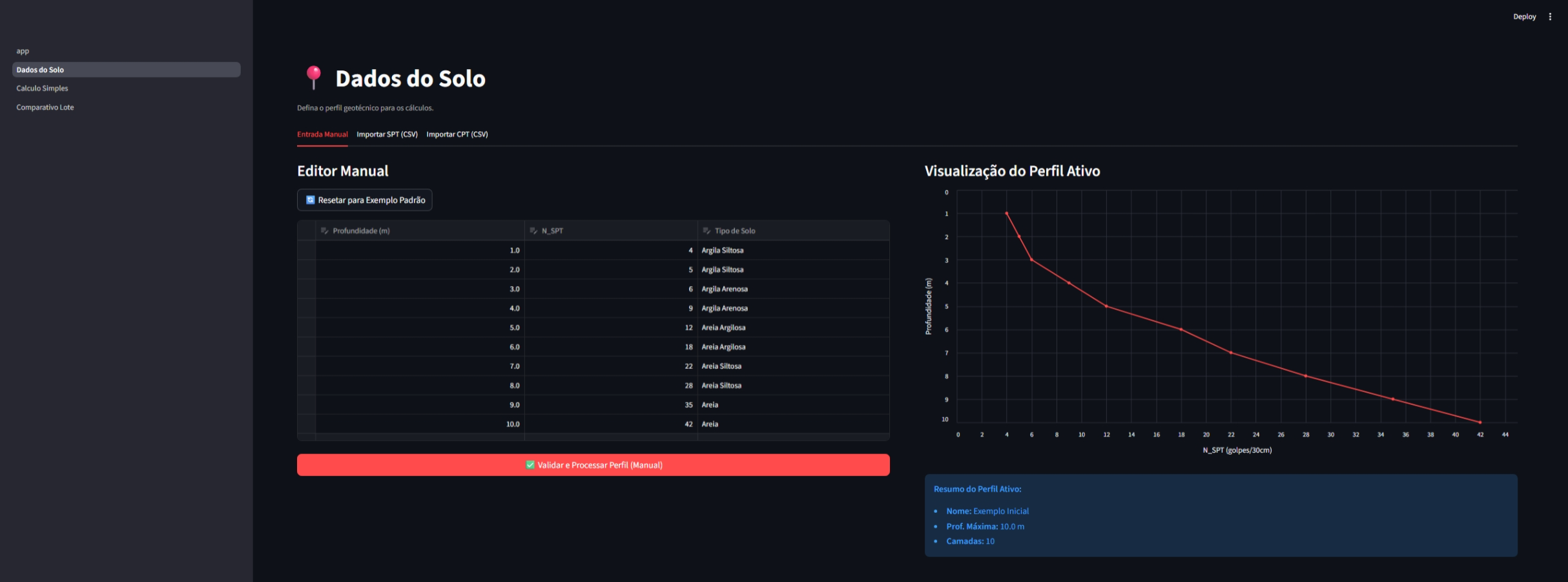 Importação e edição de perfis de sondagem SPT e CPT.
Importação e edição de perfis de sondagem SPT e CPT.
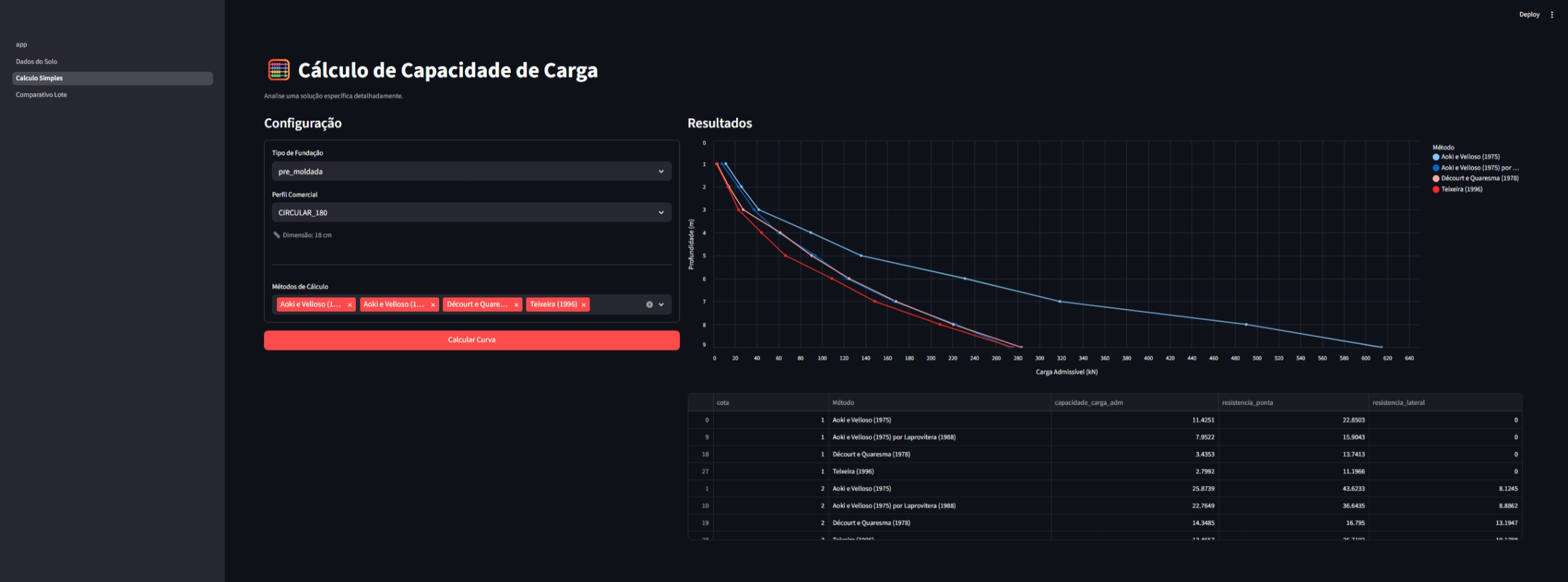 Cálculo detalhado para uma configuração específica de estaca e profundidade.
Cálculo detalhado para uma configuração específica de estaca e profundidade.
O módulo de lote permite comparações rápidas entre diferentes cenários:
| Métodos | Estacas | Global |
|---|---|---|
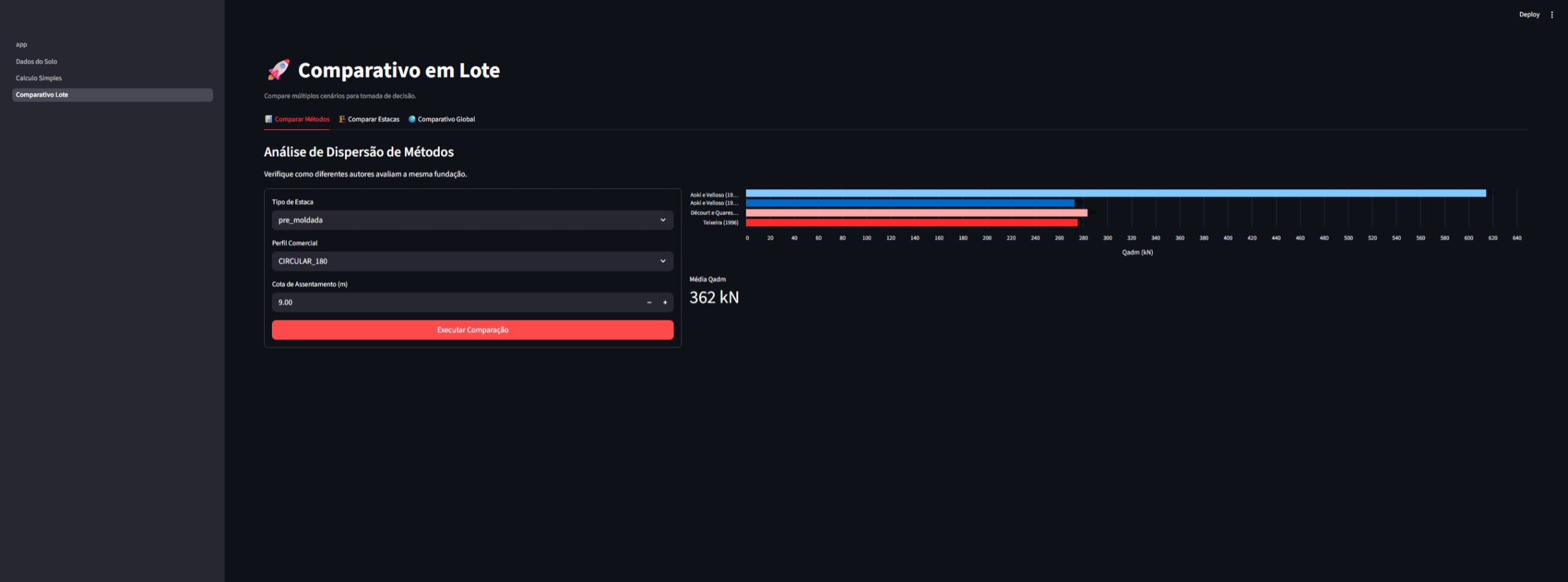 |
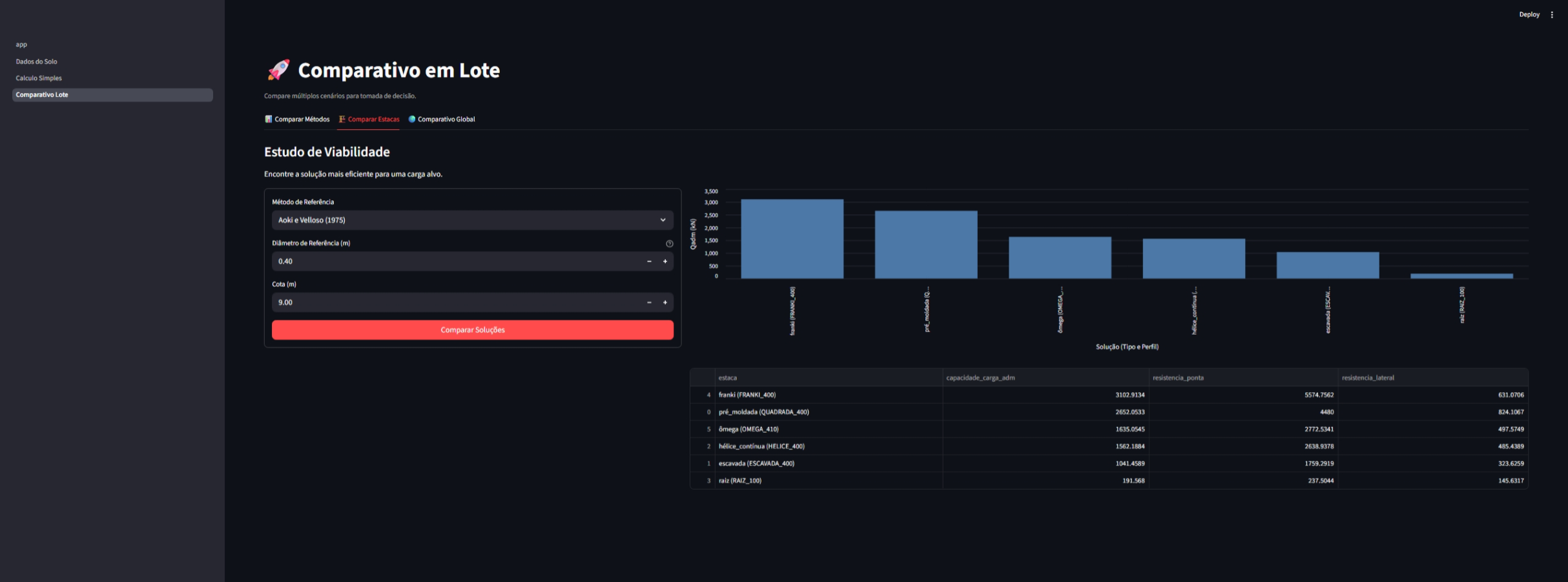 |
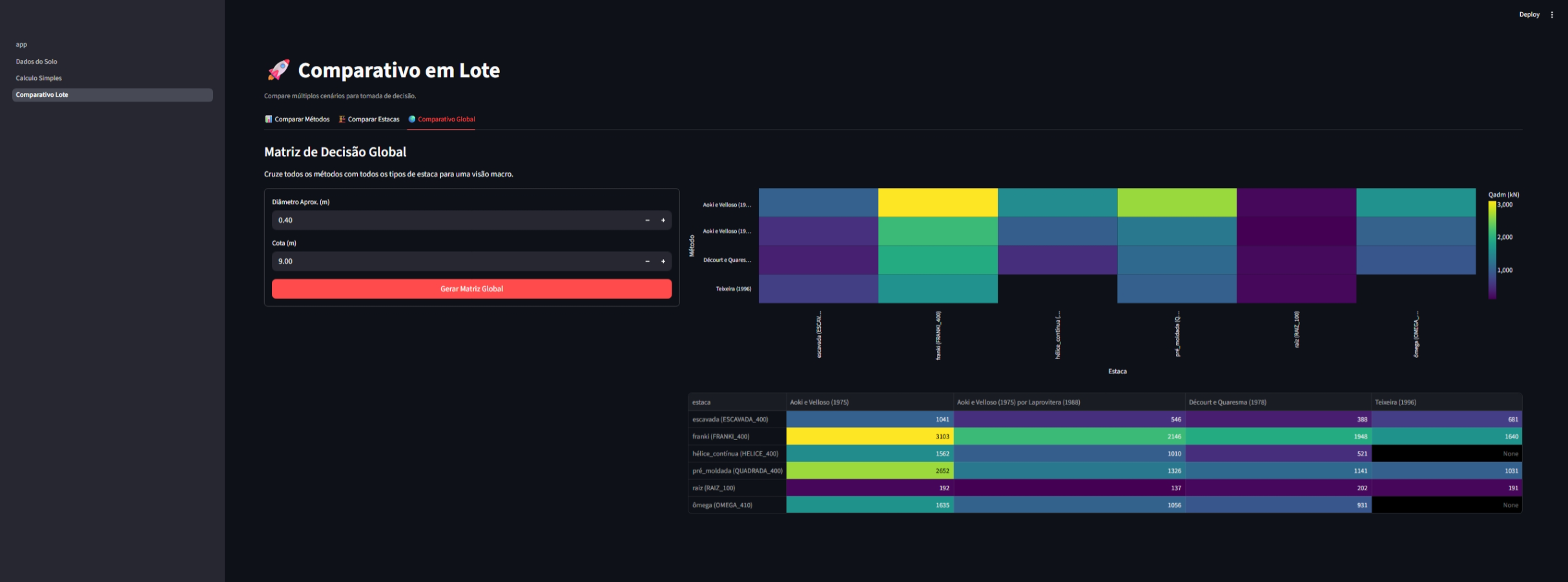 |
| Comparativo de métodos | Comparativo de estacas | Análise global |
Este projeto utiliza Commitizen para padronização de commits e gerenciamento de versões.
Para realizar um commit padronizado:
uv run task czPara gerar um novo release (bump de versão e changelog):
uv run cz bumpMIT License - veja LICENSE para detalhes.