The complexity of neural networks and deep learning in modern day technology has created new opportunities for all researchers in various fields. Its applications are both wide-spread and has become increasingly accurrate. One application that is widely used today is loan predictions. In this model, we will build a neural network of various layers/sizes to predict whether an applicant will be succesful or not if they are provided funding by Alphabet Soup.
Since funding relies primarily factors such as success and ability to pay back (related sometimes), we decided the target for our model is success since it is charity based. To reach our output, we initially included all data but binned 2 columns: classification, and application type to minimize observation errors. Once completed, it was standard procedure with splitting the data set, scaling, and then fitting the data. Our initial neural network is shown below. Data was also saved every 5 epochs.
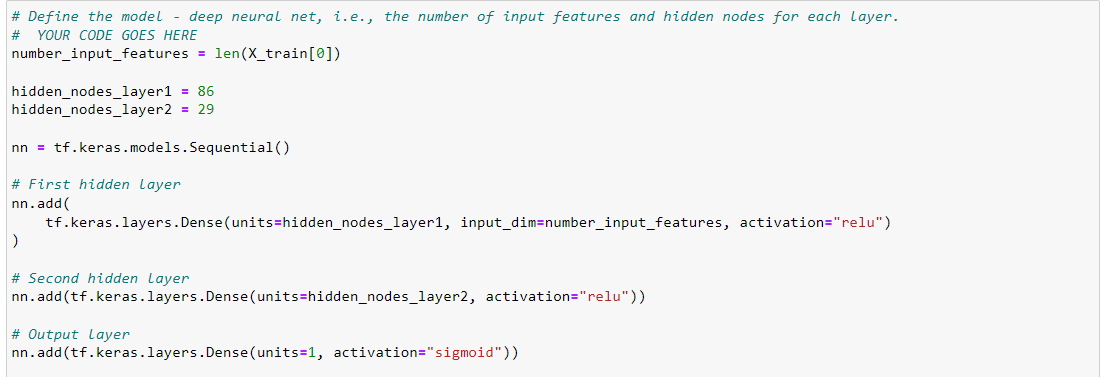
Results were lack luster and only achieved in accuracy score of 69%.
To improve our model several appraoches were taken. Removed 2 columns that may not provide relevant information such as 'Use case other' and 'Affil other', additional layers were then added with more neurons, and lastly, some of the activation functions of the hidden layers are changed to sigmoid. While each iteration of the new NN is an overall improvement from the first model, its important to note that our 2nd model performed the best with an accuracy of 72%.

To decide on neuron number, arbitrary values were intially chosen and was primarily trial and error but unforunately could not reach 75% although progress is close.
Overall, this module highlights 1 important note when it comes to NN's. Too many additional changes aren't always good. The addition of sigmoid function greatly reduced our performance. To better improve this model, we should play around more with model 2 in terms of neuron numbers in each layer as it seems to have the most promising prediction. We can also consider removing other columns in affiliation and use case. Overall the model shows good promise and further optimizations can likely help reach the 75% thresh-hold.