



MindSpore AUDIO is a toolbox of audio models and algorithms based on MindSpore. It provides a series of API for common audio data processing,data enhancement,feature extraction, so that users can preprocess data conveniently. Also provides examples to show how to build audio deep learning models with mindaudio.
The following is the corresponding mindaudio versions and supported mindspore versions.
| mindaudio | mindspore |
|---|---|
| main | master |
| 0.4 | 2.3.0/2.3.1 |
| 0.3 | 2.2.10 |
# read audio
>>> import mindaudio.data.io as io
>>> audio_data, sr = io.read(data_file)
# feature extraction
>>> import mindaudio.data.features as features
>>> feats = features.fbanks(audio_data)The released version of MindSpore AUDIO can be installed via PyPI as follows:
pip install mindaudioThe latest version of MindSpore AUDIO can be installed as follows:
git clone https://github.com/mindspore-lab/mindaudio.git
cd mindaudio
pip install -r requirements/requirements.txt
python setup.py installMindSpore AUDIO provides a series of commonly used audio data processing apis, which can be easily invoked for data analysis and feature extraction.
>>> import mindaudio.data.io as io
>>> import mindaudio.data.spectrum as spectrum
>>> import numpy as np
>>> import matplotlib.pyplot as plt
# read audio
>>> audio_data, sr = io.read("./tests/samples/ASR/BAC009S0002W0122.wav")
# feature extraction
>>> n_fft = 512
>>> matrix = spectrum.stft(audio_data, n_fft=n_fft)
>>> magnitude, _ = spectrum.magphase(matrix, 1)
# display
>>> x = [i for i in range(0, 256*750, 256)]
>>> f = [i/n_fft * sr for i in range(0, int(n_fft/2+1))]
>>> plt.pcolormesh(x,f,magnitude, shading='gouraud', vmin=0, vmax=np.percentile(magnitude, 98))
>>> plt.title('STFT Magnitude')
>>> plt.ylabel('Frequency [Hz]')
>>> plt.xlabel('Time [sec]')
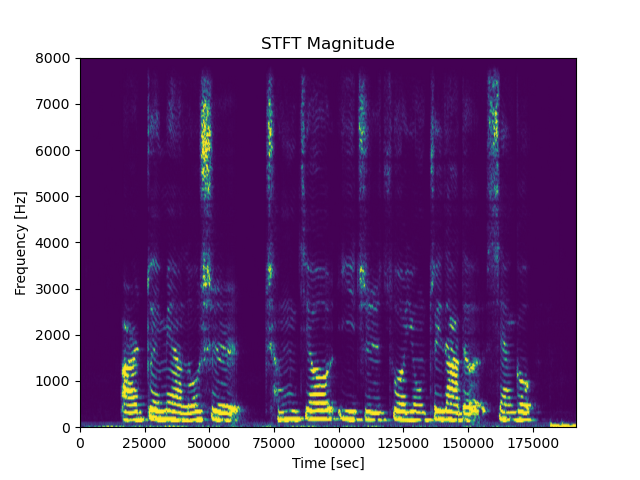
>>> plt.show()Result presentation:
We appreciate all contributions to improve MindSpore Audio. Please refer to CONTRIBUTING.md for the contributing guideline.
This project is released under the Apache License 2.0.
If you find this project useful in your research, please consider citing:
@misc{MindSpore Audio 2022,
title={{MindSpore Audio}:MindSpore Audio Toolbox and Benchmark},
author={MindSpore Audio Contributors},
howpublished = {\url{https://github.com/mindspore-lab/mindaudio}},
year={2022}
}