Here is the official repo for "Revisiting Pre-training in Audio-Visual Learning", which brings some interesting findings of pre-training in audio-visual learning.
Paper Title: "Revisiting Pre-training in Audio-Visual Learning"
Authors: Ruoxuan Feng, Wenke Xia and Di Hu
[arXiv]
We focus on a pair of typical heterogeneous modalities, audio and visual modality, where the heterogeneous data format is considered to bring more chances in exploring the effectiveness of pre-trained models. Concretely, we concentrate on two typical cases of audio-visual learning: cross-modal initialization and multi-modal joint learning.
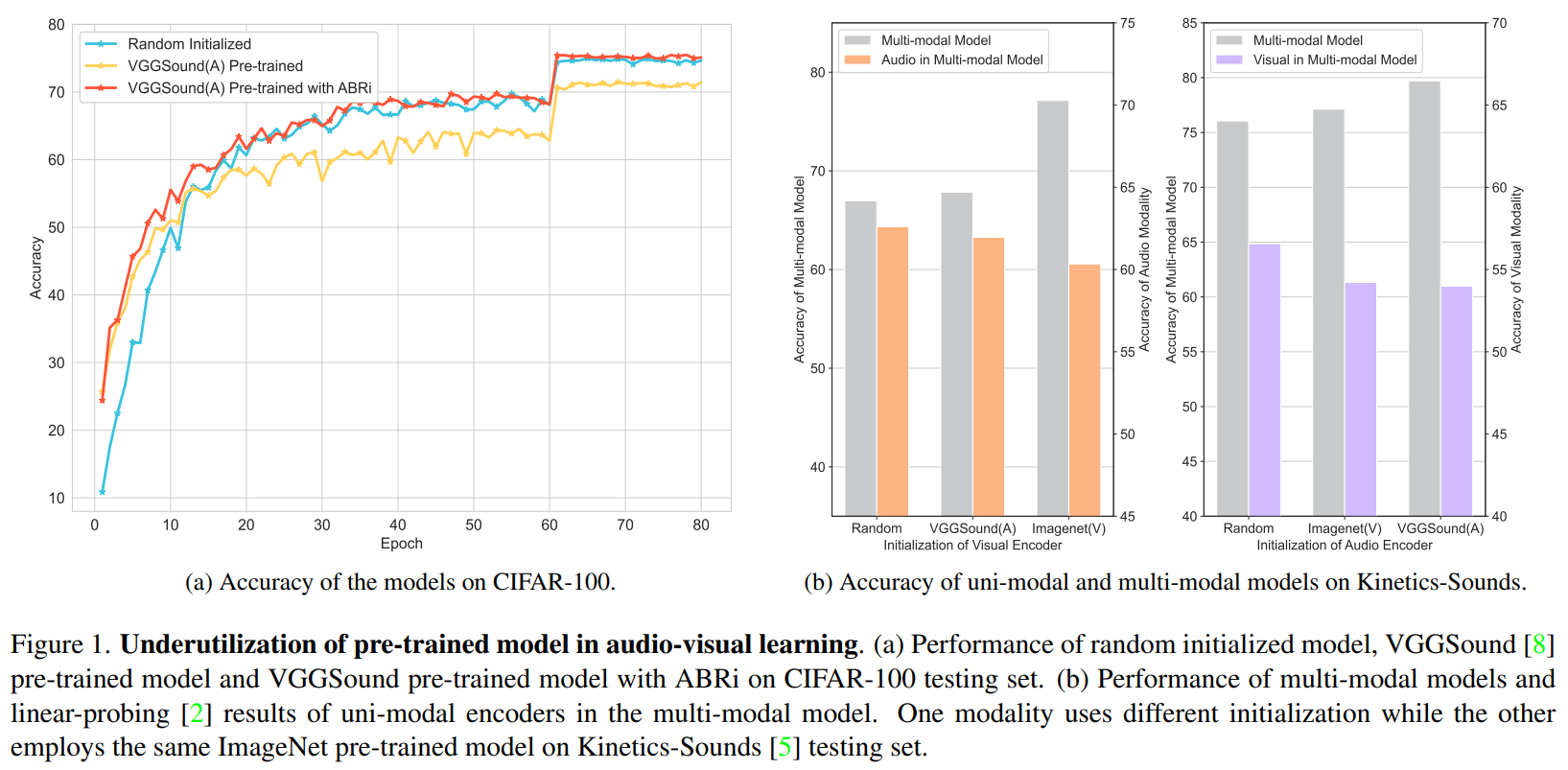
We find that the underutilization of not only model capacity, but also model knowledge limits the potential of the pre-trained model in the multi-modal scenario, as shown in the following figure.
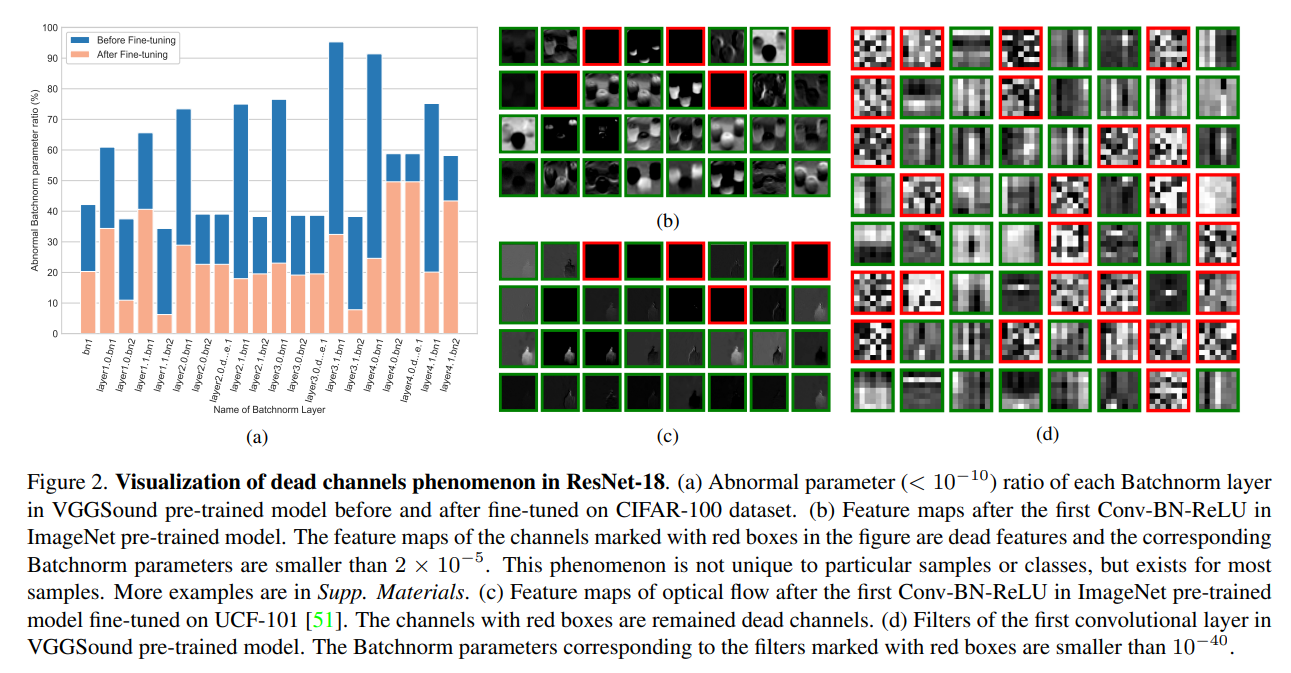
We discover that the absolute value of some parameter pairs (
In experiments we find that the channels with abnormal Batchnorm parameters are more likely to produce “dead features ” after ReLU. This phenomenon does not merely exist for particular samples or classes but for most samples, indicating the channels are hard to be activated. We name these channels as “dead channels”. The abnormal
Although introducing a stronger pre-trained encoder for one modality in the multi-modal model is very likely to improve the performance, we find that this could damage the representation ability of the other, as shown in the first figure. Both of the pre-trained encoders could have not yet adapted to the target task and thoroughly exploited the knowledge from the pre-trained model.
Recent work preliminarily pointed out that high-quality predictions of one modality could reduce the gradient back-propagated to another encoder. When directly initializing encoder with pre-trained model, predictions with high quality could be produced on the samples of one modality at the beginning, which are considered to be easy-to-learn. This could exacerbate the insufficient optimization of the encoders.
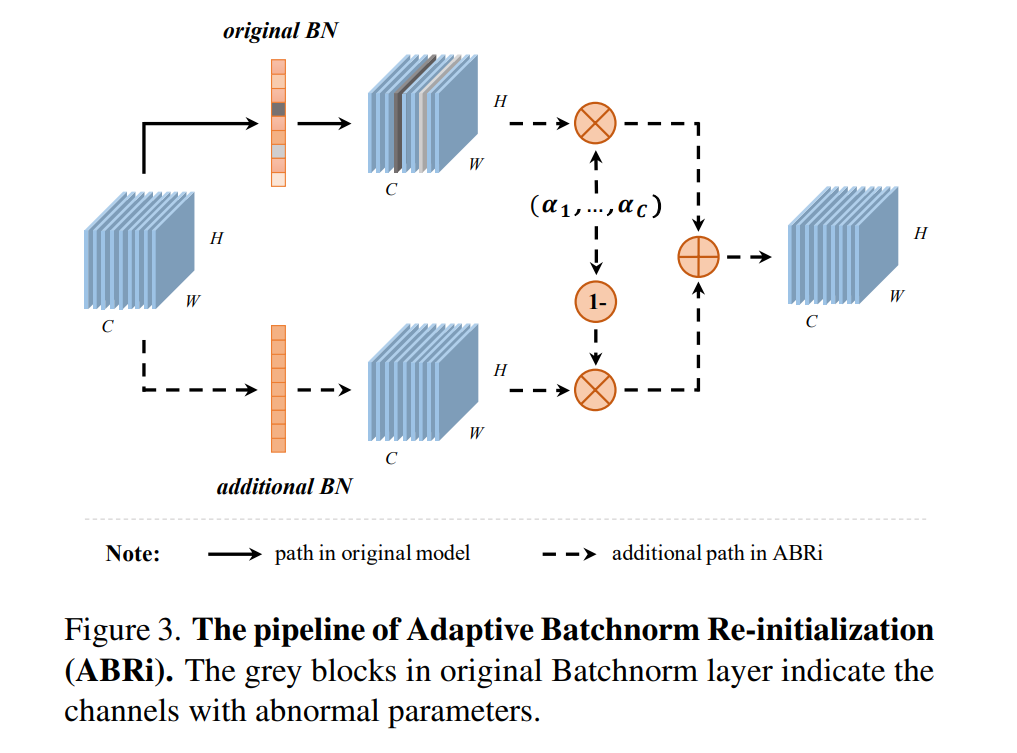
We propose Adaptive Batchnorm Re-initialization (ABRi) to minimize the negative impact of abnormal parameters while ensuring coordination. An additional initialized Batchnorm layer is adaptively combined with each original Batchnorm layer.
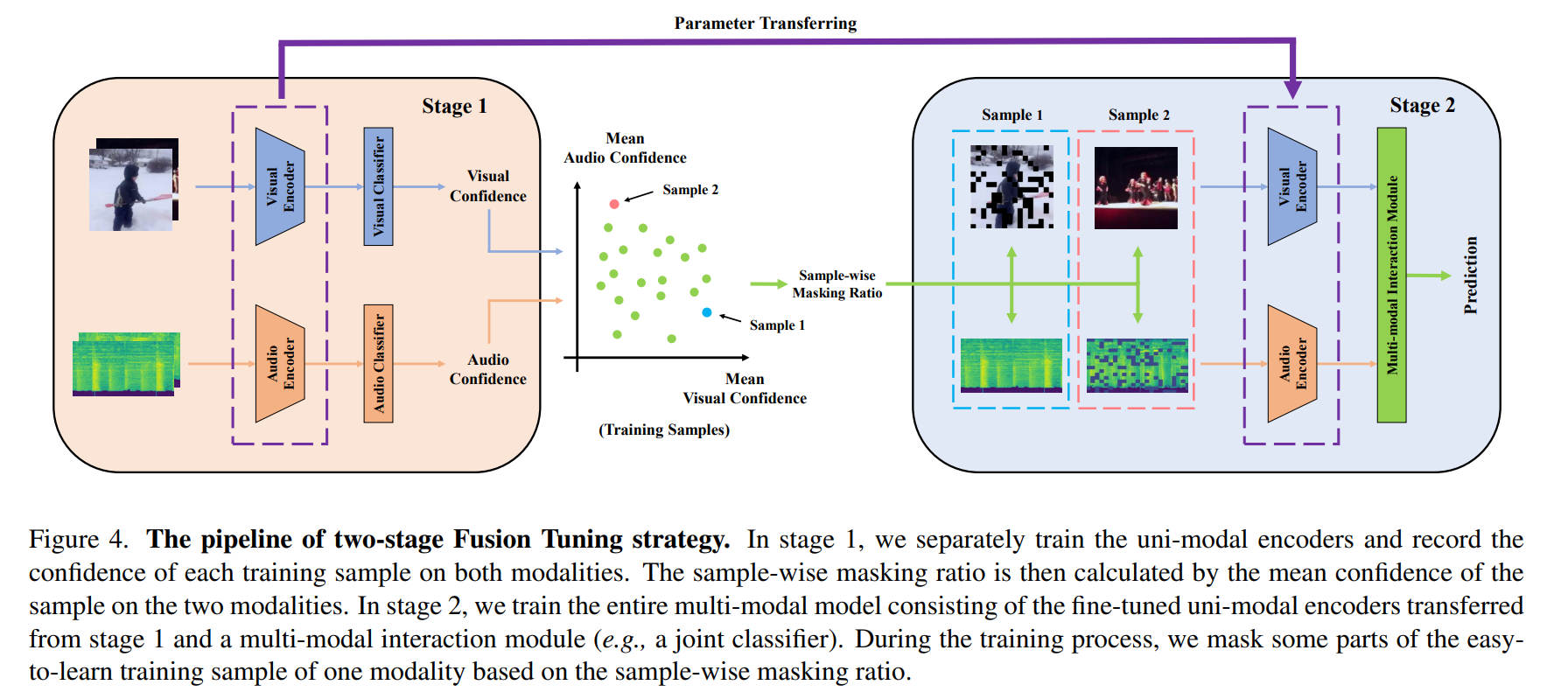
We propose a Two-stage Fusion Tuning (FusT) strategy:
- Fine-tune the uni-modal encoders on their own uni-modal dataset detached from the multi-modal dataset. (Stage 1)
- Fine-tune the complete multi-modal model while randomly masking some parts of the easy-to-learn samples. (Stage 2)
The difficulty of the samples reflected by the sample-wise mean confidence in Stage 1.
Our proposed methods are simple and intuitive attempts. We hope these could inspire future works.
If you find this work useful, please consider citing it.
@article{feng2023revisiting,
title={Revisiting Pre-training in Audio-Visual Learning},
author={Feng, Ruoxuan and Xia, Wenke and Hu, Di},
journal={arXiv preprint arXiv:2302.03533},
year={2023}
}