反射是什么?
Java反射允许在运行时获取类的信息并动态操作对象
- 运行时获取类的完整结构信息
- 动态对象创建
- 动态方法调用
- 访问和修改字段值
Java动态代理?
在运行时动态生成代理对象,增强目标对象的方法
- JDK动态代理:基于接口实现,被代理类需要实现一个或多个接口。JDK在运行时生成实现指定接口的代理类,并通过
InvocationHandler拦截并增强方法调用。- CGLIB动态代理:基于继承实现,在运行时生成代理类的子类,通过
MethodInterceptor拦截目标方法并增强
注解本质上是一个继承了Annotation的特殊接口,所以注解也叫声明式接口,其具体实现类是Java运行时生成的动态代理对象。
通过反射获取注解时,返回的是Java运行时生成的动态代理对象。通过动态代理对象调用自定义注解方法,会最终调用AnnotationInvocationHandler的invoke方法。
根据注解的作用范围,Java注解可以分为以下几种类型:
- 源码级别注解:仅存在于源码中,编译后不会保留。
@Retention(RetentionPolicy.SOURCE)- 如
@Data注解
- 类文件级别注解:保留在
.class文件中,但运行时不可见Retention(RetentionPolicy.CLASS)
- 运行时注解:保留在
.class文件中,并且可以通过反射在运行时访问@Retention(RetentionPolicy.RUNTIME)
- 可变性。
String是不可变的,一旦创建,内容无法修改,每次修改都会创建新的对象。StringBuilder和StringBuffer是可变的,可以直接对字符内容进行修改而不会创建新的对象 - 线程安全性:String因为不可变,天然线程安全。
| 特性 | String |
StringBuilder |
StringBuffer |
|---|---|---|---|
| 不可变性 | |||
| 线程安全 | |||
| 性能 | |||
| 使用场景 |
Lambda表达式:简化匿名内部类,支持函数式编程- 函数式接口:仅含一个抽象方法的接口,可用
@FunctionalInterface注解标记 Stream API:提供链式操作主力聚合函数,支持并行处理Optinal类:封装可能为null的对象,减少空指针异常
线程和进程的区别?
进程就是程序的一次执行过程,是系统运行程序的基本单位。在Java中,启动main函数时就启动了一个JVM的进程,而main函数所在的线程就是这个进程中的一个线程,也称主线程。
线程是一个比进程更小的执行单位。一个进程在执行过程中可以产生多个线程。同一个进程中的多个线程共享进程的堆和方法区资源,每个线程又有自己私有的程序计数器、虚拟机栈和本地方法栈。
- 进程是程序的一次执行实例,拥有独立的内存空间和系统资源。资源分配的基本单位,独立运行。
- 线程是进程内的一个执行单元,共享进程的内存和资源。CPU调度的基本单位,共享进程资源。
一个Java进程中,有
main线程(程序入口)、Reference Handler(清除reference线程)、Finalizer(调用对象finalize方法的线程)、Sigal Dsipatcher(分发处理给JVM信号的线程)、Attach Listener(添加事件)
Java线程和操作系统的线程有啥区别?
JDK1.2之前,Java线程是基于绿色线程(
Green Threads)实现的,这是一种用户级线程,不依赖于操作系统。JDK1.2及以后,Java线程改为基于原生线程(
Native Threads)实现,JVM直接使用操作系统原生的内核级线程(内核线程)来实现Java线程,由操作系统内核进行线程的调度和管理。
僵尸线程?
Java中如何创建线程?
- 继承
Thread类- 实现
Runnable接口- 实现
Callable接口
线程的生命周期和状态?
Java线程有6中不同的状态:
NEW:初始状态,线程被创建出来但还没有调用start()RUNNABLE:运行状态,调用线程start(),可以运行/获得时间片正在运行状态BLOCKED:阻塞状态,竞争锁失败后的状态WAITING:等待状态,获取锁成功后,调用对象的obj.wait()方法,释放对象锁并进入waiting状态TIMED_WAITING:超时等待状态,获得锁调用对象的obj.wait(timeout)方法,或者Thread.sleep(timeout)方法TERMINATED:终止状态,线程run方法执行结束
线程安全要考虑的三个方面?
- 可见性:一个线程对共享变量的修改,对其它线程都立即可见
- 有序性:一个线程内代码按编码顺序执行
- 原子性:一个线程内多行代码以一个整体运行,器间不能有其它线程的代码插队
volatile关键字?
在Java中,
volatile关键字可以保证变量的可见性,声明为volatile的变量,表明它共享且不稳定,每次使用它都到主存中读取。一个线程对其的修改,其它线程都立即可见。有序性:将声明为
volatile的变量进行读写操作时,会通过插入特定的内存屏障,禁止JVM指令重排序。
volatile关键字并不能保证原子性,问题出现在:
- java中的一条指令,翻译成字节码可能是多条
- 多线程运行下,多条指令发生交错的问题
class AddAndSubtract { static volatile int balance = 10; public static add() { // 字节码指令: // getstatic // iconst_5 // iadd // putstatic balance += 5; } public static subtract() { // 字节码指令: // getstatic // iconst_5 // isub // putstatic balance -= 5; } public static void main(String[] args) { CountDownLatch latch = new CountDownLatch(2); new Thread(() -> { add(); latch.countDown(); }).start(); new Thread(() -> { subtract(); latch.countDown(); }).start(); latch.await(); // 结果可能有:10, 5, 15 System.out.println(balance); } }
volatile保证有序性的原理?
volatile修饰变量会对其读/写分别加不同的屏障
- 对
volatile修饰的变量写,写屏障阻止之前的代码重排序到写操作之后- 对
volatile修饰的变量读,读屏障阻止之后的代码重排序到读操作之前结论:写变量时,要把
volatile修饰的变量放在最后写;读变量时放在最前class MemoryFence { int x; volatile int y; // 对volatile修饰的变量写,写屏障阻止之前的代码重排序到写操作之后 public void test1() { x = 1; // ^^^^^^^^ // -------- y = 1; } // 对volatile修饰的变量读,读屏障阻止之后的代码重排序到读操作之前 public void test2(Record r) { r.r1 = y; // -------- // vvvvvvvv r.r2 = x; } class Record { int r1; int r2; } }
Java中的悲观锁与乐观锁?
- 悲观锁的代表是
syncronized和Lock锁
- 核心思想:线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程都需要阻塞等待。
- 缺点:线程从运行到阻塞,再从阻塞到唤醒,涉及线程上下文切换,如果频繁发生,影响性能
- 实际上,线程在获取
synchronized和Lock锁事,如果锁已被占用,都会做几次重试操作,减少阻塞的机会- 乐观锁的代表是
AtomicInteger,使用cas来保证原子性
- 核心思想:无需加锁,每次只有一个线程能成功修改共享变量,其它失败的线程不需要停止,不断重试直至成功
- 由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换
- 需要多核
cpu支持,且线程数不应超过cpu核数- 缺点:
- ABA问题:共享变量中间被其它线程修改过,只是后来又被改回了原值。解决思路:在变量前面追加版本号或者时间戳,只有当变量值和时间戳都相等时,才更新。
- 循环时间长开销大:CAS经常会用到自旋操作来进行重试,如果长时间不成功,会给CPU带来非常大的执行开销。
- 只能保证一个共享变量的原子操作:JDK1.5开始,提供了
AtomicReference类,保证引用对象之间的原子性。可以通过将多个变量封装在一个对象中,使用AtomicReference来执行CAS操作。// 自定义实现 `AtomicInteger` class MyAtomicInteger { // 提供底层的CAS操作 private static final Unsafe U; // 获取value字段的偏移量 private static final long valueOffset; static { U = UnsafeUtil.getUnsafe(); try { valueOffset = U.objectFieldOffset(MyAtomicInteger.class.getDeclaredField("value")); } catch (NoSuchFieldException e) { throw new RuntimeException(e); } } // CAS需要与volatile配合使用,保证变量的可见性 private volatile int value; public int incrementAndGet() { int o, n; for (; ; ) { o = value; n = o + 1; if (U.compareAndSwapInt(this, valueOffset, o, n)) { break; } } return n; // return U.getAndAdd(this, valueOffset, 1) + 1; } public int getAndIncrement() { int o, n; for (; ; ) { o = value; n = o + 1; if (U.compareAndSwapInt(this, valueOffset, o, n)) { break; } } return o; // return U.getAndAdd(this, valueOffset, 1); } public int intValue() { return value; } public static void main(String[] args) throws InterruptedException { MyAtomicInteger i = new MyAtomicInteger(); Thread t1 = new Thread(() -> { for (int j = 0; j < 10000; j++) { i.incrementAndGet(); } }); t1.start(); t1.join(); System.out.println(i.intValue()); } }
Sysnchronized原理
Java对象头(以32位虚拟机为例)
对象头的组成
Mark Word:存储对象自身的运行时数据,如hashcode、gc分代年龄等。为了让一个字大小能存储更多的信息,JVM将字的最低两个位置设置为标记位。Klass Word:存储对象的类型指针,指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例。array length:如果对象是一个数组,那么对象头还需要有额外的空间用于存储数据的长度。
普通对象
|--------------------------------------------------------------|
| Object Header (64 bits) |
|------------------------------------|-------------------------|
| Mark Word (32 bits) | Klass Word (32 bits) |
|------------------------------------|-------------------------|
数组对象
|---------------------------------------------------------------------------------|
| Object Header (96 bits) |
|--------------------------------|-----------------------|------------------------|
| Mark Word(32bits) | Klass Word(32bits) | array length(32bits) |
|--------------------------------|-----------------------|------------------------|
对象不同状态下Mark Word示意图如下:其中数字表示位数
lock:2位的锁状态标记位,由于希望用尽可能少的二进制位表示尽可能多的信息,所以设置了lock标记。该标记的值不同,整个mark word表示的含义不同。biased_lock:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。age:4位的Java对象分代年龄。在GC中,如果对象在Survivor区复制一次,年龄增加1。当对象达到设定的阈值时,将会晋升到老年代。identity_hashcode:25位的对象标识Hash码,采用延迟加载技术。当对象被锁定时,该值会移动到管程Monitor中。thread:持有偏向锁的线程IDepoch:偏向时间戳ptr_to_lock_record:指向栈中锁记录的指针ptr_to_heavyweight_monitor:指向管程Monitor的指针
|-------------------------------------------------------|--------------------|
| Mark Word (32 bits) | State |
|-------------------------------------------------------|--------------------|
| identity_hashcode:25 | age:4 | biased_lock:0 | 01 | Normal |
|-------------------------------------------------------|--------------------|
| thread:23 | epoch:2 | age:4 | biased_lock:1 | 01 | Biased |
|-------------------------------------------------------|--------------------|
| ptr_to_lock_record:30 | 00 | Lightweight Locked |
|-------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:30 | 10 | Heavyweight Locked |
|-------------------------------------------------------|--------------------|
| | 11 | Marked for GC |
|-------------------------------------------------------|--------------------|
biased_lock |
lock |
状态 |
|---|---|---|
| 0 | 01 | 无锁 |
| 1 | 01 | 偏向锁 |
| 0 | 00 | 轻量级锁 |
| 0 | 10 | 重量级锁 |
| 0 | 11 | GC标记 |
Monitor(管程/监视器)
每个Java对象都可以关联一个Monitor对象,如果使用synchronized给对象上锁(重量级)之后,该对象头的Mark Word中就被设置指向Monitor对象的指针。

- 刚开始
Monitor中的Owner为null - 当
Thread-2执行synchronized(obj)就会将Monitor的所有者Owner置为Thread-2,Monitor中只能有一个Owner - 在
Thread-2上锁的过程中,如果Thread-3、Thread-4,Thread-5也来执行synchronized(obj),就会进入EntryList阻塞等待BLOCKED hread-2执行完同步代码块的内容,重置Mark Word,然后唤醒EntryList中等待的线程来竞争,竞争是非公平的- 图中WaitSet中的
Thread-0,Thread-1是之前获得过锁,但条件不满足进入WAITING状态的线程
轻量级锁
轻量级锁使用场景:如果一个对象虽然有多线程访问,但多线程访问的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。如果有竞争,轻量级锁会升级为重量级锁
- 创建锁记录(Lock Record)对象,每个线程的栈帧都会包含一个锁记录的结构,内部可以存储锁定对象的
Mark Word。锁记录包含:对象引用地址(Object reference)、锁记录地址(lock record地址) - 让锁记录中
Object Reference指向锁记录,并尝试用CAS替换Object的Mark Word,将Mark Word的值存入锁记录 - 如果
cas操作替换成功,对象头存储了锁记录地址和状态 00,表示由该线程给对象加锁 - 如果cas失败,有两种情况:
- 如果是其它线程已经持有了该
Object的轻量级锁,这时表明有竞争,进入锁膨胀 - 如果是自己执行了
synchronized锁重入,那么再添加一条Lock Record作为重入的计数
- 如果是其它线程已经持有了该
- 当退出
synchronized代码块(解锁时)如果有取值为null的锁记录,表示有重入,这时重置锁记录,表示重入计数减一 - 当退出
synchronized代码块(解锁时)锁记录的值不为null,这时使用cas将Mark Word的值恢复给对象头- 成功,则解锁成功
- 失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程


static final Object obj = new Object();
public static void method1() {
synchronized (obj) {
// 同步块 A
method2();
}
}
public static void method2() {
synchronized (obj) {
// 同步块 B
}
}锁膨胀
如果在尝试加轻量级锁的过程中,CAS操作无法成功,这时一种情况是有其它线程为此对象加了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
- 当Thread-1进行轻量级加锁时,Thread-0已经对该对象加了轻量级锁
- 这时Thread-1加轻量级锁失败,进入锁膨胀流程
- 即为
Object对象申请Monitor锁,让Object指向重量级锁地址 - 然后自己进入
Monitor的EntryList阻塞BLOCKED 
- 即为
- 当
Thread-0退出同步代码解锁时,使用cas将Mark Word的值恢复给对象头,失败。这时会进入重量级锁解锁流程,即按照Monitor地址找到Monitor对象,设置Owner为null,唤醒EntryList中BLOCKED线程。


自选优化
重量级锁竞争时,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
加锁优先级:偏向锁>轻量级锁>重量级锁
- 当没有发生锁竞争时,即加锁的顺序的交错的,一个线程释放锁后另一个线程才去加锁
- 调用对象的
hashCode()方法会禁用偏向锁,因为偏向锁对象头中存放线程id,没有存放hashCode值的位置了 - 刚开始使用偏向锁
0x101,当有其它线程加锁(偏向线程释放锁后,即没有锁竞争的场景)时,检测到对象头的线程id没有本线程,就会升级为轻量级锁0x00,在栈帧中生成锁记录Lock Record。所释放后对象头0x001标识Normal状态,偏向锁被撤销。当一个对象被多个线程访问时,偏向状态就被禁用 - 调用
wait/notify也会撤销偏向锁,因为该机制只有重量级锁Monitor有
- 调用对象的
- 当发生锁竞争时,都是使用的重量级锁(
Monitor)。即多个线程同时竞争去给同一个对象加锁。 - 偏向锁已经在
JDK18中废弃,偏向锁仅仅在单线程访问同步代码块的场景中可以获得性能收益。如果存在多线程竞争,就需要 撤销偏向锁 ,这个操作的性能开销是比较昂贵的。
synchronized和ReentrantLock有什么区别
- 两者都是可重入锁。线程可以再次获取自己的内部锁
synchronized依赖于JVM而ReentrantLock依赖于APIsynchronized依赖于JVM实现ReentrantLock是JDK层面实现的,需要lock()和unlock()方法配置try/finally语句块完成
ReentrantLock比synchronized增加了一些高级功能- 等待可中断:
ReentrantLock提供了一种中断等待锁的线程的机制,通过lock.lockInterruptibly()可以实现在等待获取锁的过程中,如果有其它线程中断当前线程interrupt(),当前线程就会抛出InterruptedException异常,可以捕获该异常进行相应处理。 - 可实现公平锁:
ReentrantLock通过构造方法可以指定是否是公平锁,synchronized只能是非公平锁。 - 可实现选择性通知(锁可以绑定多个条件):
ReentrantLock类结合Condition接口的newCondition()方法可以实现多条件选择性通知。 - 支持超时:
ReentrantLock提供了tryLock(timeout)的方法,可以指定等待获取锁的最长等待时间,如果超过了等待时间,就会获取锁失败,不会一直等待。
- 等待可中断:
ThreadLocal原理?
ThreadLocal可以实现资源对象的线程隔离,让每个线程各用各的资源对象,避免争用引发的线程安全问题TreadLocal同时实现了线程内的资源共享ThreadLocal原理:每个线程内有一个
ThreadLocalMap类型的成员变量,用来存储资源对象
- 调用
set方法,就是以ThreadLocal自己作为key,资源对象作为value,放入当前线程的ThreadLocalMap集合中- 调用
get方法,就是以ThreadLocal自己作为key,到当前线程中查找关联的资源值- 调用
remove方法,就是以ThreadLocal自己作为key,移除当前线程关联的资源值
ThreadLocalMap是ThreadLocal中的一个静态内部类:
- 以
ThreadLocal作为key,共享数据作为value- 初始容量是
16,扩容因子是2/3,容量始终为2的幂- 当产生哈希冲突时通过开放寻址法,找下一个空闲位置放入
- 索引计算:第一个
key的下标索引是0,以后每次索引加一个固定值0x61c88647,然后通过hash & (len - )获得索引位置。
ThreadLocal内存泄露问题是怎么导致的?
// ThreadLocalMap 中 Entry 的 key 是弱引用,value 是强引用 static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { // key是弱引用:如果ThreadLocal实例不再被任何强引用指向,垃圾回收器会在下次GC时回收该实例,导致ThreadLocalMap中对应的key变为null super(k); // value是强引用:ThreadLocalMap中的value是强引用。即使key被回收(变为null),value仍然存在于ThreadLocalMap中,被强引用,不会被回收 value = v; } }当
ThreadLocal实例失去引用后,其对应的value仍然存在于ThreadLocalMap中,因为Entry对象前引用了它。如果线程持续存在(例如线程池中的线程),ThreadLocalMap也会一直存在,导致key为null的entry无法被垃圾回收,就会造成内存泄露如何避免内存泄露的发生?
- 在使用完
ThreadLocal后,务必调用remove()方法。remove()方法会从ThreadLocalMap中显式地移除对应地entry,彻底解决内存泄露地风险。- 在线程池等线程复用的场景下,使用
try-finally块可以确保即使发生异常,remove()方法也一定会被执行。
ThreadLocalMap中的value的释放时机?
- 当其它地方不再强引用
ThreadLocal时,因为ThreadLocalMap中作为key的ThreadLocal是弱引用,下次垃圾回收GC时就会被清除null。但是其对应的value是强引用,释放时机有:
- 下次获取
key时发现null的keyset的key时,会使用启发式扫描,清除临近null的key,启发次数与元素个数,是否发现null的key有关- 一般使用
ThreadLocal时都是使用静态变量private static final ThreadLocal<?> tl = new ThreadLocal<>();,静态变量一直对它保持强引用
remove时(推荐),因为一般使用ThreadLocal时都是把它作为静态变量,因此GC无法回收
线程池
线程池就是管理一系列线程地资源池。当有任务要处理时,直接从线程池中获取线程来处理,处理完成之后线程并不会立即销毁,而是等待下一个任务。线程池的好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗
- 提高响应速度。当任务达到时,任务可以不需要等待线程创建就能立即执行
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
如何创建线程池?
- 通过
ThreadPoolExecutor构造函数来创建(推荐)- 通过
Executor框架的工具类Executors来创建。(不建议使用)
FixedThreadPool:固定线程数量的线程池。SingleThreadExecutor:只有一个线程的线程池。
- 前两个使用的是有界阻塞队列是
LinkedBlockingQueue,其任务队列的最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOMCachedThreadPool:可根据实际情况调整线程数量的线程池。
- 使用的是同步队列
SynchronousQueue,允许创建的线程数量为Integer.MAX_VALUE,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致OOMScheduledThreadPool:给定的延迟后运行任务或者定期执行任务的线程池。
- 使用的无界的延迟阻塞队列
DelayWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM// 有界队列 LinkedBlockingQueue public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()); } // 无界队列 LinkedBlockingQueue public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())); } // 同步队列 SynchronousQueue,没有容量,最大线程数是 Integer.MAX_VALUE` public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>()); } // DelayedWorkQueue(延迟阻塞队列) public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
线程池常见参数有哪些?
public ThreadPoolExecutor(
int corePoolSize, // 线程池的核心线程数量
int maximumPoolSize, // 线程池的最大线程数
long keepAliveTime, // 当线程数大于核心线程数时,多余空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列,用来存储等待执行任务的队列
ThreadFactory threadFactory, // 线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler // 拒绝策略,当提交的任务过多而不能及时处理时,可以定制策略来处理任务
) {
}
ThreadPoolExecutor的重要参数:
corePoolSize:任务队列未达到队列容量时,最大可以同时运行的线程数量maximumPoolSize:任务队列中存放的任务达到队列容量时,当前可以同时运行的线程数量变为最大线程数workQueue:新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor其它常见参数:
keepAliveTime:当线程池中的线程数量大于corePoolSize,即有非核心线程时,这些非核心线程空闲后不会立即摧毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁unit:keepAliveTime参数的时间单位threadFactory:executor创建新线程时会用到。线程工厂,可以为线程创建时起个名字handler:决绝策略
线程池的拒绝策略有哪些
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolExecutor定义一些策略:

ThreadPoolExecutor.AbortPolicy:抛出RejectedExecutionException来拒绝新任务的处理。(默认)ThreadPoolExecutor.CallerRunsPolicy:调用执行者自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被决绝的任务,如果执行程序已关闭,则丢弃该任务。ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃。ThreadPoolExecutor.DiscardOldestPolicy:此策略就丢弃最早的未处理的任务请求。

线程池的execute()和submit()方法的区别?
使用
execute()提交任务:任务执行过程中出现异常,会导致当前线程终止,并且异常会被打印到控制台或日志文件中。线程池会检测到这个线程终止,并创建一个新线程来替换它,从而保持配置的线程数不变。使用
submit()提交任务:如果在任务执行中发生异常,这个异常不会直接打印出来。异常会被封装在由submit()返回的Future对象中。当调用Future.get()方法时,可以捕获一个ExecutionException。这种情况下,线程不会因为异常而终止,它会继续存在于线程池中,准备执行后续的任务。
如何给线程池命名?
默认情况下创建的线程名字类似
pool-1-thread-n这样的,没有业务含义,不利于我们定位问题。
利用
guava的ThreadFactoryBuilderThreadFactory threadFactory = new ThreadFactoryBuilder() .setNameFormat(threadNamePrefix + "-%d") .setDaemon(true).build(); ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory);自己实现ThreadFactorty
ExecutorService pool = new ThreadPoolExecutor( 5, 5, 0L, TimeUnit.SECOND, new LinkedBlockingQueue<Runnable>(), new ThreadFactory() { private final AtomicInteger threadNumber = new AtomicInteger(1); @Override public Thread newTread(@NotNull Runnable r) { Thread t = new Thread(r); t.setName(name + "[#" + threadNumber.getAndIncrement() + "]"); return t; } } );
如何设定线程池的大小?
- CPU密集型任务(
N+1):这种任务消耗的主要是CPU资源,可以将线程设置为N(CPU核心数)+ 1。- IO密集型任务(
2N):这种任务会用大部分的时间来处理I/O交互,而线程在处理I/O的时间段内不会占用CPU来处理,这时就可以将CPU交给其它线程使用。因此在I/O密集型任务的引用中,可以多配置一些线程,具体的计算方法是2N。
AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架
特点:
- 用
state属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁getState-获取状态setState-设置状态compareAndSetState-cas机制设置状态- 独占模式是只有一个线程能够访问资源,而共享模式可以允许多个线程访问资源
- 提供了基于
FIFO的等待队列,类似于Monitor的EntryList - 条件变量来实现等待、唤醒机制,支持多个条件变量,类似于
Monitor的WaitSet
子类主要实现一些方法(默认抛出UnsupportedOperationException)
tryAcquiretryReleasetryAcquireSharedtryReleaseSharedisHeldExclusively
/**
* Sync object for non-fair locks
*/
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
final boolean initialTryLock() {
Thread current = Thread.currentThread();
// 非公平锁,新线程直接尝试获取锁,不会管CLH队列中是否有之前阻塞的线程
if (compareAndSetState(0, 1)) { // first attempt is unguarded
setExclusiveOwnerThread(current);
return true;
} else if (getExclusiveOwnerThread() == current) {
int c = getState() + 1;
if (c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
} else
return false;
}
/**
* Acquire for non-reentrant cases after initialTryLock prescreen
*/
protected final boolean tryAcquire(int acquires) {
if (getState() == 0 && compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
}
/**
* Sync object for fair locks
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
/**
* Acquires only if reentrant or queue is empty.
*/
final boolean initialTryLock() {
Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 公平锁,队列中有其它线程会退出,即返回false
if (!hasQueuedThreads() && compareAndSetState(0, 1)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (getExclusiveOwnerThread() == current) {
if (++c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
}
return false;
}
/**
* Acquires only if thread is first waiter or empty
*/
protected final boolean tryAcquire(int acquires) {
if (getState() == 0 && !hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
}每个条件变量其实就对应着一个等待队列,其实现类是ConditionObject
当读操作远远高于写操作,这时候使用读写锁让读-读可以并发,提高性能。读写、写写互斥
读写锁用的是同一个Sync同步器,因此等待队列,state等也是同一个。
因为state是读锁和写锁共用的,写锁状态占低16位,读锁使用高16位
// 写锁
@ReservedStackAccess
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// c != 0 有可能加写锁,有可能是读锁
// c != 0 && w == 0 说明加的是读锁
// c != 0 && w != 0 看已经加的写锁是否是当前线程加的
if (w == 0 || current != getExclusiveOwnerThread())
return false;
// 超过 65535 (16位二进制最大值)
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 可重入
setState(c + acquires);
return true;
}
// writerShouldBlock()
// 公平锁,会检查阻塞队列中是否有其它线程阻塞
// 非公平锁,直接返回false,然后直接执行 compareAndSetState 尝试加锁
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}@ReservedStackAccess
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
Thread current = Thread.currentThread();
int c = getState();
// 是否加了写锁 && 写锁是否是当前线程持有
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
// 读锁状态
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}// 释放写锁
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
// 从头结点开始唤醒CLH队列中阻塞的节点
signalNext(head);
return true;
}
return false;
}
/*
* Note that tryRelease and tryAcquire can be called by
* Conditions. So it is possible that their arguments contain
* both read and write holds that are all released during a
* condition wait and re-established in tryAcquire.
*/
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}
/**
* 唤醒后继节点
* Wakes up the successor of given node, if one exists, and unsets its
* WAITING status to avoid park race. This may fail to wake up an
* eligible thread when one or more have been cancelled, but
* cancelAcquire ensures liveness.
*/
private static void signalNext(Node h) {
Node s;
if (h != null && (s = h.next) != null && s.status != 0) {
s.getAndUnsetStatus(WAITING);
LockSupport.unpark(s.waiter);
}
}虚拟机栈和本地方法栈为什么是私有的?
- 虚拟机栈:每个Java方法在执行之前会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至方法完成的过程,就对应着一个栈帧在Java虚拟机栈中入栈和出栈的过程。
- 本地方法栈:和虚拟机栈发挥着类似的作用,区别是是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机栈使用到的
Nativa方法服务。为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的。
一句话简单介绍堆和方法区?
堆和方法区是所有线程共享的资源。
- 堆是进程中最大的一块内存,主要用于存放新创建的对象
- 方法区主要用于存放已被加载的类信息、常量、静态变量、即使编译器编译后的代码等。
类加载的过程包括了加载、连接(验证、准备、解析)、初始化五个阶段。
-
加载:检查并加载类的二进制数据。
- 通过一个类的全限定名来获取其定义的二进制字节流
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在Java堆中生成一个代表该类的
java.lang.Class对象,作为方法区中这些数据的访问入口 - 加载是懒惰进行
-
链接
-
验证:确保被加载的类的正确性。
-
准备:为类的静态变量分配内存,并将其初始化为默认值。
- 初始值通常情况下是数据类型默认的零值(如
0、0L、null、false等) - 数据初始化时没有对数组的各元素赋值,那么其中的元素将根据对应的数据类型而被赋予默认的零值
static final类型变量,如果初始化值是编译时常量,则在准备阶段完成赋值,如public static final int x = 10;。如果值需要在运行时计算(如public static final int x = someMethod();),则在初始化阶段赋值。
- 初始值通常情况下是数据类型默认的零值(如
-
解析:把类中的符号引用转换为直接引用。
-
-
初始化:执行类的静态代码块(
static {})和静态变量的显式初始化。- 初始化是懒惰执行,满足条件有:
main方法所在类- 首次访问静态方法或静态变量(非final)
- 子类初始化,导致父类初始化
Class.forName(类名, true, loader)或者Class.forName(类名)new,clone,反序列化
- 初始化是懒惰执行,满足条件有:
类初始化时机?
- 创建类的实例,
new Object()时- 访问类的某个静态变量或者静态方法
- 初始化某个类的字类时,其父类也会被初始化
- 使用反射加载类
Class.forName("java.util.ArrayList");
Java对象的创建过程Cat cat = new Cat();?
- 类加载检查。JVM首先会检查该类是否已经被加载、连接和初始化。
- 分配内存。分配的内存大小在类加载完成后就可以确定(由类的元数据确定)
- 初始化零值。为对象的实例变量初始化零值(0、null、false等)
- 设置对象头。对象头(Object Header)包括
Mark Word存储对象的运行时数据(哈希码、锁状态、GC分代年龄等)、Klass Pointer存储类的元数据(Class对象),用于确定对象的类型。- 执行实例初始化代码。
- 实例变量初始化
int x = 10;- 实例初始化块
{}- 构造函数
Constructor- 返回对象引用
双亲委派机制:优先委派上级类加载器进行加载,如果上级类加载器
- 能找到这个类,由上级加载,加载后该类也对下级类加载器可见
- 找不到这个类,则下级类加载器才有资格执行加载,下级加载的类 上级不可见
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
Bootstrap ClasssLoader |
JAVA_HOME/jre/lib |
无法直接访问 |
Extension ClassLoader |
JAVA_HOME/jre/lib/ext |
上级为 Bootstrap,显示为null |
Application ClassLoader |
classpath |
上级为 Extension |
| 自定义类加载器 | 自定以 | 上级为 Application |
JVM中内置了三个重要的ClassLoader:
BootstrapClassLoader(启动类加载器):最顶层的加载类,由C++实现,通常表示为null,没有父级,主要用来加载JDK内部的核心类库(%JAVA_HOME%/lib)以及被-Xbootclasspath参数指定的路径下的所有类。ExtentionClassLoader(扩展类加载器):主要负责加载%JAVA_HOME%/lib/ext目录下的jar包和类以及被java.ext.dirs系统变量所指定的路径下的所有类。AppClassLoader(应用程序类加载器):面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
ClassLoader类有两个关键的方法:
protected Class loadClass(String name, boolean resolve):加载指定二进制名称的类,实现双亲委派机制。name为类的二进制名称,resolve如果为true,在加载时调用resolveClass(Class<?> c)方法解析该类。protected Class findClass(String name):根据类的二进制名称查看类,默认实现是空方法。
双亲委派机制的执行流程:
- 在类加载时,系统首先会判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。
- 在进行类加载时,类加载器首先不会自己尝试加载该类,而是把请求委派给父类加载其去完成(调用父类的
loadClass()方法)。这样的话,所有的请求最终都会传送到顶层的启动类加载器BoostrapClassLoader中 - 只有当父类加载器无法完成加载请求(搜索范围中没有找到所需的类时),字类加载器才会尝试自己去加载(调用自己的
findClass()方法来加载类) - 如果字类加载器也无法加载该类,就会排除一个
ClassNotFoundException异常
JVM 判定两个 Java 类是否相同的具体规则:JVM 不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即使两个类来源于同一个
Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相同。
双亲委派机制的好处:
- 让上级类加载器中的类对下级共享(反之不行),即能让你的类能依赖到jdk提供的核心类
- 让类的加载有优先次序,保证核心类优先加载。
- 保证了Java程序的稳定运行,可以避免类的重复加载,也保证了Java的核心API不被篡改。
// ClassLoader 中的 loadClass 方法定义了 双亲委派机制 逻辑
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查该类是否已经加载过了
Class<?> c = findLoadedClass(name);
if (c == null) {
// 如果 c == null ,说明该类没有被加载过
long t0 = System.nanoTime();
try {
if (parent != null) {
// 当父类加载器不为null时,通过父类的loadClass来加载该类
c = parent.loadClass(name, false);
} else {
// 当父类加载器为null时,则调用启动类加载器来加载该类
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 非空父类的加载器无法找到对应的类,则抛出异常
}
if (c == null) {
// 当父类加载器无法加载时,则调用findClass方法来加载该类
// 用户可通过重写该方法,来自定义类加载器
long t1 = System.nanoTime();
c = findClass(name);
// 用于统计类加载器相关的信息
PerfCounter.getParentDelegationTime().addTime(t1 - t0);
PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
// 对类进行link操作
resolveClass(c);
}
return c;
}
}不能。类加载器在加载类的时候会检测类的全路径名,如果是java.* class即全路径以java开头都会抛出安全异常?
private ProtectionDomain preDefineClass(String name,
ProtectionDomain pd)
{
if (!checkName(name))
throw new NoClassDefFoundError("IllegalName: " + name);
// Note: Checking logic in java.lang.invoke.MemberName.checkForTypeAlias
// relies on the fact that spoofing is impossible if a class has a name
// of the form "java.*"
if ((name != null) && name.startsWith("java.")
&& this != getBuiltinPlatformClassLoader()) {
throw new SecurityException
("Prohibited package name: " +
name.substring(0, name.lastIndexOf('.')));
}
if (pd == null) {
pd = defaultDomain;
}
if (name != null) {
checkCerts(name, pd.getCodeSource());
}
return pd;
}堆内存(Heap Memory)是JVM管理的最大一块内存区域,用于存储所有对象示例和数组。它是线程共享的,由垃圾收回器(GC)自动管理,是Java内存模型的核心部分。
栈内存(Stack Memory)是线程私有的运行时内存区域,用于存储方法调用,局部变量和部分对象引用。每个线程在创建时都会分配一个独立的栈内存,其声明周期与线程相同。
- 解释器(Interpreter):将java字节码翻译成机器码
- 即时编译器(JIT Compiler):负责发现热点代码,将热点代码的机器码缓存下来,下次遇到后直接交给cpu执行
- 垃圾回收(GC):
不会出现内存溢出的区域:程序计数器
出现OutOfMemoryError的情况:
- 堆内存耗尽——对象越来越多,又一直在使用,不能被垃圾回收
- 方法区内存耗尽——加载的类越来越多,很多框架都在运行期间动态产生新的类
- 虚拟机栈累积——每个线程最多会占用
1M内存,线程个数越来越多,而又长时间运行不销毁时
出现StackOverflowError的情况:
- 虚拟机栈内部——方法调用次数过多,导致该线程占用内存超过
1M
- 方法区是JVM规范中定义的一块内存区域,用来存储类元数据、方法字节码、即时编译器需要的信息等
- 永久代是
HotSpot虚拟机对JVM规范的实现(1.8之前) - 元空间是
HotSpot虚拟机对JVM规范的实现(1.8之后),使用本地内存作为这些信息的存储空间
类的元数据信息在类加载时放入到方法区,并在堆中生成Class<?>对象作为访问类信息的入口。当该类的所有对象、Class<?>和加载该类的类加载器都被回收时,元空间中的类元数据才会被释放掉。
-Xmx:Java虚拟机最大内存-Xms:Java虚拟机最小内存,包括新生代和老年代-Xmn:Java虚拟机新生代内存-XX:SurvivorRatio=3:新生代中eden和from的内存比例-Xss:每个线程占用内存,linux默认1M
按比例设置:

按大小设置:

元空间内存参数:

加标记的对象,不能被清除。通过可达性分析,沿着根对象GC Root的引用链能找到,则不能被回收。
- 标记清除:会产生内存碎片(CMS垃圾回收器)
- 标记整理:相比于标记清除,多了一步整理阶段,将对象往一段移动,不会产生内存碎片,但是效率降低。常用于老年代,存活对象多
- 标记复制:将内存分为两部分
from和to,将存活的对象复制到TO,因此需要额外空闲内存。经常用于新生代的垃圾回收(假设新生代存活对象很少)



GC的目的是在于实现无用对象自动释放,减少内存碎片,加快分配速度
GC要点
- 回收的区域是堆内存,不包括虚拟机栈,在方法调用结束会自动释放方法占用内存
- 判断无用对象,使用可达性分析,三色标记存活对象,回收未标记对象
- GC具体的实现称为垃圾回收器
- GC大多采用了分代回收思想,理论依据是大部分对象朝生夕灭,用完立刻就可以税后,另外少部分对象会长时间存活,每次很难回收,根据这两类对象的特性将垃圾回收区域分为新生代和老年代,不同区域应用不同的回收策略。
- 根据GC的规模可以分成Minor GC, Mixed GC, Full GC
分代回收与GC规模
- 伊甸园
eden,最初对象都分配在这里,与幸存区合成新生代 - 幸存区
Survivor:当eden内存不足时,回收后的幸存对象到这里,分成from和to,采用标记复制算法eden和from幸存的对象会被复制到to,然后清空eden和from区域内存- 然后交换
from和to
- 老年代
old:当幸存区对象熬过几次回收(最多15次),晋升到老年代(幸存区内存不足或大对象会导致提前晋升)
GC规模:
Minor GC发生在新生代的垃圾回收,暂停时间短Mixed GC新生代+老年代部分区域的垃圾回收,G1收集器特有Full GC:新生代+老年代完整垃圾回收,暂停时间长,应尽力避免
用三种颜色记录对象的标记状态:
- 黑色——已标记
- 灰色——标记中
- 白色——还未标记
漏标问题——记录标记过程中变化
incremental update- 只要赋值发生,被赋值的对象就会被记录
Snapshot At The Beginning, SATB- 新加对象会被记录
- 被删除引用关系的对象也被记录
Parallel GC
eden内存不足发生Minor GC,标记复制 STWold内存不足发生Full GC,标记整理 STW- 注重吞吐量
ConcurrentMarkSweep GC
old并发标记,重新标记时需要STW,并发清除Failback Full GC:- 注重响应时间
G1 GC
- 兼顾响应时间和吞吐量
- 划分成多个区域,每个区域都可以充当
eden、survivor、old、humongous - 新生代回收:eden内存不足,标记复制 STW
- 并发标记:old并发标记,重新标记时需要 STW
- 混合收集:并发标记完成,开始混合收集,参与复制的有eden,survivor,old,其中old会根据暂停时间目标,选择部分回收价值高的区域,复制时 STW
Failback Full GC
- 误用线程池导致的内存溢出
情景一:使用固定大小的线程池
public class TestOomThreadPool {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
while (true) {
executor.submit(() -> {
try {
Thread.sleep(50); // 模拟发送延迟
System.out.println("send sms..."); // 模拟发送短信
} catch (InterruptedExeception e) {
e.printStackTrace();
}
});
}
}
}// 因为 Executors.newFixedThreadPool 底层使用无界队列,任务堆积可能导致内存溢出
// 建议:使用 new ThreadPoolExecutor() 自定义线程池,使用固定大小的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
// 使用无界队列(最大值Integer.MAX_VALUE)
new LinkedBlockingQueue<Runnable>());
}情景二:使用带缓冲的线程池
// 无法控制创建线程的数量,因为线程创建太多,导致 OutOfMemoryError
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>());
}-
查询数据量太大导致的内存溢出
-
动态生成类导致的内存溢出

- 强引用
- 普通变量赋值即为强引用,如
A a = new A(); - 通过
GC Root的引用链,如果强引用不到该对象,该对象才能被回收
- 普通变量赋值即为强引用,如
- 软引用(SoftReference)
- 例如:
SoftReference a = new SoftReference(new A()); - 如果仅有软引用该对象时,首次垃圾回收不会回收该对象,如果内存仍不足,再次回收时才会释放对象
- 软引用自身需要配合引用队列来释放
- 典型例子:反射数据
- 例如:
- 弱引用(WeakRefernce)
- 例如:
WeakRefernce a = new WeakReference(new A()); - 如果仅有弱引用引用该对象时,只要发生垃圾回收,就会释放该对象
- 弱引用自身需要配合引用队列来释放
- 典型例子:
ThreadLocalMap中的Entry对象
- 例如:
- 虚引用(PhantomReference)
- 例如:
PhantomReference a = new PhantomReference(new A()); - 必须配合引用队列一起使用,当虚引用引用的对象被回收时,会将虚引用对象入队,由
Reference Handler线程释放其关联的外部资源 - 典型例子:
Cleaner释放DirectByteBuffer占用的直接内存。java对象被收回后,释放其占用的外部资源
- 例如:

finalize是Object中的一个方法,子类重写它,垃圾回收时此方法会被调用,可以在其中进行一些资源释放和请理工作- 但是,将资源释放和请理动作放在
finalize方法中不好,非常影响性能,严重时甚至会引起OOM,从Java9开始就被标注为@Deprecated,不建议被使用
unfinalized队列- 当重写了
finalize方法的对象,在构造方法调用之时,JVM都会将其包装成一个Finalizer对象,并加入unfinalized队列中(静态成员变量、双向链表结构)
- 当重写了
ReferenceQueue队列- 第二个重要的队列,也是
Finalizer类中一个静态成员变量,名为queue(是一个单向链表结构),刚开始是空的。当A对象可以被当作垃圾回收时,就会把这些A对象对应的Finalizer对象加入到这个队列。
- 第二个重要的队列,也是
重写
finalize()方法的对象在没人引用,垃圾回收时也无法立刻回收它,因为Finalizer还在引用它,为的是在执行完finalize()方法后再回收。
- 底层是由一个叫做
Finalier的守护线程调用的finalize方法。当所有非守护线程都结束时,守护线程也会结束,因此不能保证finalize一定被调用。 - 如果
finalize()方法中出现异常,是不会输出的。因为底层源码catch(Throwable e) {}对任何异常都不做处理 - 垃圾回收时不会利用调用
finalize方法,先把对象加入到ReferenceQueue,然后由Finazlier线程一个一个取出调用

refresh的12个步骤
prepareRefreshobtainFreshBeanFactoryprepareBeanFactory
创建和准备了
Environment对象
- 管理各种键值对信息
systemPropertiessystemEnvironment- 自定义
Properties
总结
BeanFactory的作用是负责bean的创建、依赖注入和初始化BeanDefinition作为bean的设计蓝图,规定了bean的特征,如单例多例、依赖关系、初始销毁方法等BeanDefinition的来源多种多样,可以通过xml获得,通过配置类获得、通过组件扫描获得,也可以是变成添加
总结:
Spring是如何解决循环依赖的?
循环依赖问题在Spring中主要有三种情况:
- 通过构造方法进行依赖注入时产生循环依赖问题
- 通过setter方法进行依赖注入且是在多例(原型)模式下产生的循环依赖问题
- 通过setter方法进行依赖注入且是在单例模式下产生的循环依赖问题
Spring通过三级缓存只解决了第三种循环依赖问题。
三级缓存指的是Spring在创建Bean的过程中,通过三级缓存来缓存正在创建的Bean,以及已经完成的Bean实例。
从多张表中查询。在多表查询时,需要消除笛卡尔积的影响。通过表之间的共同字段(如select * from emp, dept where emp.dept_id = dept.id;),值为null的字段值,不会查询到。多表查询分类:
- 连接查询
- 内连接:相当于A、B交集部分数据
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
- 子查询
隐式内连接:select ... from t1, t2 where ...;
select emp.name, dept.name from emp, dept where emp.dept_id = dept.id;
显式内连接:select .. from t1 inner join t2 on ...;
select emp.name, dept.name from emp inner join dept on emp.dept_id = dept.id;
左外连接:相当于查询表1(左表)的所有数据,包含表1和表2交集部分的数据
select ... from t1 left join t2 on ...;select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
右外连接:相当于查询表2(右表)的所有数据,包含表1和表2交集部分的数据
select ... from t1 right join t2 on ...;select d.*, e.* from emp e right outer join dept d on e.dept_id = dept.id;
自连接可以是内连接(查询交集部分数据),也可以是外连接(查询左/右表所有数据)
使用自连接时一定要给表起别名
查询员工及其所有领导的信息
select e1.name, e2.name from emp e1, emp e2 where e1.manager_id = e2.id;
查询所有员工 emp 及其领导的名字 emp,如果员工没有领导,也需要查询出来
- 表结构:emp a, emp b
select a.name '员工', b.name '领导' from emp a left join emp b on a.manager_id = b.id;
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all会将全部的数据直接合并在一起,union会对合并之后的数据去重。
SELECT ... FROM table1, ...
UNION [ALL]
SELECT ... FROM table2, ...;- 概念:SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t1);- 子查询外部的语句可以是INSERT、UPDATE、DELETE、SELECT中的任何一个
- 根据子查询结果不同,分为:
- 标量子查询(子查询结果为单个值,单行单列)
- 列子查询(子查询结果为一列)
NOT IN,INANY,ALL,SOME,后面跟上子查询结果- 查询比财务部所有员工工资都高的员工信息:
select * from emp where salary > all (select salary from emp where (select id from dept where name = '财务部'));
- 行子查询(子查询结果为一行)
- 查询与张无忌薪资和直属领导相同的员工信息:
select * from emp where (salary, manager_id) = (select salary, manager_id from emp where name = '张无忌');
- 查询与张无忌薪资和直属领导相同的员工信息:
- 表子查询(子查询结果为多行多列)
select * from emp where (job, salary) in (select job, salary from emp where name = 'a' or name = 'b');
- 根据子查询位置,分为WHERE之后、FROM之后、SELECT之后
select * from product where id = 1;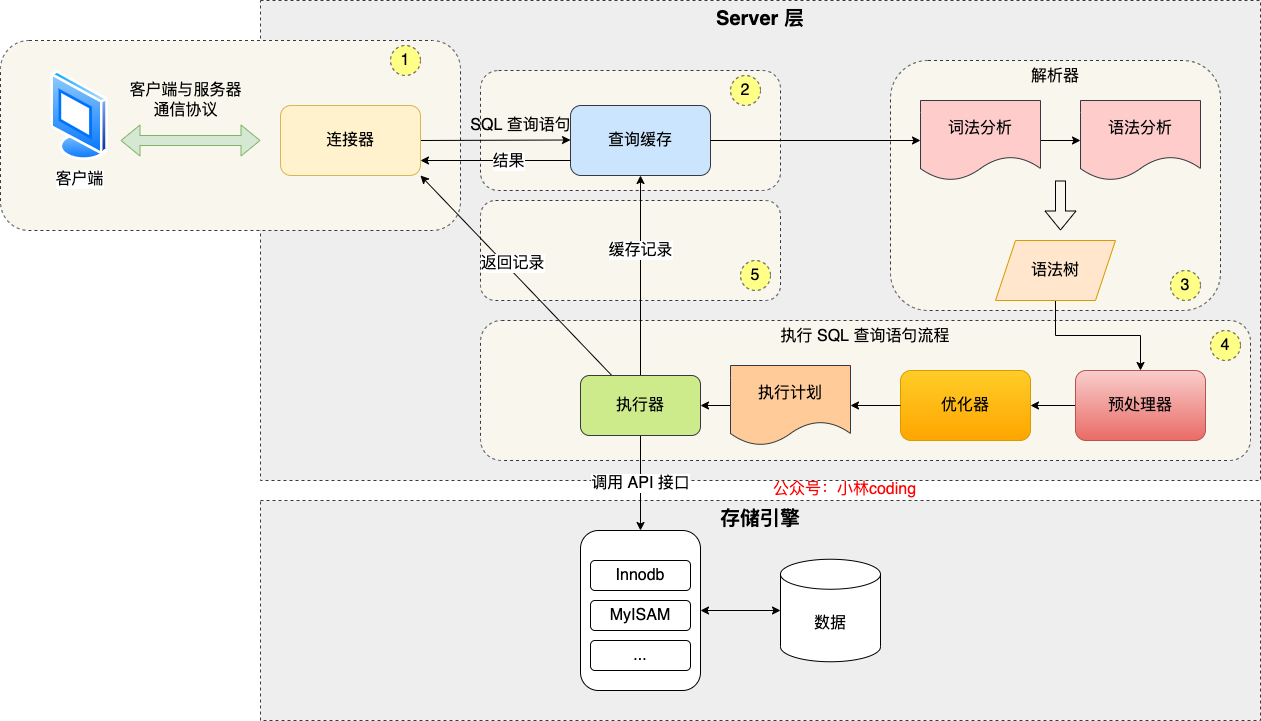
MySQL的架构共分为两层:Server层和存储引擎层
- Server层负责建立连接、分析和执行SQL。
- **存储引擎层负责数据的存储和提取。**从 MySQL 5.5 版本开始, InnoDB 成为了 MySQL 的默认存储引擎。nnoDB 支持索引类型是 B+树
执行一条SQL查询语句,期间发生了什么?
- 连接器。建立连接、管理连接、校验用户身份
- 查询缓存。c哈寻语句如果命中查询缓存则直接返回,否则继续往下执行。MYSQL8.0已删除该模块
- 解析器。t过解析器对SQL查询语句进行词法解析、语法解析,然后构建语法树,方便后续模块读取表名、字段、语句类型
- 执行SQL:执行SQL共有三个阶段
- 预处理阶段:检查表或字段是否存在;将
select *中的*符号扩展为表上的所有列- 优化阶段:基于查询成本的考虑,选择查询成本最小的执行计划
- 执行阶段:根据执行计划执行SQL查询语句,从存储引擎读取记录,返回给客户端。
- **与MYSQL服务端建立连接。**连接的过程需要先经过TCP三次握手,因为MYSQL是基于TCP协议进行传输的。
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错。
- 获取用户的权限,保存起来,后续该用户在此连接里的任何操作,都会基于连接开始时读到的权限进行权限逻辑的判断
查看MYSQL服务被多少个客户端连接了
show processlist;空闲连接会一致占用着吗?
- MYSQL定义了空闲连接的最大空闲时长,由
wait_timeout参数控制,默认值是8小时(28880秒),如果空闲连接超过了这个时间,连接器就会自动将它断开show variables like 'wait_timeout';- 手动断开空闲连接:
kill connection +6MYSQL的连接数有限制吗?
- MYSQL服务支持的最大连接数由
max_connections参数控制,MYSQL服务器默认是151个连接,超过这个值,系统会拒绝接下来的连接请求,并报错提示'Too math connections'show variables like 'max_connections'怎么解决长连接占用内存的问题?
- 定期断开长连接。
- 客户端主动重置连接。
连接器的工作的完成后,客户端就可以向MYSQL服务发送SQL语句,MYSQL服务收到SQL语句后,就会解析出SQL语句的第一个字段,看看是什么类型的语句。
如果是查询语句(select语句),MYSQL就会先去查询缓存(Query Cache)里查找缓存数据,看看之前有没有执行过这一条命令。查询缓存是以key-value形式保存在内存中的,key是SQL查询语句,value为SQL语句查询的结果。
如果查询的语句命中查询缓存,那么就会直接返回value给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执行,等执行完成,查询结果就会被放入查询缓存中。
如果一个表有更新操作,那么这个表的查询缓存就会被清空。如果刚缓存了一个查询结果很大的数据,还没有被使用的时候,刚好这个表有更新操作,查询缓存就被清空了,相当于缓存了个寂寞。
MYSQL8.0版本直接将查询缓存删除掉了
查询缓存是server层的,也就是MYSQL8.0版本移除了server层的查询缓存,并不是innodb存储引擎中的buffer pool
在正式执行SQL查询语句之前,MYSQL会对SQL语句做解析,这个工作由解析器完成
词法解析:MYSQL根据输入的字符串识别出关键字出来
语法解析:
- 根据词法解析的结果,语法解析器会根据语法规则,判断输入的SQL语句是否满足MySQL语法。
- 如果没有问题就会构建SQL语法树,方便后面模型获取SQL类型、表名、字段名、where条件等等。
经过解析器后,接着就要进行执行SQL查询语句的流程了,每条SELECT查询语句流程主要可以分为下面三个阶段:
- prepare阶段,预处理阶段
- optimize阶段:优化阶段
- execute阶段:执行阶段
预处理器:
- 检查SQL查询语句中的表或者字段是否存在
- 将
select *中*符号,扩展为表上的所有列优化器:经过预处阶段后,还需要为SQL查询语句先执行一个执行计划,由优化器来完成
- 优化器主要负责将SQL查询语句的执行方案确定下来。比如在表里面有多个索引的时候,优化器会基于查询程本的考虑,来决定选择使用哪个索引。
- 在查询语句最前面加个
explain命令,输出SQL语句的执行计划。
select id from product where id > 1 and name like 'i%';- 该查询语句的结果既可以使用主键索引,也可以使用普通索引,但执行的效率会不同
- 由于这条查询语句是覆盖索引,即可以直接在二级索引就能查找到结果,就没必要在主键索引查找。
**执行器:**在执行的过程中,执行器就会和存储引擎交互,交互是以记录为单位的。
- 主键索引查询
- 全表扫描
- 索引下推
select * from product where id = 1;
select * from product where name = 'iphone';
减少二级索引在查询时的回表操作,提高查询的效率,因为它将Server层部分负责的事情,交给存储引擎层去处理了
MySQL的NULL值是怎么存放的?
- MySQL的Compact行格式会用NULL值列表来标记值为NULL的列,NULL值并不会存储在行格式中的真实数据部分
- NULL值列表会占用1字节空间,当表中所有字段都定义成NOT NULL,行格式就不会有NULL值列表,可以节省1字节的空间
MYSQL怎么知道
varchar(n)实际占用数据的大小?
- MYSQL的Compact行格式会用变长字段长度列表存储变长字段实际占用的数据大小
varchar(n)中n最大取值为多少?
- 一行记录最大能存储35535字节,包含变长字段字节数列表和NULL值列表所占字节数
- 只有一个varchar(n)字段,且允许为NULL:65535-2-1=65532
- 多字段:所有字段长度+变长字段字节数列表+NULL值列表 <= 65535
行溢出后,MySQL是怎么处理的?
- 如果一个数据页存不了一条记录,InnoDB存储引擎会自动将溢出的数据存放到数据页中。
- Compact行格式:当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在溢出页中,然后在真实数据处使用20字节存储指向溢出页的地址,从而可以找到剩余数据所在页
Compressed和Dynamic这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储20字节的指针来指向溢出页,而实际的数据都存储在溢出页中
查看Mysql数据库的文件存放在哪个目录?
show variables like 'datadir';- 每创建一个数据库,都会在
/var/lib/mysql/目录里面创建一个以数据库为名的目录,然后保存表结构和表数据的文件都会存放在这个目录里 D:\MySQL\mysql-5.7.19-winx64\data下的数据\coding_mysql:db.opt:存储当前数据库的默认字符集和字符校验规则tb_product.frm:保存每个表的元数据信息,主要包含表结构定义tb_product.idb:保存表数据。表数据既可以存在共享表空间文件(文件名:ibdata1),也可以存放在独占表空间文件(文件名:表名字.idb)。这个行为由参数innodb_file_per_table控制的,若设置了参数innodb_per_table=1,则会将存储的数据、索引等信息单独存放在一个独占表空间。
表空间(TableSpace)由段(Segment)、区(extent)、页(page)、行(row)组成,InnoDB存储引擎的逻辑存储结构大致如下图:
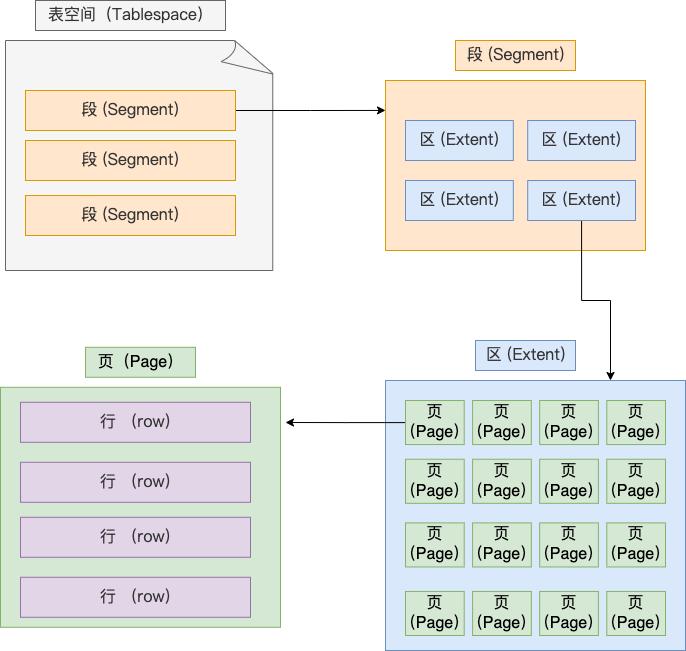
1 行(row)
数据库表中的记录都是按行(row)进行存放的,每行记录根据不同的行格式,有不同的存储结构
2 页(page)
InnoDB的数据是按页为单位来读写的,即当需要读取一条记录的时候,并不是将这个行记录从磁盘读出来,而是以页为单位,将其整体读入内存。
默认每个页的大小是16KB,也就是最多能保证16KB的连续存储空间。
3 区(extent)
在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为1MB,对于16KB的页来说,连续的64个页会被划为一个区,这样就使得链表中相邻的页的屋里位置也相邻,就能使用顺序I/O了。
4 段(Segment)
表空间是由各个段(segment)组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段。
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合
行格式(row format),就是一条记录的存储结构。
- Redundant
- Compact
- Dynamic和Compressed
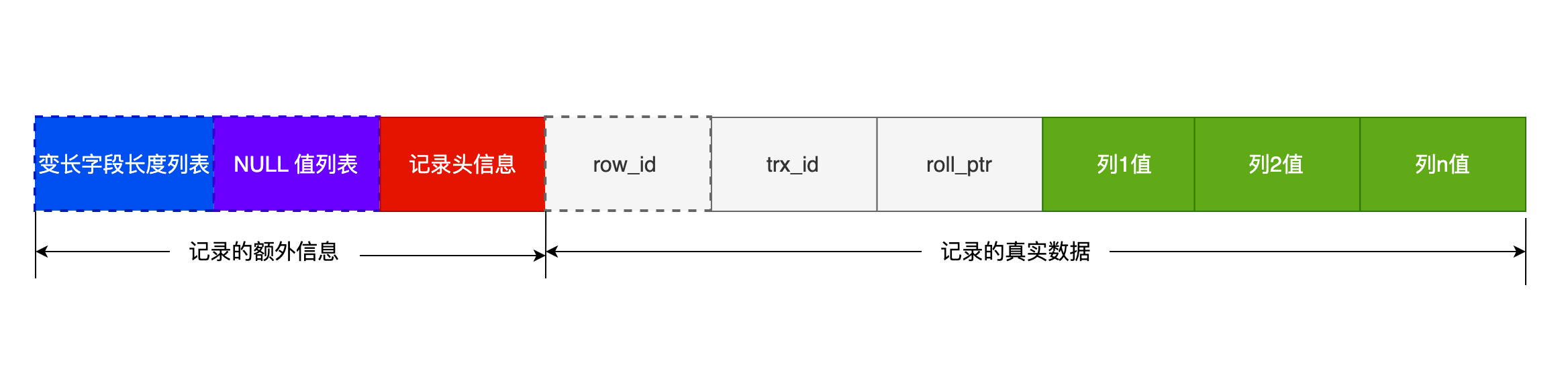
一条完整的记录分为记录的额外信息和记录的真实数据两个部分
记录的额外信息:
- 变长字段长度列表
- char是定长,varchar是变长,变长字段实际存储的数据的长度(大小)不固定
- 所以,在存储数据的时候,也要把数据占用的大小存起来,存到变长字段长度列表里面,读取数据的时候才能根据这个变长字段长度列表去读取对应长度的数据。
- 变长字段占的真实数据占用的字节数会按照列的顺序逆序存放>。
- 记录头信息中指向下一个记录的指针,指向的是下一条记录的记录头信息和真实数据之间的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据,比较方便
- 逆序存放,可以使得位置靠前的记录的真实数据和数据对应的字段长度信息可以同时在一个
CPU Cache Line中,可以提高CPU Cache的命中率。
- NULL值不不会存放在行格式中记录的真实数据部分里的,所以变长字段长度列表里不需要保存值为NULL的变长字段的长度。
- 当数据表没有变长字段时,这时表里的行格式就不会有变长字段长度列表了。
- NULL值列表
- 表中的某些列可能会存储NULL值,如果把这些NULL值放到记录的真实数据中会比较浪费空间,所以Compact行格式把这些值为NULL的列存储到NULL值列表中
- 如果存在允许NULL值得列,则每个列对应一个二进制位(bit),二进制位按照列的顺序逆序排列
- 二进制位的值为
1时,代表该列的值为NULL。 - 二进制位的值为
0时,代表该列的值不为NULL。 - NULL 值列表必须用整数个字节的位表示(1字节8位),如果使用的二进制位个数不足整数个字节,则在字节的高位补
0
- 二进制位的值为
- NULL值列表也不是必须的。当数据表的字段都定义成
NOT NULL的时候,这时候表的行格式就不会有NULL值列表
- 记录头信息
delete_mask:标识此条数据是否被删除。next_record:下一条记录的位置。记录与记录之间是通过链表组织的。record_type:表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录
记录的真实数据:
记录真实数据部分除了定义的字段,还有三个隐藏字段,分别为:row_id、trx_id、roll_pointer

row_id:如果建表时指定了主键或者唯一约束列,那么就没有row_id隐藏字段。如果都没有,InnoDB就会为记录添加row_id隐藏字段。非必须,占用6个字节trx_id:事务id,表示这个数据是由哪个事务生成的。必须,占用6个字节roll_pointer:记录上一个版本的指针。必须,占用7个字节
MYSQL规定除了TEXT、BLOBs这种大对象类型之外,其它所有列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过65535个字节。
varchar(n)字段类型的n代表的是最多存储的字符数量,并不是字节数
对于单字段情况:
- NULL值列表:字段允许为NULL,所以用1个字节表示NULL值列表
- 变长字段列表:如果变长字段允许存储的最大字节数<=255字节,就会用1字节表示变长字段长度;如果>255字节,就会用2字节表示变长字段长度
- 真实数据:以字符集ascii为例,单个字符占用1个字节
2 + 1 + x = 65535,x = 65532。在数据库表只有一个varchar(n)字符且字符集是ascii的情况下,varchar(n)中n的最大值是65532
对于多字段的情况下,要保证所有字段长度+变长字段字节数列表所占用的字节数+NULL列表所占用字节数<=65535
MySQL中磁盘和内存交互的基本单位是页,一个页的大小一般是16KB,也就是16384字节,而一个varchar(n)类型的列最多可以存储65535字节,这时一个页可能就i存不了一条记录。这个时候就会发生行溢出,多的数据就会存到另外的溢出页中。
Compact行格式:在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在溢出页中,然后真实数据处用20字节存储指向溢出页的地址,从而可以找到剩余数据所在页。Compressed和Dynamic:这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储20个字节的指针指向溢出页。而实际的数据都存在溢出页
主键索引最好是自增的?
InnoDB创建主键索引默认为聚簇索引,数据被存放在B+tree的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键值将其插入到对应的叶子点中。
- 如果使用自增主键,每次插入的新数据会插入到最后一个叶子节点,不需要移动已有的数据。让数据页写满,就会自动开辟一个新页面。每次插入一条新记录,都是追加操作,不需要重新移动数据,插入数据的方法效率非常高。
- 如果使用非自增主键,每次插入主键的索引值都是随机的,新数据可能会插入到现有数据也中间的某个位置,这就不得不移动其它数据,甚至数据页满了会导致页分裂,可能造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
索引最好设置为 NOT NULL ?
- 索引列存在
NULL就会导致优化器在做索引选择的时候更加复杂、难以优化。因为NULL的列会使索引、索引统计和值比较都更复杂。比如进行索引统计时,count会省略值为NULL的行。NULL值是一个没有意义的值,但是会占用物理空间,带来存储空间的问题。InnoDB存储记录时,如果表中存在允许为null的字段,那么行格式中至少会用1个字节空间存储NULL值列表。
MySQL是如何创建索引的?
在创建表时,InnoDB存储引擎会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key)
- 如果没有索引,就选择第一个不包含
NULL值得唯一列作为聚簇索引得索引键(key)- 以上两个都没有的情况下,
InnoDB将自动生成一个隐式自增id列作为聚簇索引的索引键
索引下推?
对于联合索引
(a, b),对于select * from table where a > 1 and b = 2;语句,只有a字段能用到索引,那么在联合索引的B+tree找到第一个满足条件的主键值(ID为2)后,还需要判断其它条件是否满足(看b是否等于2),那是在联合索引里判断?还是回主键索引去判断呢?
- MySQL5.6之前,只能从ID2(主键值)开始一个一个回表,到主键索引上找出数据行,再对比b字段值。
- MySQL5.6引入索引下推优化(index condition pushdown),可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
查询语句的执行计划里,出现了
Using index condition时,说明使用了索引下推优化
最左匹配?
在使用复合索引时,查询条件必须从索引的最左列开始。
回表机制?
在使用二级索引时,通过索引找到主键后,再根据主键查询完整数据行的过程
因为非聚簇索引只存储索引列和主键,查询完整记录还需要通过主键查询主键索引b+tree
索引覆盖?
索引覆盖(
Covering index)是一种优化查询性能的技术,指的是查询所需的所有列都包含在索引中,因此无需回表查询数据行。通过使用索引覆盖,可以减少I/O操作,提升查询效率。
聚簇索引和非聚簇索引?
- 聚集索引(
Clustered Index):将数据存储与索引放到一块,索引结构的叶子节点保存了行数据。必须有,而且只有一个
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个值不为
NULL唯一(Unqiue)索引作为聚集索引- 如果表没有主键,或没由合适的唯一索引,则InnoDB会自动生成一个
rowid作为隐藏的聚集索引。- 二级索引(
Secondary Index)/辅助索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键。可以存在多个。
为什么InnoDB存储引擎选择使用B+tree索引结构?
- 相比于二叉树,相同数据量下层级更少,搜索效率高
- 对于
B-tree,无论是叶子节点还是非叶子节点,都会存放数据(而每个节点存放在数据页page中,大小固定),导致一页中存储的键值减少,指针跟着减少,保存同样数据下,只能增加数的高度,导致性能下降。- 相比于
Hash索引,B+tree支持返回匹配及排序操作
索引失效?
- 使用左或者左右模糊匹配的时候,也就是
like x%或者like %xx%这两种方式都会造成索引失效- 在查询条件中对索引列做了计算、函数、类型转换操作,都会造成索引失效
- 联合索引要能正确使用需要遵循最左匹配原则,按照最左优先的方式进行索引的匹配,否则就会导致索引失效
- 在
where子句中,如果在OR前的条件列是索引列,而在OR后的条件列不是索引列,那么索引会失效
什么时候适合索引?
- 字段有唯一性限制的,比如商品编码
- 经常用于
where查询条件的字段,能够提高查询速度,如果查询条件不是一个字段,可以建立联合索引。- 经常用于
group by和order by的字段,这样在查询的时候就不需要做一次排序,因为建立索引之后的B+Tree中的记录都是排序好的。
什么时候不需要创建索引?
where条件,group by,order by里用不到的字段- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女。如果数据库中,男女记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这种情况下,还不如不要索引,因为MySQL的查询优化器,在发现某个值出现在表的数据行中的百分比很高时,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引
- 经常更新的字段不用创建索引,因为索引字段频繁修改,由于需要维护索引的有序性,有额外的维护成本。
sql语句执行计划?
explain select * from t_user where id = 10;
possible_keys:表示可能用到的索引key:字段表示实际用到的索引,如果这一项为NULL,说明没有使用索引key_len:表示索引的长度rows:表示扫描的数据行数type:表示数据扫描类型,重点关注
ALL:全表扫描index:全索引扫描range:索引范围扫描ref:非唯一索引扫描eq_ref:唯一索引扫描const:结果只有一条的主键或唯一索引扫描
InnoDB是如何存储数据的?
InnoDB的数据是按数据页为单位来读写的。当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。
数据库的I/O操作的最小单位是页,InnoDB数据的默认大小是
16KB,数据库每次读写都是以16KB为单位的,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中16KB内容刷新到磁盘中。
MySQL事务(Transaction)的4个特性?
事务是由MySQL存储引擎实现,InnoDB存储引擎支持事务。事务的4个特性
ACID
- 原子性(
Atomicity):一个事务中的所有操作,要么同时成功,要么同时失败,不存在一部分成功而另一部分执行失败的情况。事务在执行过程中发生错误,会回滚到事务开始前的状态。- 一致性(
Consistency):事务操作前和操作后,数据满足完整性约束,数据库保持一致性状态。- 隔离性(
Isolation):数据库允许多个并发事务同时对其数据进行读写和修改,隔离性可以防止多个事务并发执行时由于交叉执行而导致的数据不一致。因为每个事务同时使用相同的数据时,不会相互干扰,每个事务都有一个完整的数据空间,对其它并发事务是隔离的。- 持久性(
Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
InnoDB引擎通过什么技术来保证事务的ACID特性?
- 原子性:通过
undo log回滚日志- 隔离性:通过
MVCC多版本并发控制或锁机制来保证- 持久性:通过
redo log重做日志- 一致性:通过原子性+隔离性+持久性保证
并行事务会引发什么问题?
MySQL服务端允许多个客户端连接,这意味着MySQL会出现同时处理多个事务的情况。那么在同时处理多个事务时,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题。
脏读(
dirty read):如果一个事务(A)读到另一个未提交事务(B)修改过的数据,就意味着发生了脏读现象。因为事务(B)还未提交,如果发生了回滚,那么事务(A)刚才得到的数据就是过期的数据。不可重复读(
non-repeatable read):在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况,就意味着发生了不可重复读。在事务A读取两次读取同一个数据的期间,事务B修改了该数据并提交事务,就会导致A再次读取该数据时前后不一致。幻读(
phantom read):在一个事务内多次查询某个符合查询条件的记录数量,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了幻读现象。
事务的隔离级别有哪些?
脏读:读到其它事务未提交的数据
不可重复读:前后读取的数据不一致
幻读:前后读取的记录数量不一致
三个现象的严重性排序如下:
脏读 > 不可重复读 > 幻读
SQL标准提出了四种隔离级别来规避这些现象,隔离级别越高,性能效率越低。
- 读未提交(
read uncommitted):一个事务还没提交时,它做的变更就能被其它事务看到- 读提交(
read committed):一个事务提交之后,它做的变更才能被其它事务看到- 可重复读(
repeatable read):一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的。MySQL InnDB引擎的默认的隔离级别- 串行化(
serializable):会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行隔离水平从高到低: 串行化 > 可重复读 > 读已提交 > 读问题叫
MySQL的InnoDB存储引擎默认隔离级别能避免幻读现象吗?
InnoDB存储引擎默认隔离级别是可重复读(repeatable read),在很大程度上避免幻读现象(并不是完全解决了)。解决方案有两种:
- 针对快照读(普通
select语句),是通过MVCC方式解决幻读。因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其它事务插入了一条数据,它也不会查询到这条数据,所以就很好地避免幻读问题- 针对当前读(
select ... for update等语句),是通过next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行select ... for update语句地时候,会加上next-key lock,如果有其它事务在next-key lock锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好地避免幻读问题。
MySQL事务隔离级别具体是如何实现的?
- 读未提交:因为可以读到未提交事务修改的数据,所以直接读取最新的数据即可
- 串行化:通过加读写锁的方式来避免并行访问
- 读提交和可重复读:都是通过
Read View来实现的,区别在于创建Read View的时机不同,可以把Read View理解成一个数据快照。
- 读提交隔离级别在每个语句执行前都会重新生成一个
Read View- 可重复读是在启动事务时生成一个
Read View,然后整个事务期间都在用这个Read View
通过「版本链」来控制并发事务访问同一个记录时的行为就叫MVCC(多版本并发控制)
Read View有四个重要的字段:
m_ids:创建Read View时,当前数据库中活跃事务的事务id列表。活跃事务指的是,启动了但还没提交的事务。min_trx_id:创建Read View时,当前数据库中活跃事务中事务id最小的事务,即m_ids的最小值max_trx_id:创建Read View时当前数据库中应该给下一个事务的id值,也就是全局事务中最大的事务id值+1creator_trx_id:创建该Read View的事务的事务id聚簇索引记录中的两个隐藏列:
trx_id:当一个事务对某条聚簇索引记录进行更改时,就会把该事务的事务id记录在trx_id隐藏列中。roll_pointer:每次对某条聚簇索引记录进行修改时,都会把旧版本的记录写入到undo日志(回滚日志)中,然后这个隐藏列是个指针,指向每一个旧版本记录,可以通过它找到修改前的记录。
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的
trx_id值小于Read View中的min_trx_id,表示这个版本的记录是在创建Read View前已经提交的事务生成的,所以该版本的记录对当前事务可见。 - 如果记录的
trx_id值大于等于Read View中的max_trx_id值,表示这个版本的记录是在创建Read View后才启动的事务生成,所以该版本对当前事务不可见。 - 如果记录的
trx_id值在Read View的min_trx_id和max_trx_id之间,需要判断trx_id是否在m_ids列表中:- 如果记录的
trx_id在m_ids列表中,表示生成该版本记录的活跃线程依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。将会沿着undo log链条往下找旧版本的记录,直到找到trx_id【小于】Read View中的min_trx_id值的第一条记录。 - 如果记录的
trx_id不在m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
- 如果记录的
可重复读是如何工作的?
可重复读隔离级别是启动事务时生成一个
Read View,然后整个事务器间都在使用这个Read View。当读取到的记录的
trx_id在m_ids中时,说明该记录是由未提交的事务生成的,事务不会读取这个版本的记录。而是沿着undo log链条往下找旧版本的记录,直到找到trx_id小于事务的Read View中的min_trx_id值得第一条记录。
读提交是如何工作的?
读提交事务隔离级别是在每次读取数据时,都会生成一个新的
Read View。
什么是幻读?
当同一个查询在不同的时间产生不同的结果集时,事务中就会出现所谓的幻读问题。例如,如果
select执行了两次,但第二次返回了第一次中没有返回的行,则该行是“幻象”行
MySQL默认隔离级别(可重复读)可以在一定程度上解决幻读?
快照读(普通
select):
- 开始事务后(执行begin语句后),在执行第一个查询语句后,会创建一个
Read View,后续的查询语句利用这个Read View,通过这个Read View就可以在undo log版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的。即使中途有其它事务插入了新记录,也查询不出来这条记录,所以就很好地避免了幻读问题。当前读(
select ... for update):
- MySQL里除了普通查询是快照读,其它都是当前读,比如
update、insert、delete,这些语句执行前都会查询最新版本地数据,然后再做进一步的操作。selct ... for update查询语句是当前读,每次执行的时候都是读取最新的数据。Innodb引擎为了解决可重复读隔离级别使用当前读而造成的幻读问题,使用了间隙锁。-- 事务A begin; select name from t_stu where id > 2 for update; # 事务A执行了这条语句后,就在表中的记录加上id范围 (2, +∞)的`next-key lock`(间隙锁+记录锁的组合) -- 事务B begin; insert into t_stu values (5, "Tom", 100); -- 阻塞! # 事务B在执行插入语句的时候,判断到插入的位置被事务A加了`next-key lock`,于是事务B会生成一个插入意向锁,同时进入等待状态,直到事务A提交了事务。 # 这就避免了由于事务B插入新记录而导致事务A发生幻读的现象
可重复读隔离级别下,幻读没有被完全解决?
可重读读隔离级别下可以很大程度上避免幻读,但是还没有完全解决幻读。
第一个发生幻读现象的场景读:
- 事务A普通查询(select),没有结果
- 事务B插入一条记录,提交事务。(这里得提交事务,不然当前读的
next-key lock会阻塞事务A)- 事务A更新该记录(因为,更新记录是当前读,能够看到B插入的数据,当期进行更新是,记录的
trx_id改为事务A的id,所以事务A再次进行普通查询时就能够查到了)- 事务A再次查询,查到该记录——出现幻读现象
第二个发生幻读现象的场景:
- T1时刻:事务A先执行快照读语句:
select * from t_test where id > 100得到3条记录- T2时刻:事务B插入一个
id=200的记录并提交- T3时刻:事务A再执行当前读语句:
select * from t_test where id > 100 for update就会得到4条记录,此时发生了幻读现象要避免这类特殊场景下发生幻读的现象的话,就是尽量在开启事务之后,马上执行
select ... for update这嘞当前读语句,因为它会对记录加next-key lock,从而避免其它事务插入一条新记录。
-- 使用全局锁
flush tables with read lock;
-- 释放全局锁
unlock tables;
-- 当会话断开,全局锁会自动释放执行后,整个数据库就处于只读状态了,这时其它线程执行以下操作,都会被阻塞:
- 对数据库的**增删改(DML)**操作,比如
insert,delete,update等语句 - 对**表结构的更改(DDL)**操作,如
alter table,drop table等语句
全局锁应用场景是什么?
- 全库逻辑备份。在备份数据库期间,不会因为数据或表结构的更新,而出现备份文件的数据与预期不一样
备份数据库数据的时候,使用全局锁会影响业务,有什么其它方式可以避免?
- 在备份数据库之前开启事务,会先创建
Read View,然后整个事务执行期间都在用这个Read View,而且由于MVCC的支持,备份期间业务依然可以对数据进行更新操作,不会影响备份数据库时的Read View,这样备份期间备份的数据一直是在开启事务时的数据。
# 在InnoDB引擎中,可以在备份时加上参数 --single-transaction 完成不加锁的一致性数据备份
mysqldump --single-transaction -uroot -pPWD 数据库 > filename.sql
表级锁,每次操作锁住整张表。锁定粒度大,发生锁重读的概率最高,并发度最低。应用在MyISAM,InnoDB等存储引擎。对于表级锁,主要分为以下三类:
- 表锁
- 元数据锁(
meta data lock, MDL) - 意向锁
-- 加锁
lock tables tb_name1, tb_name2, ... read/write;
-- 解锁
unlock tables;- 表共享锁(
read lock)

- 加锁客户端和其它客户端都可以执行读操作——读读不互斥
- 加锁客户端和其它客户端都不能执行写操作。当前客户端的写操作会失败,其它客户端的写操作会被阻塞。
- 表独占锁(
write lock)

- 当前客户端可以执行读和写操作
- 其它客户端的读和写操作都会被阻塞
DML加锁过程是系统自动控制,无需显式使用,在访问一张表的时候会自动加上。MDL锁主要作用是维护表元数据的数据 一致性,在表上有活动事务时,不可以对元数据进行写入操作。为了避免DML和DDL冲突,保证读写的正确性。
在Mysql5.5中引入MDL,当对一张表进行增删改查时,加MDL读锁(共享);当对一张表结构进行变更时,加MDL写锁(排他)
| 对应SQL | 锁类型 | 说明 |
|---|---|---|
lock tables ... read/write |
SHARED_READ_ONLY/SHARED_NO_READ_WRITE |
|
select, select ... lock in share mode |
SHARED_READ |
与SHARED_READ、SHARED_WRITE兼容,与EXCLUSIVE互斥 |
insert, update, delete, select ... for update |
SHARED_WRITE |
与SHARED_READ、SHARED_WRITE兼容,与EXCLUSIVE互斥 |
alter table ... |
EXCLUSIVE |
与其它MDL都互斥 |
为了避免DML在执行时,加的行锁与表锁的冲突,在InnoDB中引入了意向锁,使得表锁不用检查每行数据是否加锁,使用意向锁来减少锁的检查。
- 意向共享锁(
IS):select ... lock in share mode;- 与表锁共享锁
read兼容,与表锁排他锁write互斥
- 与表锁共享锁
- 意向排他锁(
IX):insert,update,delete,select ... for update添加- 与表锁共享锁
read及排他锁write都互斥。意向锁之间不会互斥
- 与表锁共享锁
-- 查看意向锁及行锁的加锁情况
select object_schema, object_name, index_name, lock_type, lock_mode, lock_data from performance_schema.data_locks;行级锁,每次操作锁住对应的行数据,锁定粒度最小,发生锁冲突的概率最高,并发度最高,应用在InnoDB存储引擎。
InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其它事务对此进行
update和delete。在RC、RR隔离级别下都支持- 共享锁(
S):允许一个事务去读一行,阻止其它事务获得相同数据集的排他锁 - 排他/独占锁(
X):允许获取排他锁的事务更新数据,组织其它事务获得相同数据集的共享锁和排他锁 
- 共享锁(
- 间隙锁(
Gap Lock):锁定索引记录间隙(不含记录),确保索引记录间隙不变,防止其它事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持 - 临键锁(
Next-Key Lock):行锁和间隙锁组合,同时锁主数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持。

MySQL 8.0.26版本,在可重复读隔离级别之下,唯一索引和非唯一索引的行级锁和加锁规则
唯一索引等值查询:
- 当查询的记录存在时,在索引树上定位到这一条记录后,将该记录的索引中的
next-key lock会退化为记录锁- 当查询的记录不存在时,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的
next-key lock会退化成间隙锁非唯一索引等值查询:
- 当查询的记录存在时,由于不是唯一索引,所以可能存在索引值相同的记录。于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是next-key锁,而对于第一个不符合条件的二级索引记录,该二级索引的next-key锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。
- 当查询的记录不存在时,扫描到第一条不符合条件的二级索引记录,该二级索引的
next-key锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。非唯一索引和主键索引的范围查询的加锁规则不同之处在于:
- 唯一索引在满足一些条件时,索引的
next-key lock退化为间隙锁或者记录锁。- 非唯一索引范围查询,索引的
next-key lock不会退化为间隙锁和记录锁。
没加索引的查询
如果锁定读select ... for update查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加上next-key lock,这样就相当于锁主的全表,这时如果其它事务对该表进行增、删、改操作的时候,都会被阻塞。
在线上执行update、delete、select ... for update等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加next-key lock,相当于把整个表锁主了。
undo log(回滚日志):是Innodb存储引擎层生成的日志,实现事务的原子性,主要用于事务回滚和MVCC。redo log(重做日志):是Innodb存储引擎层生成的日志,实现了事务的持久性,主要用于掉电等故障恢复。binlog(归档日志):是Server层生成的日志,主要用于数据备份和主从复制。
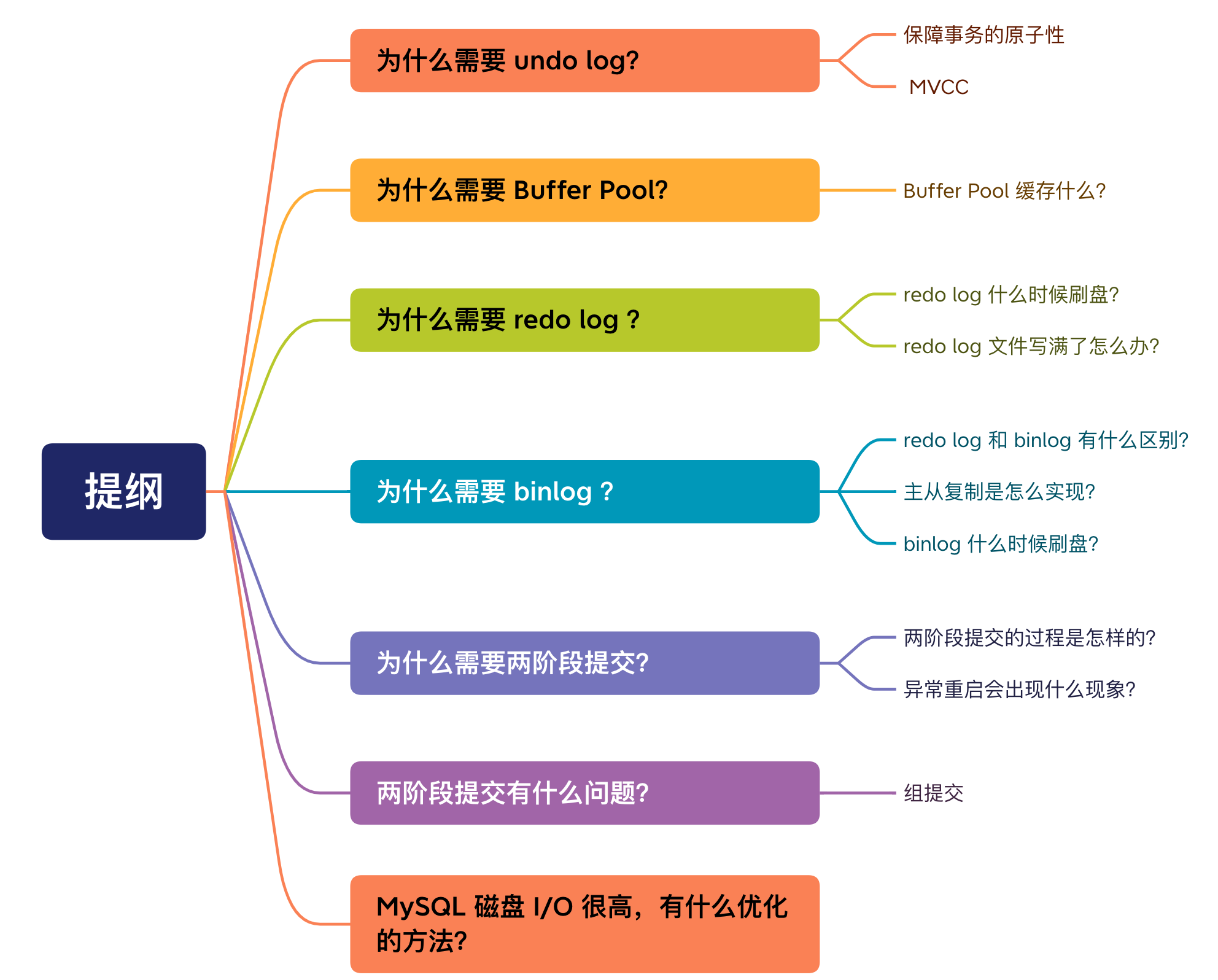
在执行一条“增删改”语句的时候,虽然没有输入begin开始事务和commit提交事务,但是MySQL会隐式开启事务来执行“增删改”语句,执行完就自动提交事务。
执行一条语句是否自动提交事务,是由autocommit参数决定的,默认是开启的。
undo log是一种用于撤退回退的日志。在事务没提交之前,MySQL会先记录更新前的数据到undo log日志文件里面,当事务回滚时,可以利用undo log来进行回滚。
- 在插入一条记录时,要把该记录的主键值记下来,回滚时只需要把主键值对应的记录删除即可。
- 在删除一条记录时,要把该记录中的内容都记下来,回滚时再把由这些内容组成的记录插入到表中。
delete操作实际上不会立即直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成
- 在更新一条记录时,要把被更新的列的旧值记录下来,回滚时再把这些列更新为旧值即可。
- 如果更新的不是主键列,在undo log中直接反向记录是如何update的,即update是直接进行的
- 如果是主键列,update分两部分执行:先删除该行,再插入一行目标行
undo log两大作用:
- 实现事务回滚,保障事务的原子性。事务处理过程中,如果出现了错误或者用户执行了
rollback语句,MySQL可以利用undo log中的历是数据将数据恢复到事务开始之前的状态- 结合
Read View实现MVCC(多并发版本控制)。MVCC通过Read View + undo log实现,undo log为每条记录保存多份历史数据,MySQL在执行快照都(普通select语句)的时候,会根据事务的Read View里的信息,顺着undo log的版本链找到满足其可见性的记录。
具体更新一条记录update t_user set name = 'charlie' where id = 1;的流程如下:
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引数搜索获取
id=1这一行记录:- 如果
id=1这一行记录所在的数据页本来就在buffer poll中,就直接返回给执行器更新 - 如果记录不在buffer pool,将数据页从磁盘读入到buffer pool,返回记录给执行器
- 如果
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样
- 如果一样的话,就不进行后续更新流程
- 如果不一样的话,就把更新前的记录和更新后的记录都当作参数传给
InnoDB层,让InnoDB真正执行更新记录的操作
- 开启事务,InnoDB层更新记录前,首先要记录相应的
undo log,因为这是更新操作,需要把更新的列的旧值记录下来,也就是要生成一条undo log,undo log会写入Buffer Pool中的Undo页面,不过在内存修改该Undo页面后,需要记录对应的redo log。 - InnoDB层开始更新记录,会更新内存(同时标记为脏页),然后将记录写道
redo log里面,这时候更新就算完成了。为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是WAL技术,MySQL的写操作并不是立即写到磁盘上,而是先写redo日志,然后在合适的时间再将修改的行数据写到磁盘上。 - 至此,一条记录更新完了。
- 在一条更新语句执行完成后,然后开始记录该语句的
binlog,此时记录的binlog会被保存到binlog cache,并没有刷新到磁盘上的binlog文件,在事务提交时才会统一将该事务运行过程中的所有binlog刷新到磁盘。 - 事务提交
prepare阶段:将redo log对应的事务状态设置为prepare,然后将redo log刷新到硬盘commit阶段:将binlog刷新到磁盘,接着调用引擎的提交事务接口,将redo log状态设置为commit(将事务设置为commit状态后,刷新到磁盘redo log文件)
- 至此,一条更新语句执行完成。
MySQL的数据是存储在磁盘里的,但是每次都从磁盘中读取数据,性能是极差的。为此,InnoDB存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能。
- 当读取数据时,如果数据存在于Buffer Pool中,客户端就会直接读取Buffer Pool中的数据,否则再去磁盘读取
- 当修改数据时,首先是修改Buffer Pool中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页数据写入到磁盘
Buffer Pool是在MySQL启动的时候,向操作系统申请的一片连续的内存空间,默认配置下Buffer Pool只有128MB。可以通过调整innodb_buffer_pool_size参数来这时Buffer Pool`的大小
在MySQL启动的时候,InnoDB会为Buffer Pool申请一片连续的内存空间,然后按照默认的16KB的大小划分出一个个的页,Buffer Pool中的页就叫做缓存页。此时这些缓存页都是空闲的,之后随着程序的运行,才会有磁盘上的页被缓存到Buffer Pool中。
Buffer Pool除了缓存索引页和数据页,还包括了undo页、插入缓存、自适应哈希索引、锁信息等等。
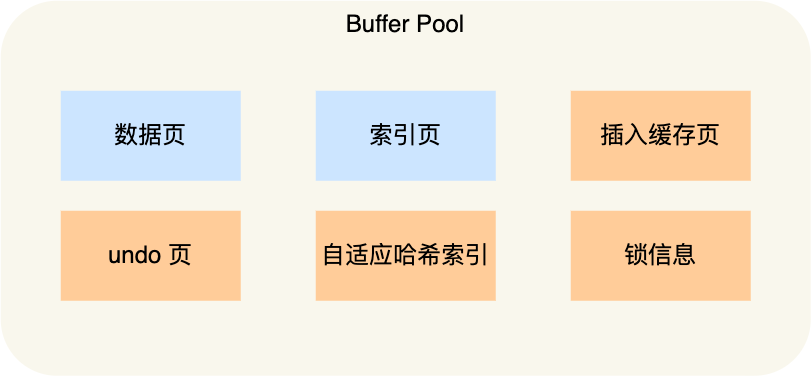
为了更好的管理在Buffer Pool中的缓存页,InnoDB为每一个缓存页都创建了一个控制块,控制块信息包括缓存页的表空间、页号、缓存页地址、链表节点等等
查询一条记录后,就只需要缓存一条记录吗?
- 不是,当查询一条记录时,InnoDB是会把整个页的数据加载到Buffer Pool中,因为通过索引只能定位到磁盘中的页,而不能定位到页中的一条记录。将页加载到Buffer Pool后,再通过页里面的目录去定位到某条具体的记录。
Buffer Pool是一片连续的内存空间,当MySQL运行一段时间后,这片连续的内存空间中的缓存页既有空闲的,也有未被使用的。当从磁盘读取数据时,总不能遍历这一片连续的内存空间来找到空闲的缓存页吧
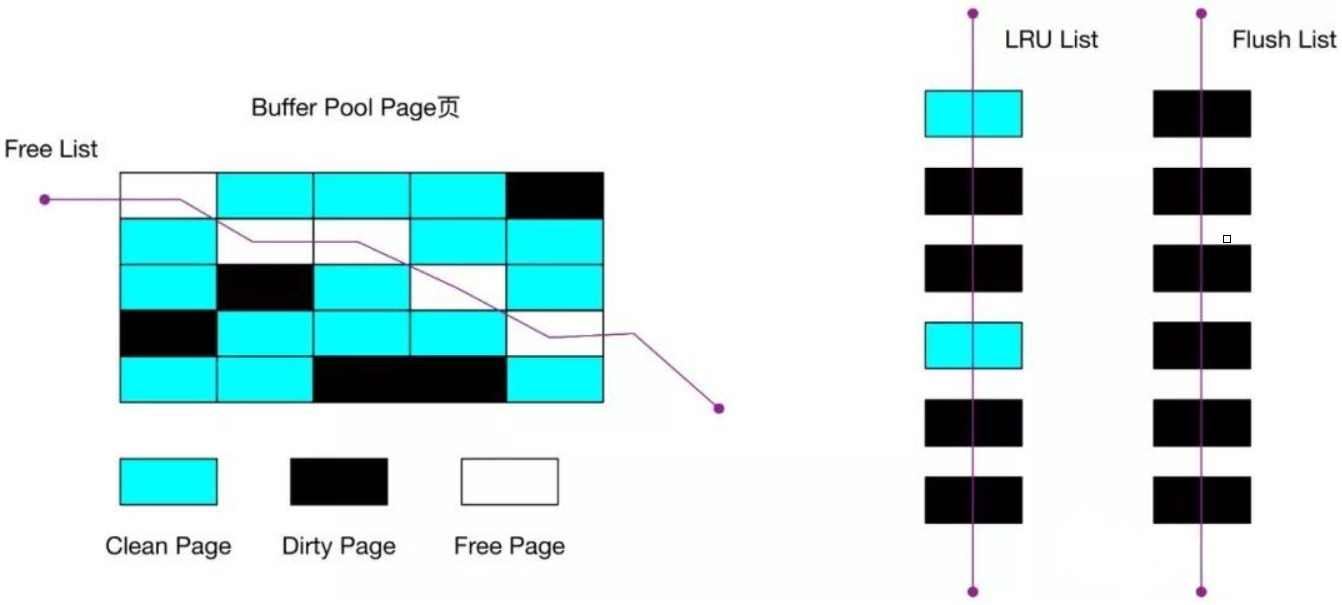
为了能够快读找到空闲的缓存页,可以使用链表结构,将空闲缓存页的控制块作为链表的节点,这个链表称为Free链表(空闲链表)。
- Free链表节点是一个一个的控制块,而每个控制块包含着对应缓存页的地址,所以相当于Free链表节点都对应一个空闲的缓存页
- Free链表除了有控制块,还有一个头结点,该头结点包含链表的头结点地址,尾节点地址,以及当前链表中节点的数量等信息。
更新数据的时候,不需要每次都要写入磁盘,而是将Buffer Pool对应的缓存页标记为脏页,然后再由后台线程将脏页写入磁盘。
Flush链表用于快速找到哪些缓存页是脏的,与Free链表类似,链表的节点也有控制块,区别在于Flush链表的元素都是脏页。
Buffer Pool的大小是有限的,对于一些频繁访问的数据我们希望可以一致留在Buffer Pool中,而一些很少访问的数据希望可以再某些时机可以淘汰掉,从而保证Buffer Pool不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在BufferPool中。
Buffer Pool中有三种页和链表来管理数据
Free Page空闲页:表示此页未被使用,位于Free链表Clean Page干净页,表示此页已被使用,但是页面未发生修改,位于LRU链表Dirty Page脏页,表示此页已被使用且已经被修改,其数据和磁盘上的数据已经不一致。当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该页变成了干净页。脏页同时位于LRU链表和Flush链表。
什么是预读失败?
- MySQL的预读机制。程序是有空间局部性的,靠近当前被访问数据的数据,在未来很大概率会被访问到。
- MySQL在加载数据页时,会提前把它相邻的数据页一并加载进来,目的是为了减少磁盘IO
- 但是这些被提前加载进来的数据页,并没有被访问,相当于预读白做了,这就是预读失败。
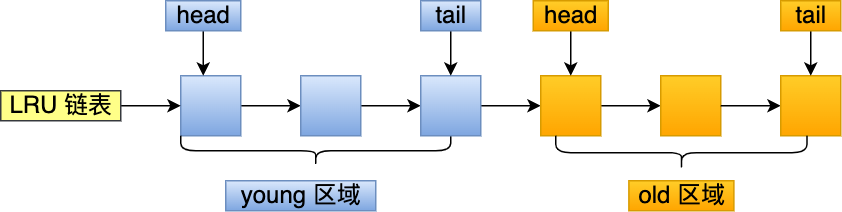
MySQL改进了LRU算法,把LRU划分了2个区域:old区域和young区域。young区域在LRU链表的前半部分,old区域则是在后半部分。
划分这两个区域后,预读的页就只需要加入到old区域的头部,当页被真正访问的时候,才将页插入到young区域的头部。
Buffer Pool污染?
- 当某一个SQL语句扫描了大量的数据时,在BufferPool空间比较有限的情况下,可能会将BufferPool里的所有页都替换出去,导致大量热数据被淘汰,等这些热数据又被访问的时候,由于缓存未命中,就会产生大量的磁盘IO,MySQL性能就会急剧下降,这个过程被称为BufferPool污染。
select * from t_user where name like '%xiaolin%';
- 从磁盘读到的页加入到LRU链表的old区域头部
- 当从页里读取行记录时,也就是页被访问的时候,就要将该页放到young区域头部
- 接下来拿记录的name字段和字符串xiaolin进行模糊匹配,如果符合条件,就加入到结果集里。
- 如此往复,直到扫描完表中的所有记录
- 以上这种全表扫描的查询,很多缓冲页只会被访问一次,但是它却只因为被访问一次而进入到young区域,从而导致热点数据被替换。
MySQL为进入到young区域增加一个停留在old区域的时间判断的条件
对某个处于old区域的缓存页进行第一次访问时,就在它对应的控制块中记录下来一个访问时间
- 如果后续访问时间与第一次的时间在某个时间间隔内,那么缓存页就不会被从old区域移动到young区域的头部
- 如果后续的访问时间与第一次访问的时间不在某个时间间隔内,那么该缓存页移动到young区域的头部
只有同时满足被访问与在old区域停留时间超过1秒两个条件,才会被插入young区域头部这样就解决了Buffer Pool污染的问题。
InnoDB存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能。
BufferPool以页为单位缓冲数据,可以通过innodb_buffer_pool_size参数调整缓冲池的大小,默认是128M
InnoDB通过三种链表来管理缓存页:
Free List空闲页链表,管理空闲页Flush List脏页链表,管理脏页LRU List管理脏页+干净页,将最近且经常查询的数据缓存在其中,而不常查询的数据淘汰出去
InnoDB对LRU做了一些优化,普通LRU算法通常是将最近查询的数据放到LRU链表的头部,而InnoDB做了2点优化:
- 将LRU链表分为
young和old两个区域,加入缓冲池的页,优先插入old区域;页被访问时,才进入young页,目的是为了解决预读失效的问题 - 当页被访问且old区域停留时间超过
innodb_old_blocks_time阈值时,才会将页插入到young区域,否则还是插入到old区域,目的是为了解决批量数据访问,大量热数据淘汰问题。
可以通过调整innodb_old_blocks_pct参数,设置young区域和old区域比例
在开启慢SQL监控后,如果发现偶尔会出现一些用时稍长的SQL,这可能是因为脏页在刷新到磁盘时导致数据库性能抖动。如果在很短的时间出现这种现象,就需要调大Buffer Pool空间或者redo log日志的大小。
Redis(Remote Dictionary Server),基于内存的k-v非关系型数据库
Redis和Memcached共同点:
- 都是基于内存的数据库,一般都用来当作缓存使用
- 都有过期策略
- 两者的性能都非常高
Redis和Memcached区别:
- Redis支持的数据类型更丰富(String、Hash、List、Set、ZSet),
- 而Memcached只支持最简单的key-value数据类型
- Redis支持数据的持久化,可以将内存中的数据保存到磁盘中,重启的时候可以再次加载进行使用;
- Memcached没有持久化功能,数据全部存在内存中,重启或者宕机后数据丢失
- Redis原生支持集群模式
- Memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据
- Redis支持发布订阅模型、Lua脚本、事务等功能
- Memcached不支持
- Redis具备高性能
- 假如用户第一次访问MySQL中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将用户访问的数据缓存到Redis中,下次再访问这些数据时直接从缓存中获取,操作Redis缓存就是直接操作内存,所以速度很快
- Redis具备高并发
- 单台设备的Redis的QPS是MySQL的10倍,Redis单机的QPS能轻松破10w,而MySQL单机的QPS很难破1w
- 直接访问Redis能够承受的请求是远远大于直接访问MySQL的,所以可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库
string:缓存对象、常规计数、分布式锁List:消息队列Hash:缓存对象、购物车Set:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等Zset:排序场景,比如排行榜、电话和姓名排序BitMap:二值状态统计的场景,比如签到、判断用户登录状态、连续签到用户的总数HyperLogLog:海量数据基数统计的场景,比如百万计网页UV计数等
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};Redis基本数据类型
Redis常见的五种数据类型:String字符串、Hash哈希、List列表、Set集合、Zset有序集合。
- 获取字符串长度的时间复杂度O(1)
- 支持动态扩容
- 减少内存分配次数
- 二进制安全,根据len判断字符串长度,可以存储任意字符
Redis的aof和rdb
节点宕机后如何恢复?
缓存击穿和缓存穿透的方式
HTTP是超文本传输协议,即Hyper Text Transfer Protocol
协议:HTTP是一个用在计算机世界里的协议,确定计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。
传输:HTTP协议是一个双向协议,允许中间有中转或接力。HTTP是一个在计算机世界里专门用来两点之间传输数据的约定和规范。
超文本:HTTP传输的的内容是超文本。如HTML,本身只是纯文字文件,但内部用很多标签定义了图片、视频等的连接。
HTTP是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范。

1xx类状态码属于提示信息,是协议处理中的一种中间状态,实际用到比较少。
2xx类状态码标识服务器成功处理了客户端的请求
200 OK:最常见的成功状态码,表示一切正常。如果是非HEAD请求,服务器返回的响应投都会有body数据204 No Content,与200基本相同,但响应头没有body数据206 Partial Content:应用于HTTP分块下载或断点续传,表示响应返回body数据并不是资源的全部,而是其中一部分,也是服务器处理成功的状态。
3xx类状态码表示客户端请求的资源发生了变动,需要客户端用新的URL重新发送请求获取资源,即重定向。301和302都在响应头里使用字段Location,指明后续要跳转的URL,浏览器会自动重定向到新的URL。
301 Moved Permanently表示永久重定向,说明请求的资源已经存在了,需改用新的URL再次访问302 Found表示临时重定向,说明请求的资源还在,但暂时需要用另一个URL来访问呢304 Not Modified不具有跳转含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
4xx类状态码表示客户端发送的报文有误,服务器无法处理,即错误码
400 Bad Request表示客户端请求的报文有错误,但只是个笼统的错误403 Forbidden表示服务器禁止访问资源,并不是客户端请求出错404 Not Found表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端
5xx类状态码表示客户端请求报文正确,但是服务器处理时内部发生错误,属于服务端的错误码
500 Internal Server Error也是个笼统通用的错误码,服务器发生了什么错误,并不知道501 Not Implemented表示客户端请求的功能还不支持502 Bad Gateway通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误503 Service Unavailable表示服务器当前很忙,暂时无法响应客户端
Host字段:客户端发送请求时,用来指定服务器的域名。Host: www.bilibili.comn。有了Host字段,就可以将请求发往**同一台**服务器的不同网站。
Content-Length字段:服务器在返回数据时,会有Content-Length字段,表明本次回应的数据长度。Content-Length: 1000
HTTP是基于TCP传输协议进行通信的,使用TCP传输协议,就会存在一个“粘包”的问题,HTTP协议通过设置回车符、换行符作为HTTP Header的边界,通过Content-Length字段作为HTTP body的边界,这两个方式都是为了解决“粘包”问题。
Connection字段:最常用于客户端要求服务器使用HTTP长连接机制,以便其它请求复用。Connection: Keep-Alive。
- HTTP长连接的特点是,只要任意一端没有明确提出断开连接,则保持TCP连接状态
HTTP/1.1版本的默认连接都是长连接,但是为了兼容老版本的HTTP,需要指定Connection首部字段的值为Keep-Alive
Content-Type字段:用于服务器回应时,告诉客户端,本次数据是什么格式。Content-Type: text/html; Charset=utf-8,表明发送的是网页,而且编码是UTF-8。客户端请求的时候,可以使用Accept: */*字段声明自己可以接受哪些数据格式。
Content-Encoding字段说明数据的压缩方式,表示服务器返回的数据使用了什么压缩格式。Content-Encoding: gzip表示服务器返回的数据采用gzip方式压缩,客户端在请求时,用Accept-Encoding: gzip, deflate说明自己可以接受哪些压缩方式。
GET
- 根据RFC规范,GET的语义是从服务器获取指定的资源。
- GET请求的参数位置一般是写在URL中,URL规定只能支持ASCII,所以GET请求的参数只允许ASCC字符
- 浏览器会会对URL的长度有限制,因此GET请求的长度有限
POST
- 根据RFC规范,POST的语义是根据请求符合(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。
- POST请求携带的数据的位置一般是写在报文BODY中,body中的数据可以是任意格式的数据
- 浏览器不对body的大小做限制,因此post请求的参数长度没有限制。
安全和幂等的概念
- 在HTTP协议里,安全是指请求方法不会破坏服务器上的资源
- 幂等,是指多次执行相同的操作,结果都是相同的
如果从RFC规范定义的语义来看:
- GET方法就是安全且幂等的,因为它是只读操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。所以,可以对GET请求的数据做缓存,这个缓存可以到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如nginx),而且在浏览器中GET请求可以保存为书签。
- POST因为是新增或提交数据的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所示不是幂等的。所以,浏览器一般不会缓存POST请求,也不能把POST请求保存为书签。
总结:
- GET的语义是请求获取指定的资源。GET方法是安全、幂等、可被缓存的
- POST的语义是根据请求负荷(报文主体)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST不安全,不幂等,(大部分实现)不可缓存
对于一些具有重复性的HTTP请求,比如每次请求得到的数据都一样,可以把这对请求-响应的数据都缓存在本地,那么下次就直接读取本地的数据,不必在通过网络获取服务器的响应。
避免发送HTTP请求的方式就是通过缓存技术,HTTP缓存有两种实现方式,分别是强制缓存和协商缓存。
强制缓存指的是只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在浏览器这边。
强制缓存是利用了两个HTTP响应头部(Response Header)字段实现的,它们都用来表示资源在客户端缓存的有效期。
Cache-Control:是一个相对时间,优先级高于ExpireExpire:是一个绝对时间
Cache-Control的具体实现流程如下:
- 当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在Response头部加上Cache-Control,设置了过期时间大小
- 浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与
Cache-Control中设置的过期时间大小,来计算出该资源是否过期,如果没有,则使用该缓存,否则重新请求服务器。 - 服务器再次收到请求后,会再次更新Response头部的
Cache-Control
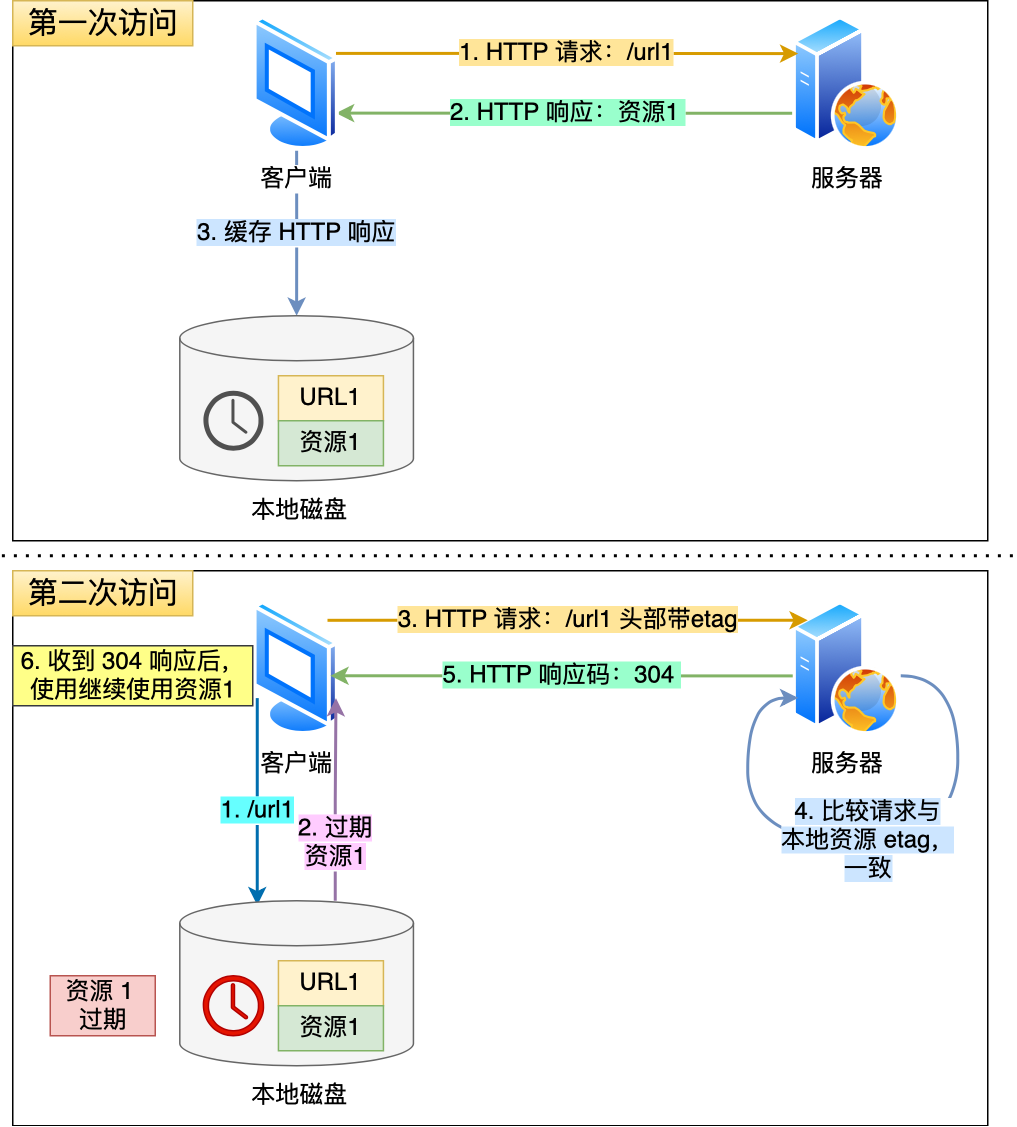
当我们在浏览器使用开发者工具的时候,可能会看到某些请求的响应码是304,这个是告诉浏览器可以使用本地缓存的资源,通常这种通过服务端告知客户端是否可以使用缓存的方式被称为协商缓存。
下图就是一个协商缓存的过程,协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存
协商缓存可以基于两种头部来实现:
- 第一种:请求头部的
If-Modified-Since字段与响应头部中的Last-Modified字段实现,这两个字段的意思是: - 第二种:请求头部的
If-None-Match字段与响应头部中的ETag字段。ETag是服务端根据客户端请求的资源生成的唯一标识,优先级高于Last-Modified,因为:- 在没有修改文件内容情况下文件的最后修改时间可能也会改变,这回导致客户端认为这文件被改动了,从而重新请求
- 可能有些文件在秒级以内修改的,
If-Modified-Since能查导的粒度是秒级的,使用ETag就能够保证这种需求下客户端在1秒内能刷新多次。 - 有些服务器不能精确获取文件的最后修改时间
协商缓存这两个字段都需要配合强制缓存中的Cache-Control字段来使用,只有在未能命中强制缓存的时候,才能发起带有协商缓存字段的请求
当使用ETag字段实现的协商缓存的过程:
- 当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在
Response头部加上ETag唯一标识,这个唯一标识的值是根据当前请求的资源生成的 - 当浏览器再次请求访问服务器中的该资源时,首先会检查强制强制缓存是否过期:
- 如果没有过期,则直接使用本地缓存
- 如果缓存过期了,会在
Request头部加上If-None-Match字段,该字段的值就是ETag唯一标识
- 服务器再次收到请求后,会根据请求中的
If-None-Match值与当前请求的资源生成的唯一标识进行比较:- 如果值相等,则返回
304 Not Modified,不会返回资源 - 如果不相等,则返回
200状态码和返回资源,并在Response头部加上新的ETag唯一标识
- 如果值相等,则返回
- 如果浏览器收到304的请求状态响应码,则会从本地缓存中加载资源,否则更新资源
- 简单。HTTP基本的报文格式就是
header+body,头部信息也是key-value简单文本形式,易于理解。 - 灵活和易于扩展。
- HTTPS就是在HTTP与TCP层之间增加了
SSL/TSL安全传输层 - HTTP/1.1和HTTP/2.0传输协议使用的是TCP协议,而到了HTTP/3.0传输协议改用了UDP协议
- HTTPS就是在HTTP与TCP层之间增加了
- 应用广泛和跨平台。
- 无状态。HTTP不会保留上次请求的结果,来处理本次请求。
- 对于无状态问题,最常用的解决方案是
Cookie技术。通过在请求和响应报文中写入Cookie信息来控制客户端的状态。 Cookie由服务端产生,保存在客户端,客户端在发送请求时会在请求头中携带Cookie信息
- 对于无状态问题,最常用的解决方案是
- 明文传输,不安全。
- 通信使用明文(不加密),内容可能被窃听
- 不验证通信双方的身份,有可能遭遇伪装
- 无法证明报文的完整性,有可能被篡改。
HTTP协议是基于TCP/IP。并且使用了请求-应答的通信模式,所以性能的关键就在这两点里
- 长连接。早期HTTP/1.0性能上一个很大的问题就是每发起一个请求,都要新建一次TCP连接(三次握手),而且是串行请求,做了很多无谓的TCP链接建立和断开,增加了通信开销。**HTTP/1.1使用长连接的通信方式,也叫持久连接。减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。**持久连接的特点是,只要任意一端没有明确提出断开连接,则保持TCP连接状态。当然,如果某个 HTTP 长连接超过一定时间没有任何数据交互,服务端就会主动断开这个连接。
- 管道网络传输。在同一个TCP连接里面,客户端可以发起多个请求,只要第一个请求发出来了,不必等其回来,就可以发出第二个请求,可以减少整体的响应时间。但是服务器必须按照接受请求的顺序,发送对这些管道化请求的响应。如果服务端在处理请求A时耗时比较长,那么后续请求的处理都会被阻塞住,这称为队头阻塞。HTTP/1.1管道解决了请求的队头阻塞,但是没有解决响应的队头阻塞。
- 队头阻塞。当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一同被阻塞,导致客户端一直请求不到数据,即队头阻塞
- HTTP是超文本传输协议,信息是明文传输,存在安全风险问题。HTTPS则解决HTTP不安全的缺陷,在TCP和HTTP之间加入了
SSL/TSL安全协议,使得报文能够加密传输 - HTTP连接建立相对简单,TCP三次握手之后便可进行HTTP报文传输。HTTPS在TCP三次握手之后,还需要进行SSL/TLS的握手过程,才可进行加密报文传输
- 两者的默认端口不一样,HTTP的默认端口号是80,HTTPS默认端口号是443
- HTTPS协议需要向CA(证书权威机构)申请数字证数,来保证服务器的身份是可信度。
HTTPS在HTTP与TCP层之间加入了SSL/TLS协议:信息加密、校验机制、身份证书
- 混合加密的方式实现信息的机密性,解决了窃听风险。
- 在通信建立前采用非对称加密的方式交换会话密钥,后续就不再使用非对称加密。非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交换问题但速度慢。
- 在通信过程中全部使用对称加密的会话密钥方式加密明文数据。对称加密只是用一个密钥,运算速度快,密钥必须保密,无法做到安全的密钥交换。
公钥私钥可以双向加解密
- 公钥加密,私钥解密。保证内容传输的安全
- 私钥加密,公钥解密。保证消息不会被冒充
- 摘要算法的方式来实现完整性,能够为数据生成独一无二的指纹,指纹用于检验数据的完整性。解决了篡改的风险。
- 通过摘要算法(哈希函数)计算内容的哈希值,然后通过私钥加密得到数字签名,将内容+数字签名一通发送出去。
- 接收方通过公钥解密出哈希值,与通过哈希运算得到的哈希值比较。相同就证明消息是完整的
- 将服务器公钥放入到数字证书中,解决了身份冒充的风险。
- 通过数字证书的方式确保服务器公钥的身份,解决冒充的风险
SSL/TSL协议基本流程:
- 客户端向服务器索要并验证服务器的公钥
- 双方协商产生会话密钥
- 双方采用会话密钥进行加密通信
TLS协议建立的详细流程:
ClientHello:首先,由客户端发起加密通信请求- 客户端支持的TLS协议版本,如
TLS 1.2版本 - 客户端生成的随机数(
Client Random),后面用于生成会话密钥条件之一 - 客户端支持的密码套件列表,如RSA加密算法
- 客户端支持的TLS协议版本,如
ServerHello:服务器收到客户端请求后,向客户端发出响应- 确认TLS协议版本,如果浏览器不支持,则关闭加密通信
- 服务器产生的随机数(
Server Random),也是后面用于产生会话密钥条件之一 - 确认的加密套件列表,如RSA加密算法
- 服务器的数字证书
- 客户端回应
- 客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的CA公钥,确认服务器的数字证书的真实性
- 客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,想服务器发送如下信息:
- 一个随机数(
pre-master key)。该随机数会被服务器公钥加密 - 加密通信算法改变通知,表示随后的信息都将用会话密钥加密通信
- 客户端握手结束通知,表示客户端的握手阶段已经结束
- 一个随机数(
- 服务器的最后回应
- 服务器收到客户端的第三个随机数(
pre-master key)之后,通过协商的加密算法,计算出本次通信的会话密钥 - 加密通信算法改变通知,表示随后的信息都将用会话密钥加密通信
- 服务器握手结束通知,表示服务器的握手已经结束。
- 服务器收到客户端的第三个随机数(
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着用双方协商的加密算法,各自生成本次通信的会话密钥
TLS在实现上分为握手协议和记录协议两层:
- TLS握手协议即前述TLS四次握手的过程,负责协商加密算法和生成对称密钥,后续使用此密钥来保护应用程序数据(HTTP数据)
- TLS记录协议负责保护应用程序数据并验证其完整性和来源,所以对HTTP数据加密是使用记录协议。负责消息(HTTP数据)的压缩,加密及数据的认证
HTTPS协议本身到目前为止没有任何漏洞,即使进行中间人攻击,本质上还是利用了客户端漏洞(用户点击继续访问或者被恶意导入伪造的根证书),并不是HTTPS不够安全。
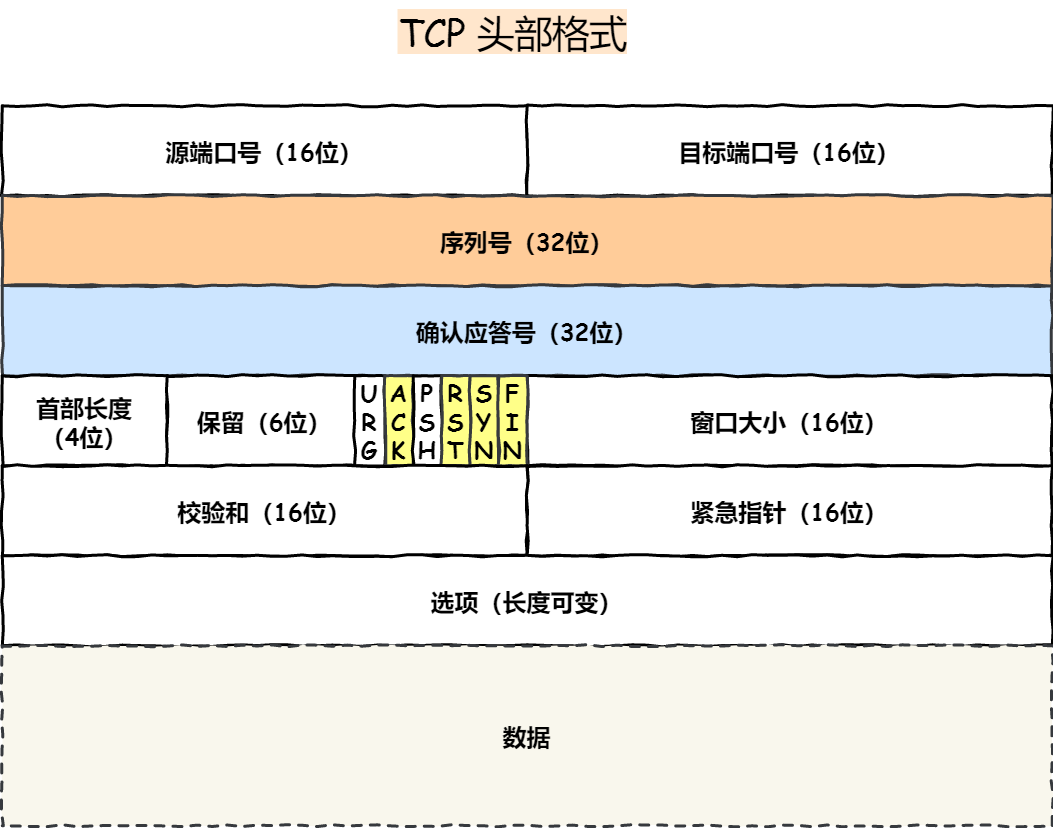
序列号:在建立连接时由计算机生成的随机数作为其初始值,通过SYN包传给接收端主机,每发送一次数据,就累加一次该数据字节数的大小。用来解决网络包乱序问题
确认应答号:指下一次期望收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题
控制位:
ACK(Acknowledgment,确认标志):该位为1时,确认应答的字段变为有效,TCP规定除了最初建立连接的SYN包之外该位必须设置为1RST(Reset,复位标志):表示TCP连接中出现异常必须强制断开连接SYN(Synchronize,同步标志):表示希望建立连接,并在其序列号的字段进行序列号初始值的设定FIN(Finish,结束标志):表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位为1的TCP段。
TCP是一个工作在传输层的可靠数据传输的服务,它能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
TCP是面向连接的、可靠的、基于字节流的传输层控制协议。
- 面向连接:一定是一对一才能连接,不能像UDP协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的
- 可靠的:无论网络链路出现了怎么样的链路变化,TCP可以保证一个报文一定能够达到接收端
- 字节流:
Connections: The reliability and flow control mechanisms described above require that TCPs initialize ans maintain certain status information for each data stream. The combination of this information, including sockets, sequence numbers, and window sizes, is called a connections.
连接:用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括socket、序列号和窗口大小称为连接
建立一个TCP连接需要客户端与服务端达成上述三个信息的共识:
Socket:由IP地址和端口号 组成序列号:用来解决乱序问题等窗口大小:用来做流量控制
TCP四元组可以唯一的确定一个连接,四元素包括如下:
- 源地址
- 源端口号
- 目的地址
- 目的端口
源地址和目的地址的字段(32位)是在IP头部中,作用是通过IP协议发送报文给对方主机。源端口和目的端口的字段(16位)是在TCP头部中,作用是告诉TCP协议应该把报文发给哪个进程。
一个IP的服务端监听了一个端口,它的TCP的最大连接数是多少?
服务端通常固定在某个本地端口上监听,等待客户端的连接请求
因此,客户端IP和端口是可变的,其理论值计算公式:$最大TCP连接数 = 客户端IP数 × 客户端的端口数$
服务端最大并发TCP连接数会受以下 因素影响:
- 文件描述符限制:每个TCP连接 都是一个文件,如果文件描述符被沾满了,会发生
Too many open files - 内存限制:每个TCP连接都要占用一定内存,操作系统的内存是有限的,如果内存资源被占满后,会发生PPM
UDP不提供复杂的控制机制,利用IP提供面向无连接的通信服务
UDP协议非常简单,头部只有8个字节(64位):源端口号(16位)、目标端口号(16位)、包长度(16位)、校验和(16位)
TCP和UDP区别:
- 连接:
- TCP是面向连接的传输层协议,创数数据前先建立连接
- UDP是不需要连接,即可传输数据
- 服务对象
- TCP是一对一的两点服务,即一条连接只有两个端点
- UDP支持一对一、一对多、多对多的交互通信
- 可靠性
- TCP是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达
- UDP是尽最大努力交互,不保证可靠交付数据。
- 拥塞控制、流量控制
- TCP有拥塞控制和流量控制机制,保证数据传输的安全性
- UDP则没有,即使网络非常堵塞,也不会影响UDP的发送速率
- 首部开销
- TCP首部较长,会有一定的开销
- UDP首部只有8个字节,并且是固定不变的,开销较小
- 传输方式:
- TCP是流式传输,没有边界,但保证顺序和可靠
- UDP是一个包一个包的发送,是有边界的,但可能会丢包和乱序
- 分片不同
- TCP的数据包大小如果大于MSS大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装TCP数据包。如果中途丢失了一个分片,只需要传输丢失的这个分片
- UDP的数据大小如果大于MTU大小,则会在IP层进行分片,目标主机收到后,在IP层组装完数据,接着再传给传输层
TCP和UDP应用场景
- 由于TCP是面向连接,能够保证数据的可靠交付
FTP文件传输HTTP/HTTPS
- UDP面向无连接,可以随试发送数据,再加上UDP本身的处理既简单又高效
- 包总量较少的通信,如
DNS、SNMP - 视频、音频等多媒体通信
- 广播通信
- 包总量较少的通信,如
- 可以
传输层的端口号的作用,是为了区分同一个主机上不同应用程序的数据包。而传输层的两个协议TCP和UDP,在内核中是两个完全独立的软件模块。
当主机收到数据包后,可以在IP包头的协议号字段直到该数据包是TCP/UDP,所以可以根据这个信息确定发给哪个模块(TCP/UDP)处理,送给TCP/UDP模块的报文根据端口号确定送给哪个应用程序处理
TCP是面向连接的协议,所以使用TCP前必须先建立连接,而建立连接是通过三次握手来进行的。
TCP首部结构(20字节基础部分+可选选项)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window |
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options (可选,最多40字节) |
| ... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
 |
 |
 |
|---|
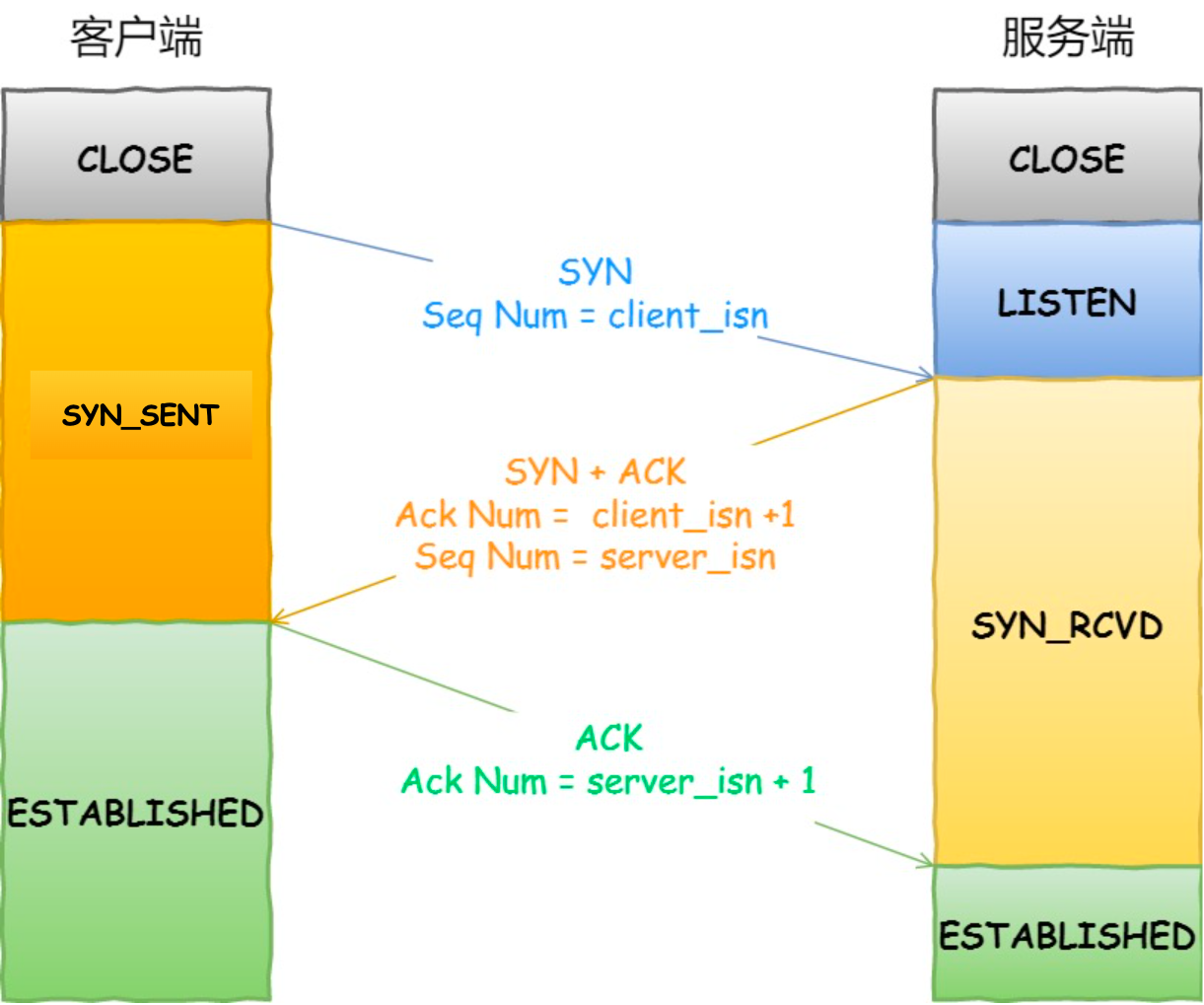
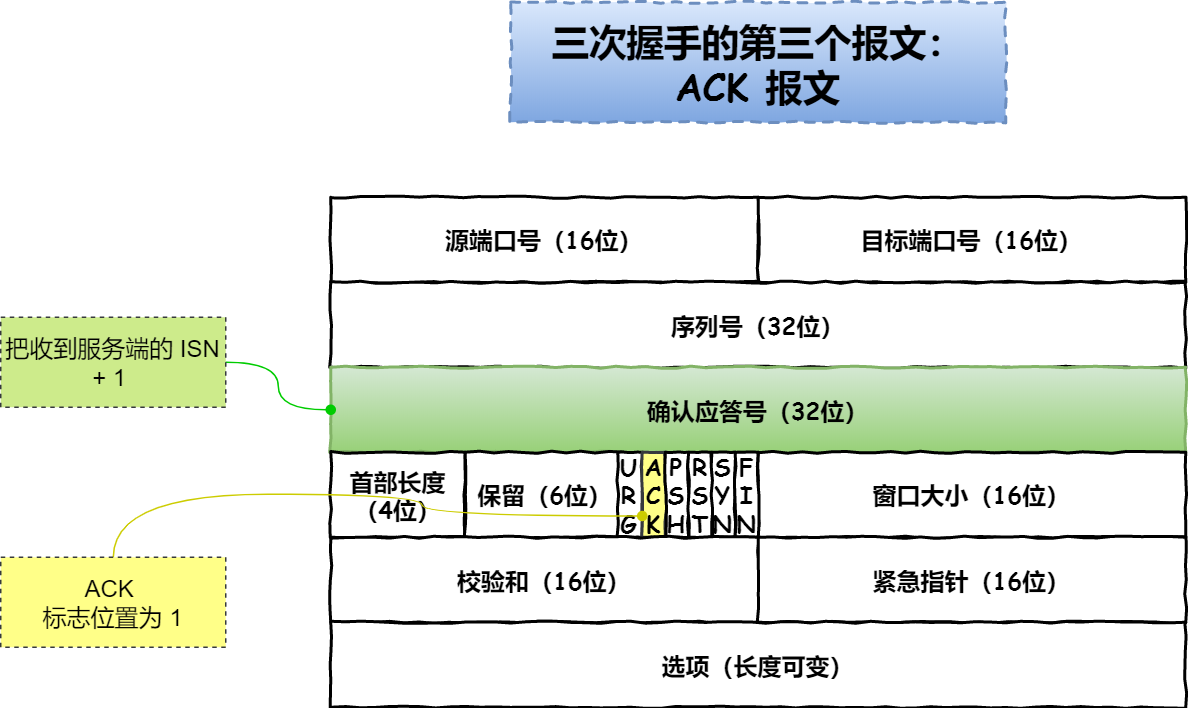
- 一开始,客户端和服务端都处于
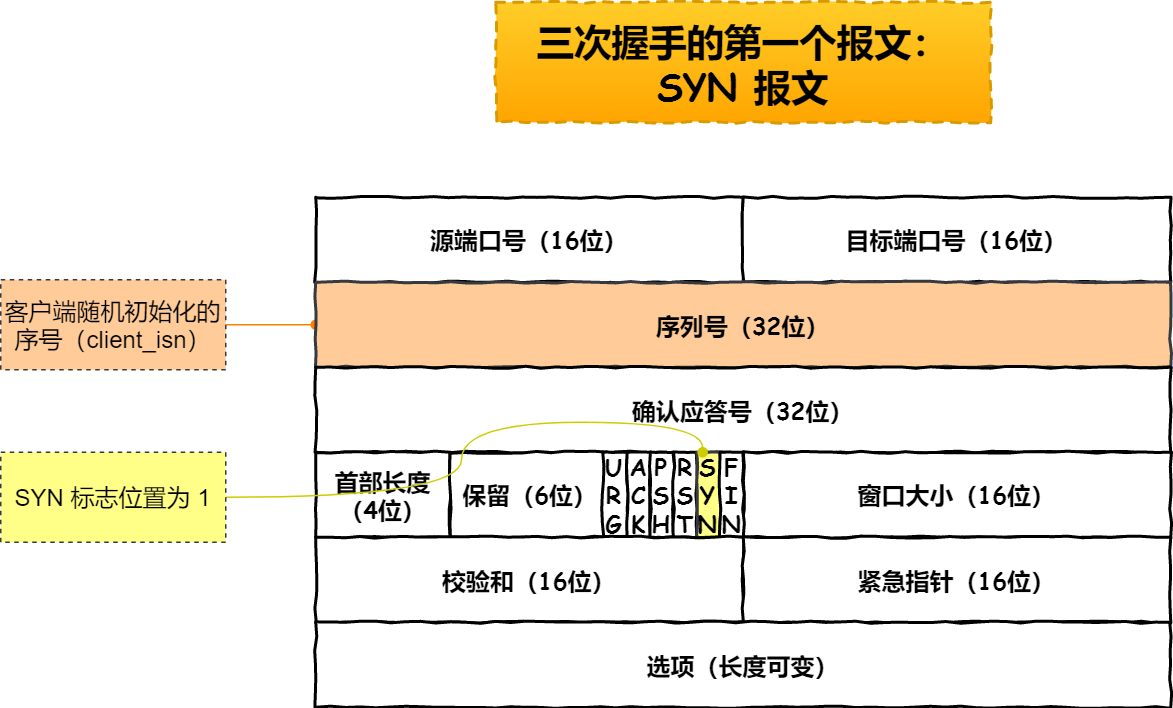
CLOSE状态。先是服务端主动监听某个端口,处于LISTEN状态 - 客户端会随机初始化序号(
client_isn),将此序号置于TCP首部的序号字段中,同时把SYN标志位置为1,表示SYN报文。接着把第一个SYN报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于SYN_SENT状态 - 服务端收到客户端的
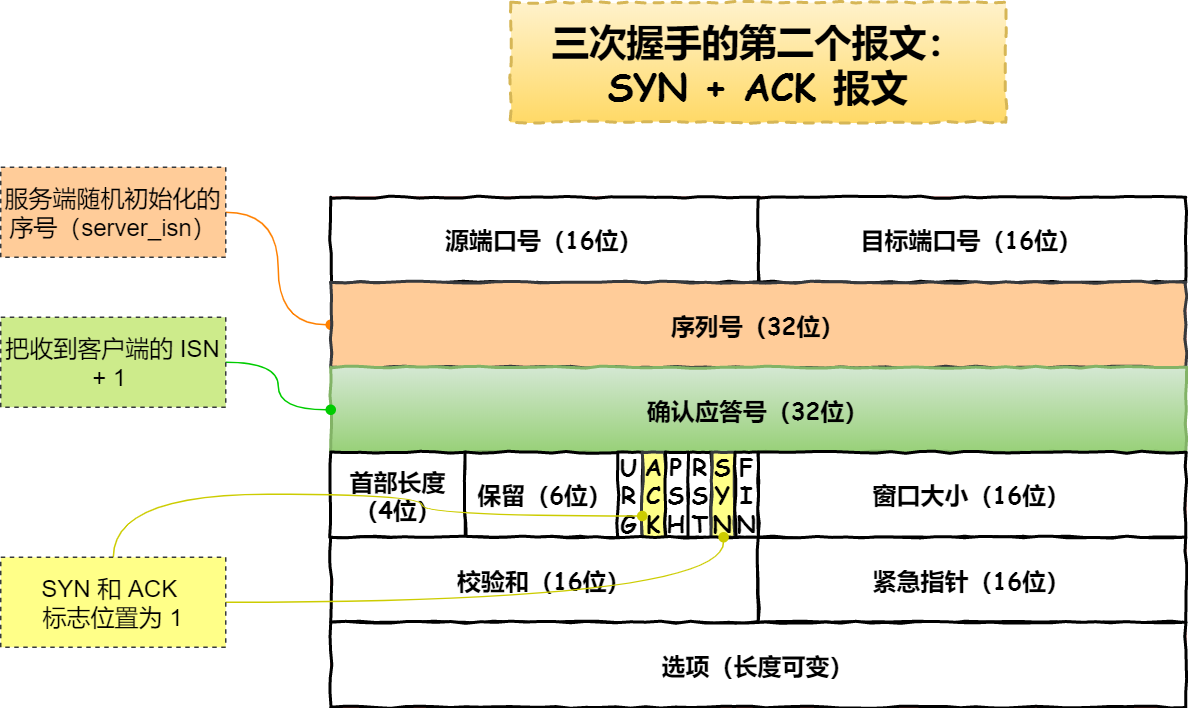
SYN报文后,首先把服务端也随机初始化自己的序号(server_isn),将此序号填入TCP首部的序号字段中,其次TCP首部的确认应答号字段填入client_isn + 1,接着把SYN和ACK标志位置为1。最后把该报文发送给客户端,该报文也不包含应用层数据,之后服务端处于SYN_RCVD状态。 - 客户端收到服务端报文之后,还要向服务端回应最后一个应答报文,首先应答报文TCP首部
ACK标志位置为1,其次确认应答号字段填入server_isn + 1,最后把报文发送给服务端,这次报文可以携带客户端到服务端的数据,之后客户端处于ESTABLISHED状态。 - 服务端收到客户端的应答报文之后,也进入
ESTABLISH状态
第三次握手是可以携带数据的,前两次握手是不可以携带数据的
如何在Linux系统中查看TCP状态:
netstat -napt

TCP连接:用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括Socket、序列号和窗口大小称为连接。
IP在TCP/IP参考模型处于第三层,即网络层
网络层的主要作用是:实现主机与主机之间的通信,也叫点对点(end to end)通信
网络层与数据链路层有什么关系?
- IP的作用是主机之间通信用的,而MAC的作用则是实现直连的两个设备之间的通信,而IP则负责在没有直连的两个网络之间进行通信传输。
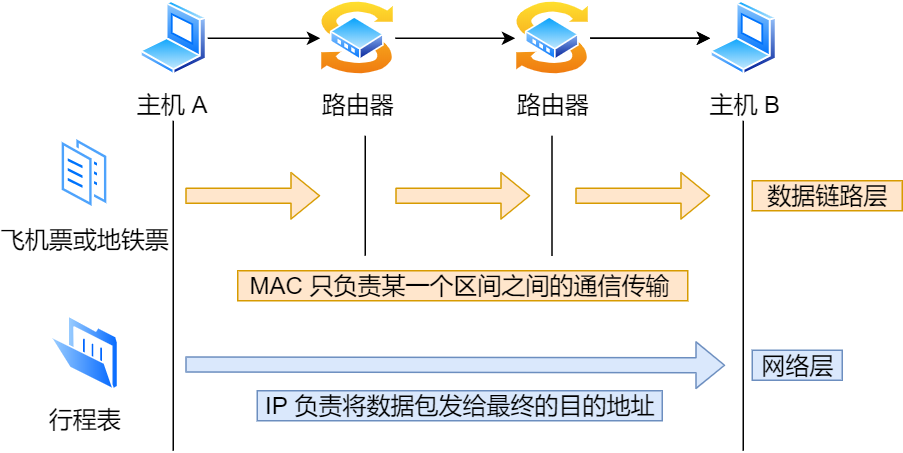
计算机网络中也需要数据链路层和网络层这个分层才能实现向最终目标地址的通信。
在网络中数据包传输,源IP地址和目标IP地址在传输过程中是不会变化的,只有源MAC地址与目标MAC地址一直在变化。
IP地址(IPv4)由32位正整数来标识,IP地址在计算机是以二进制的方式处理的,为了方便记忆采用了点分十进制的标记方式,即将32位IP地址以每8位为组,共分为4组,每组以.隔开,再将每组转换成十进制。
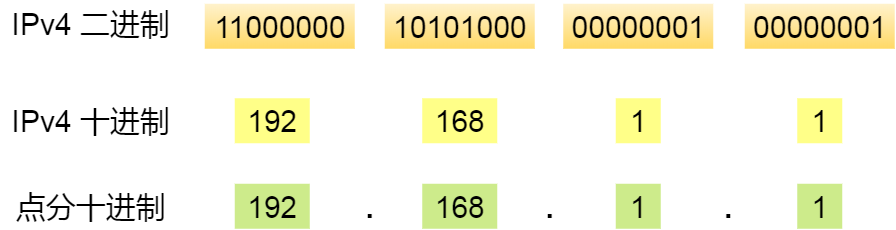
IP地址最大值是$2^{32}=4294967296$,约43亿个
IP地址分类成了5类,分别是A类、B类、C类、D类、E类。
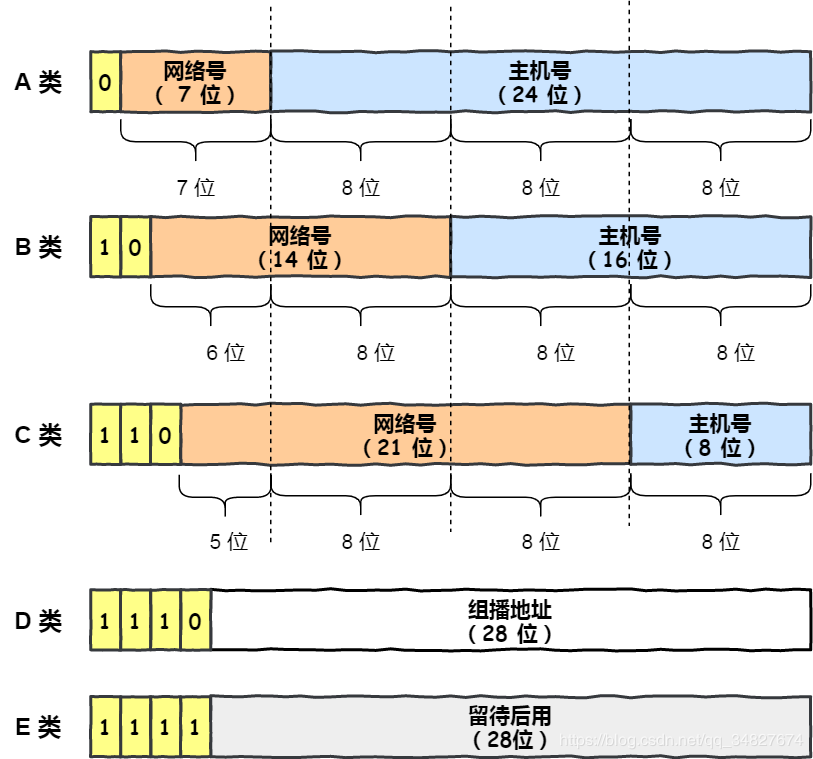
对于ABC类IP主要分为两个部分,分别是网络号和主机号,每类下最大主机个数为$2^n-2$,n表示主机位数。
- 减2是为去掉主机号全为0和全为1的地址。
- 主机号全为1指定某个网络下的所有主机,用于广播
- 主机号全为0指定某个网络
广播地址用于在同一个链路/子网中相互连接的主机之间发送数据包。
- 在本网络内广播的叫做本地广播。
- 在不同网络之间的广播叫做直接广播。
D类和E类地址没有主机号,不可用于主机IP,D类常用于多播,E类是预留的分类,暂时未使用
- 多播用于将包发送给特定组内的所有主机
- 广播无法穿透路由,若想给其它网段发送同样的包,就可以使用穿透路由的多播
- 多播使用的D类地址,其前四位是
1110就表示多播地址,剩余28位是多播的组编号
IP分类的优点就是简单明了、选路(基于网络地址)简单。
IP分类的缺点:
- 同一个网络下没有地址分层,缺少地址的灵活性
- 不能很好的与现实网络匹配。如C类地址能包含的最大主机数254太少,而B类地址能包含的最大主机数6万多太多,一般企业达不到这个规模
- 以上两个缺点,都可以在
CIDR无分类地址解决
无分类地址CIDR不再有分类的概念,32比特的IP地址被划分为两部分,前面是网络号,后面是主机号
表示形式:a.b.c.d/x,其中/x表示前x位属于网路号,x的范围是0~32
示例:10.100.122.2/24,/24表示前24位是网络号,剩余的8位是主机号
为什么要分离网络号和主机号?
- 提高路由效率。路由器只需记录网络号,而非每个主机IP
- 分层寻址。路由器通过网络号进行寻址转发,简化路由
- IP地址复用。通过子网划分和NAT环节IPv4短缺问题
- 广播隔离。限制广播流量范围,提升网络性能。
子网划分
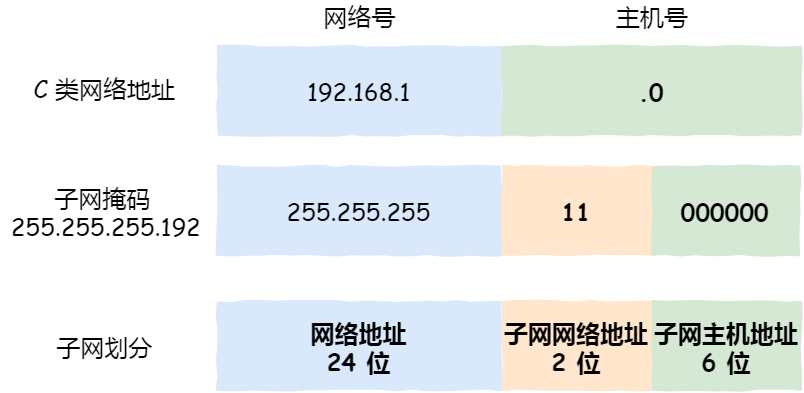
子网划分实际上是将主机地址划分为两个部分:子网网络地址和子网主机地址

例如,对于C类地址192.168.1.0,前24位是网络号,最后8位是主机号。通过子网掩码255.255.255.192对其进行子网划分,可知从8位主机号借用2位作为子网号。由于子网网络地址被划分为2位,那么子网地址就有4个,分别是00、01、10、11。
- 公有IP地址是有个组织(ICANN)统一分配的,并且公有IP地址基本上要在整个互联网范围内保持唯一。
- 私有IP地址允许组织内部的IT人员自己管理、自己分配,而且可以重复
IP地址的网络地址这一部分是用于路由控制。
路由控制表中记录着网络地址与下一步应该发送至路由器的地址,在主机和路由器上都会有各自的路由器控制表。
在发送IP包时,首先要确定IP包首部中的目标地址,再从路由控制表中找到与该地址具有相同网络地址的记录,根据记录将IP包转发给相应的下一个路由器。如果路由控制表中存在多条相同网络地址的记录,就选择相同位数最多的网络地址,也就是最长匹配。
回环地址
回环地址是在同一台计算机上的程序之间进行网络通信时所使用的一个默认地址。
计算机使用一个特殊的IP地址127.0.0.1作为环回地址,与该地址具有相同意义的是一个叫做localhost的主机名。使用这个IP或主机名,数据包不会流向网络。
以太网的最大传输单元MTU是1500字节。当IP数据包大小大于MTU时,IP数据包就会被分片。经过分片之后的IP数据包在被重组时,只能由目标主机进行,路由器是不会进行重组的。
在分片传输中,一旦某个分片丢失,则会造成整个IP数据包报废,所以TCP引入了MSS也就是在TCP层进行分片不由IP层分片,那么对于UDP,我们尽量不要发送一个大于MTU的数据包。
- TCP MSS是传输层的主动优化机制,通过协商分端大小避免IP分片
- IP MTU分片是网络层的被动补救机制,在数据包过大时强制拆分,但效率较低
IPv4的地址是32位的,大约可以提供42亿个地址。IPv6的地址是128位的,可以保证地球上的每粒沙子都被分配一个IP地址。
IPv6的亮点:
- IPv6可自动配置,即使没有DHCP服务器也可以实现自动分配IP地址,真实便捷到即插即用
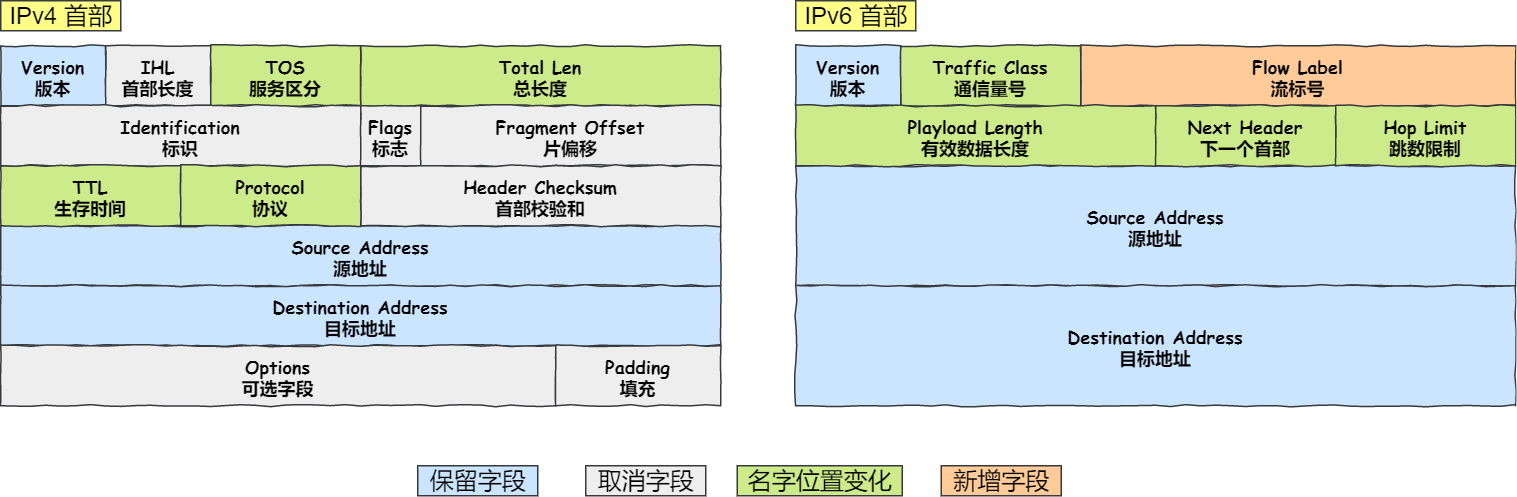
- IPv6包头包首部长度采用固定的值40字节,去掉了包头校验和,简化了首部结构,践情了路由器负荷,大大提高了传输的性能。
- IPv6有应对伪造IP地址的网络安全功能以及防止线路窃听的功能,大大提升了安全性。
IPv6相比IPv4的首部改进:
- 取消了首部校验和字段。因为在数据链路层和传输层都会校验,因此IPv6取消了IP的校验
- 取消了分片/重新组装相关字段。IPv6不允许中间路由器进行分片与重组
- 取消选项字段。删除该选项字段使的 IPv6 的首部成为固定长度的
40字节。
DNS中的域名使用句点.来分隔,比如www.server.com,这里的据点代表了不同层次之间的界限。在域名中,越靠右的位置表示其层级越高。
- 根DNS服务器
.:根域的DNS服务器信息保存在互联网中所有的DNS服务器中 - 顶级域DNS服务器
com - 权威DNS服务器
server.com
域名解析流程
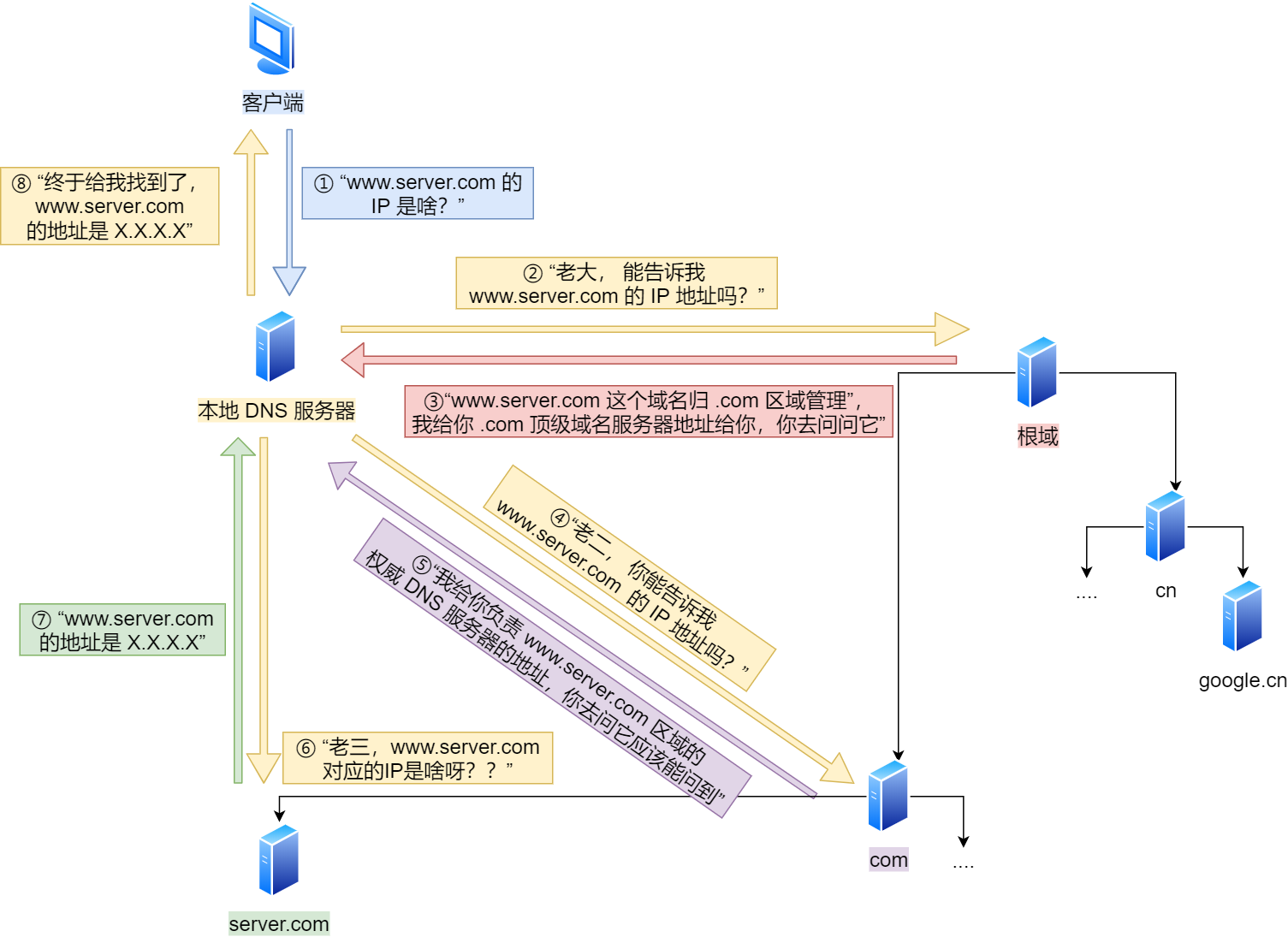
浏览器首先看一下自己的缓存里有没有,如果没有就向操作系统的缓存要,还没有就检查本机域名解析文件hosts,如果还没有,就会DNS服务器进行查询,查询过程如下:
- 客户端首先会发出一个DNS请求,问
www.server.com的IP是啥,并发给本地DNS服务器(即客户端的TCP/IP设置中填写的DNS服务器地址) - 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到
www.server.com,则它直接返回IP地址。如果没有,本地DNS会去问根域服务器,一直顺藤摸瓜找到...
在传输一个IP数据包的时候,确定了源IP地址和目标IP地址后,就会通过主机路由表确定IP数据包的下一跳。然后,网络层的下一层是数据链路层,还要直到下一跳的MAC地址。
由于主机的路由表中可以找到下一跳的IP地址,所以可以通过ARP协议,求得下一跳得MAC地址。
ARP是借助ARP请求与ARP响应两种类型的包确定MAC地址的
- 主机通过广播发送ARP请求,包中包含了想要知道MAC地址的主机的IP地址
- 当同个链路的所有设备收到ARP请求时,会去拆开ARP请求包里的内容,如果ARP请求包中的目标IP地址与自己的IP地址一致,则这个设备就将自己的MAC地址塞入ARP响应包返回给主机
- 操作系统通常会把第一次通过ARP获取的MAC地址缓存起来
ARP协议是已知IP地址请求MAC地址,RARP协议正好相反,已知MAC地址求IP地址
我们的电脑通常都是通过DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)动态获取IP地址,大大省去了配IP信息繁琐的过程。基于UDP协议,客户端端口68,服务端端口67:
- DHCP客户端:
0.0.0.0:68——255.255.255.255:67- 发送
DHCP DISCOVER - 事务ID
- 发送
- DHCP服务端: DHCP服务地址->
255.255.255.255:68- 发送
DHCP OFFER - 事务ID
- DHCP服务器地址:IP地址、子网掩码、地址租期、默认网关、DNS服务器
- 发送
- DHCP客户端:
0.0.0.0:68——255.255.255.255:67- 发送
DHCP REQUEST - 事务ID
- 接受租约的IP地址、租期等信息、DHCP服务器地址
- 发送
- DHCP服务端: DHCP服务地址->
255.255.255.255:68- 发送
DHCP ACK - 事务ID
- DHCP服务器地址、确认配置信息(IP地址、租期等)
- 发送
DHCP交互过程中,全程都是使用UDP广播通信。
为了解决DHCP客户端和服务端不在同一个网络,而路由器不能转发广播的问题。
- 出现了DHCP中继代理,对不同网段的IP地址分配也可以由一个DHCP服务器统一进行管理。
网络地址转换NAT来缓解IPv4地址耗尽问题,简单来说NAT就是同个公司、家庭、教室内的主机对外部通信时,把私有IP地址转换成公有IP地址。
普通NAT的话,N个私有IP对应N个公有IP地址,并没有环节。
NAPT网络地址与端口转换:把IP地址+端口号一起进行转换。比如有两个客户端192.168.1.10和192.168.1.11同时与服务器183.232.231.172进行通信,并且这两个客户端的本地端口都是1025。两个私有IP地址都转换IP地址为公有地址120.229.175.121,但是以不同的端口号作为区分
由于NAT/NAPT都依赖于自己的转换表,因此会有以下问题:
- 外部无法主动与NAT内部服务建立连接,因为NAPT转换表没有转换记录。
- 转换表的生成与转换操作都会产生性能开销
- 通信过程中,如果NAT路由器重启了,所有的TCP连接都将被重置。
解决方法:
- 使用
IPv6,IPv6可用范围非常大,以至于每台设备都可以配置一个公有IP地址,就不用搞那么多花里胡哨的东西了 - NAT穿透技术
- 当网络应用程序主动发现自己位于NAT设备之后,并且会主动获得NAT设备的公有IP,并未自己建立端口映射条目,就不用像之前由NAT设备来建立映射。
Internet Control Message Protocal,互联网络报文协议:
ICMP主要的功能包括:确认IP包是否成功送达目标地址、报告发送过程中IP包被废弃的原因和改善网络设置等
ICMP大致可以分为两大类:
- 用于诊断的查询消息,也就是查询报文类型
- 通知出错原因的错误消息,也就是差错报文类型
IGMP是因特网组管理协议,工作在主机(组播成员)和最后一跳路由之间
ping是基于ICMP协议工作的,ICMP全称是Interbet Control Message Protocol,即互联网控制报文协议
控制:在网络包传输过程中,会遇到各种问题。当遇到问题时,需要报告问题信息,这样才可以调整传输策略,以此来控制整个局面。
ICMP主要的功能包括:确认IP包是否成功送达目标地址、报告发送过程中IP包被废弃的原因和改善网络设置等。
ICMP通知消息使用IP进行发送,ICMP报文是封装在IP包里面的,工作在网络层,是IP协议的助手
ICMP包头的类型字段,大致可以分为两大类:
- 一类是用于诊断的消息,也就是查询报文类型
- 另一类是通知出错原因的错误消息,也就是差错报文类型


回送消息用于进行通信的主键或路由器之间,判断所发送的数据包是否已经成功达到对端的一种消息,ping命令就是利用这个消息实现的。
可以向对端主机发送回送请求的消息(ICMP Echo Request Message,类型8),也可以接收对端主机发回来的回送应答消息(ICMP Echo Reply Message,类型0)
常用的ICMP差错报文有:
- 目标不可达消息——类型为3
- 原点抑制消息——类型为4
- 重定向消息——类型5
- 超时消息——类型11
- IP包中有一个
TTL字段(The Time to Live,生存周期),它的值随着每经过一次路由器就会减一,直到减到0时该IP包被丢弃。 - 设置IP包生存周期的主要目的是,为了在路由控制遇到问题发生循环情况时,避免IP包在网络中无休止的被转发
- IP包中有一个
对于最简单的情况,同一个子网下的主机A和主机B,主机A执行ping主机B后:
ping命令执行的时候,源主机首先会构建一个ICMP回送请求消息数据包。
ICMP数据包内包含多个字段,最终的是两个:
- 类型:对于回送请求消息而言,该字段为8
- 序号:主要用于区分连续
ping的时候发送出的多个数据包。每发出一个请求数据包,序号会自动加1 - 为了计算往返时间
RTT,它会在报文的数据部分插入发送时间
然后,由ICMP协议将这个数据包连同目标地址192.168.1.2一起交给IP层。IP层构建IP数据包

接下来,数据链路层加入MAC头。如果在本地ARP映射表中查找出IP地址所对应的MAC地址,则可以直接使用;如果没有,则需要发送ARP协议查询MAC地址。获取MAC地址后,由数据链路层构建数据帧

主机B收到这个数据帧后,先检查它的目的MAC地址,并和本机MAC地址对比,如符合,则接收,否则则舍弃。
主机B会构建一个ICMP回送响应消息数据包,类型为0,序号为请求数据包中的序号,然后再发送给主机A
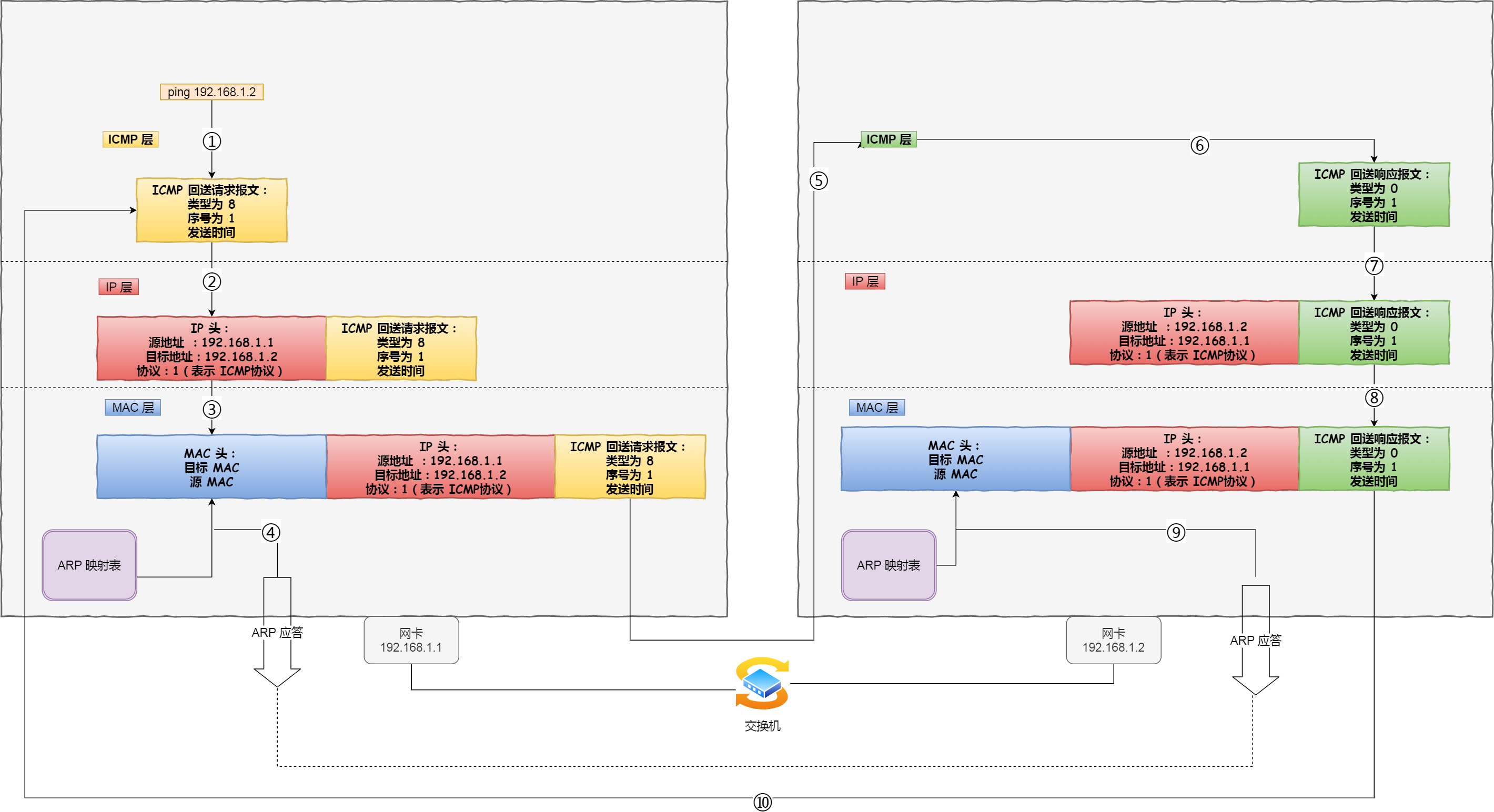
traceroute作用一:故意设置特殊的TTL,来追踪去往目的地时沿途经过的路由器
traceroute 192.168.1.100原理:利用IP包的生存期限从1开始按照顺序递增的同时发送UDP包,强制接收ICMP超时消息的一种方法
通过这样,traceroute就可以拿到所有的路由器IP
traceroute在发送UDP包时,会填入一个不可能的端口号值作为UDP的目标端口号,当目的主机收到UDP包后,会返回ICMP差错报文消息,但这个差错报文消息的类型是端口不可达。所以,当差错报文类型是端口不可达时,说明发送方发出的UDP包达到了目的主机。
traceroute作用二:故意设置不分片,从而确定路径的MTU
127.0.0.1是个IPv4地址,IPv4地址有32位,一个字节有8位,共4个字节
其中127开头的都属于回环地址,也是IPV4的特殊地址。
IPv4是以8位一组,每组之间用.号隔开。回环地址127.0.0.1IPv6是以16位一组,每组之间用:隔开。如果全是0,可以省略不写。回环地址:::1
ping是应用层命令,尝试发送一个小小的消息到目标及机器上,判断目的机器是否可达,即判断目标机器网络是否能连通。
ping应用的底层,用的是网络层的ICMP协议。
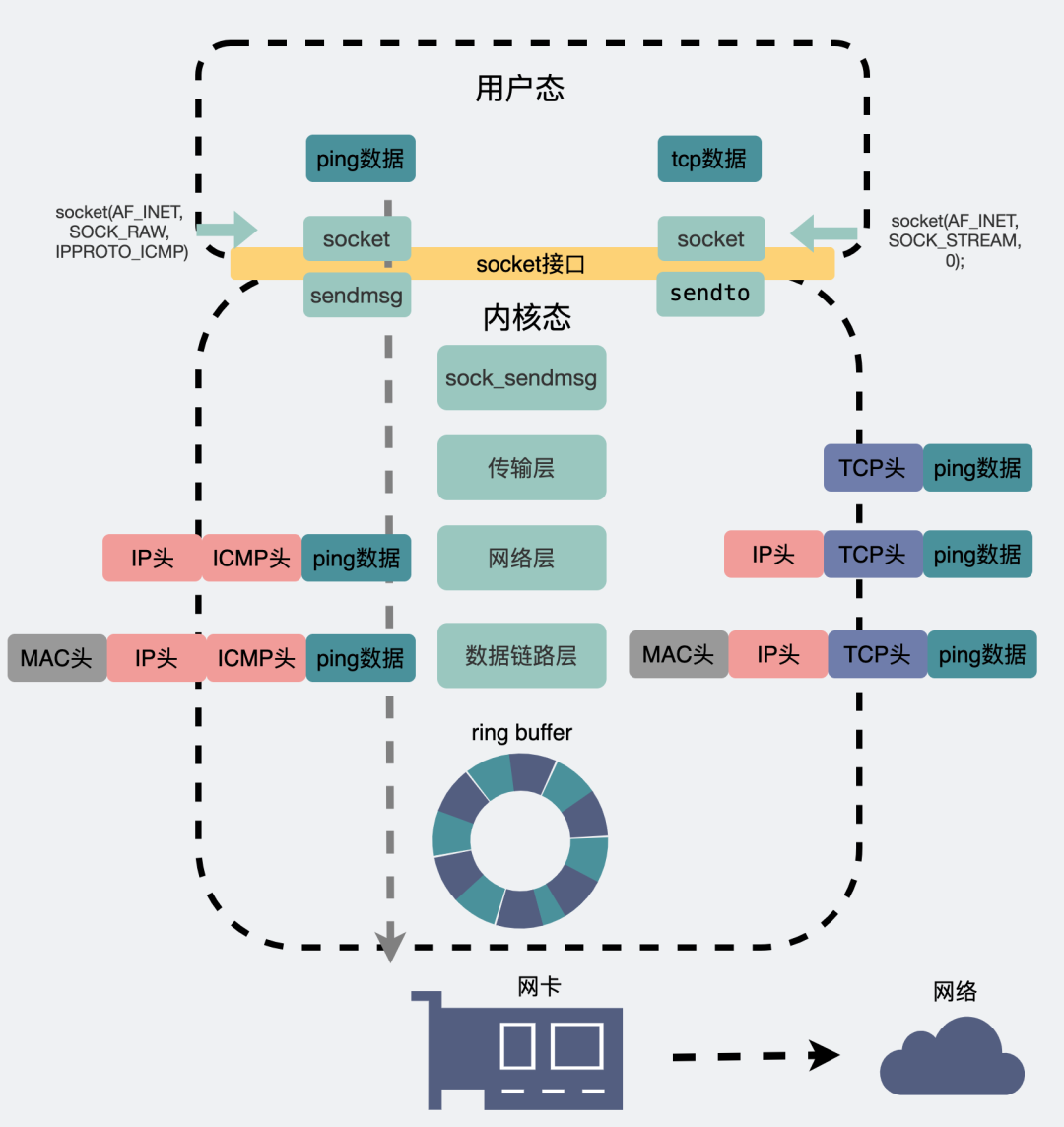
linux里万物皆文件,那么要发送消息的目的地,也是个文件,这里就是socket的概念
要使用socket,那么首先需要创建它
TCP
- 在TCP传输中创建的方式是
socket(AF_INET, SOCK_STREAM, 0),其中AF_INET表示将使用IPv4里的host:port的方式去解析传入的网络地址,SOCK_STREAM在指使用面向字节流的TCP协议,工作在传输层。 - 创建号socket后,就可以把要传输的数据写到这个文件里。调用socket的
sendto接口的过程,进程会从用户态进入到内核态,最后会调用到sock_sendmsg方法。 - 然后进入到传输层,带上TCP头,网络层带上IP头,数据链路层带上MAC头等一系列操作后。进入到网卡的发送队列
ring buffer,顺着网卡就发出去了
PING
整个过程跟TCP类似,差异的地方主要在于,创建socket的时候用的是socket(AF_INET, SOCK_RAW, IPPROTO_ICMP),SOCK_RAW是原始套接字,工作在网络层
ping在进入内核态最后也是调用的socket_sendmsg方法,进入到网络层后加上ICMP和IP头,数据链路层加上MAC头,也是顺着网卡发出。
如上,ping最后是通过网卡将数据发出的。
断网下网卡已经不工作了,ping回环地址却一切正常
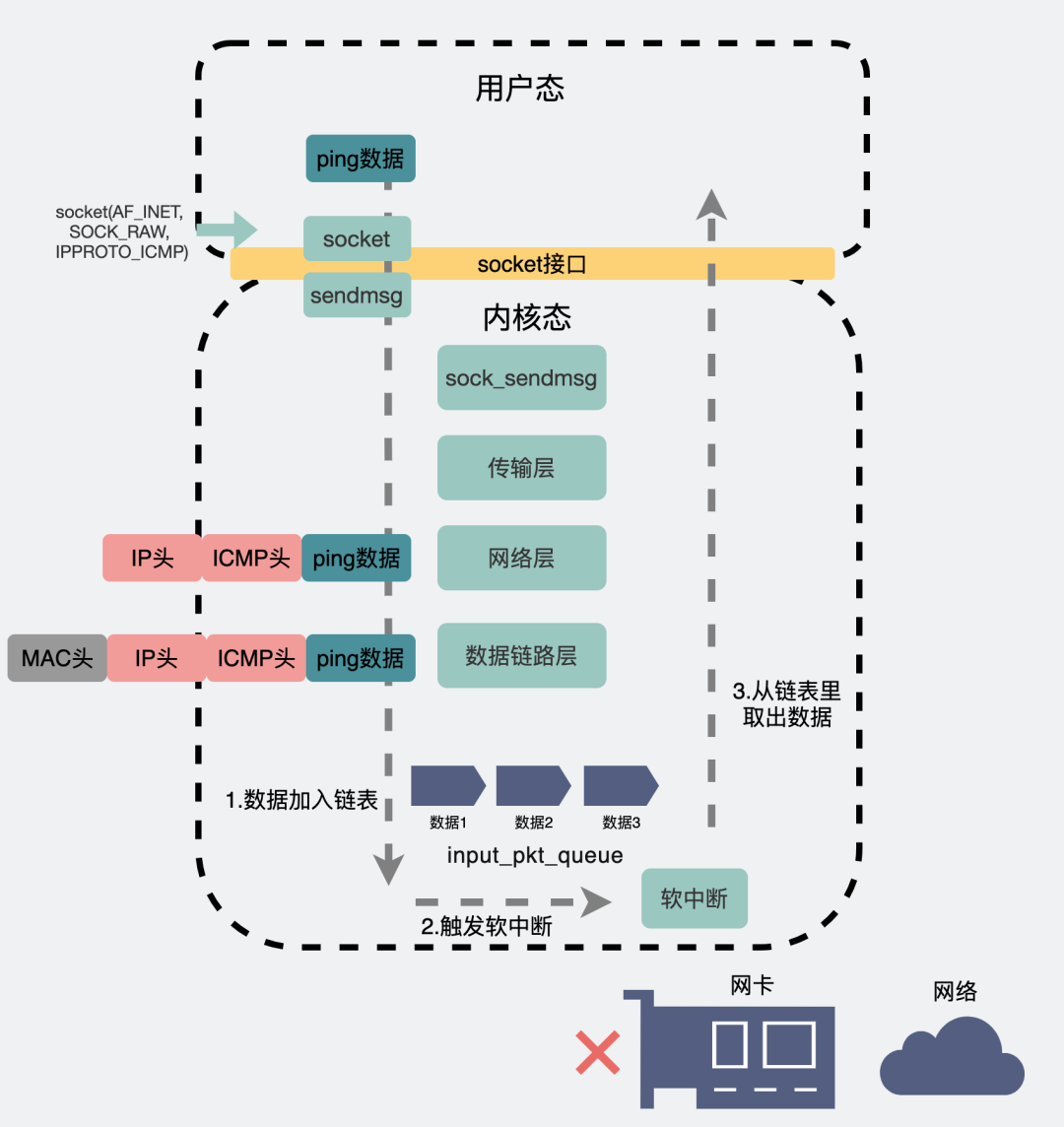
从应用层到传输层到网络层,与ping外网时一样。当了网络层,系统会根据目的IP,在路由表中获取对应的路由信息,而这其中就包含哪个网卡把消息发出。
- 当发现目标IP是外网时,会从真网卡发出
- 当发现目标IP是回环地址时,就会选择本地网卡
本地网卡其实就是个假网卡,不像“真网卡”那样有个ring buffer什么的,假网卡会把数据推到一个叫input_pkt_queue的链表中。这个链表,其实是所有网卡共享的,上面挂着发给本机的各种消息。消息被发送到这个链表后,会再触发一个软中断。
ping 127.0.0.1回环地址和ping 本机IP一样,相关的数据都是走的本地网卡,并不会发送到网络中
localhost是一个域名,在/etc/hosts文件下默认配置为1270.0.0.1
0.0.0.0在IPv4中表示的是无效的目标地址。
当启动服务器时,一般会监听listen一个IP和端口等待客户端的连接。
如果此时listen的是本机的0.0.0.0,那么它表示本机上的所有IPv4地址。
/* Address to accept any incoming message */
#define INADDR_ANY ((unsigned long int) 0x00000000) /* 0.0.0.0 */但是,客户端connect时,不能使用0.0.0.0,必须知名要连接哪个服务器IP
127.0.0.1是回环地址,localhost是域名,但默认等于127.0.0.1ping回环地址和ping本机地址,是一样的,走的是lo0回环网卡,会经过网络层和数据链路层等逻辑,但是最后将数据插入到一个链表后就软中断通知ksoftirqd来进行收数据的逻辑,不会出网络。所以断网了也能ping通回环地址- 如果服务器
listen的是0.0.0.0,那么此时用127.0.0.1和本机地址都可以访问到服务
- 确定dp数组以及下标i的含义
- 确定递推公式
- 初始化递推边界
- 确定遍历顺序
- 带入示例进行推到
物品只有一个,选或不选
物品有无限个,
完全背包问题:拆分数字可以重复利用
class Solution {
public int integerBreak(int n) {
// dp[i] 表示将整数 i 拆分后的乘积最大值
int[] dp = new int[n + 1];
// dp[i] = max(dp[i], max(j * (i - j), j * dp[i - j]));
dp[1] = 1;
dp[2] = 1;
for (int i = 3; i <= n; i++) {
for (int j = 1; j <= i - j; j++) {
dp[j] = Math.max(dp[j], Math.max(j * (i - j), j * dp[i - j]));
}
}
return dp[n];
}
}class Solution {
public int numTrees(int n) {
// 1. 定义:dp[i] 表示有 i 个不同元素的BST的个数
int[] dp = new int[n + 1];
// 2. 递推公式:dp[i] += dp[j - 1] * [i - j]; 表示以 j 为根节点的BST个数
// 3. 初始化
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
for (int j = 1; j <= i; j++) {
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
}01背包(恰好装满)
public class Solution416 {
public boolean canPartition(int[] nums) {
int t = 0;
for (int x : nums) {
t += x;
}
if (t % 2 == 1) {
return false;
}
t /= 2;
// dp[i] 表示容量为i时能否恰好装满
boolean[] dp = new boolean[t + 1];
// dp[j] = j >= x && dp[j - x] || dp[j]
dp[0] = true; // 初始化:都不选可以装满0
int s = 0; // 前缀和
for (int x : nums) {
s += x; // [0, i] 子序列的所有元素和 <= s
for (int j = Math.min(s, t); x <= j; j--) {
dp[j] = dp[j] || dp[j - x];
}
if (dp[t]) {
return true;
}
}
return dp[t];
}
}每个物品只有一个,背包是二维的
class Solution {
public int findMaxForm(String[] strs, int m, int n) {
// 1. 定义:dp[i][j] 表示最多有i个0和j个1的strs最大子集的大小是 dp[i][j]
int[][] dp = new int[m + 1][n + 1];
for (String s : strs) {
int[] cnt = cntOneAndZero(s);
for (int i = m; i >= cnt[0]; i--) {
for (int j = n; j >= cnt[1]; j--) {
dp[i][j] = Math.max(dp[i][j], dp[i - cnt[0]][j - cnt[1]] + 1);
}
}
}
return dp[m][n];
}
private int[] cntOneAndZero(String s) {
int cnt0 = 0;
int cnt1= 0;
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) == '0') {
cnt0++;
} else {
cnt1++;
}
}
return new int[] {cnt0, cnt1};
}
}纯完全背包问题
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
int[] weight = new int[n];
int[] value = new int[n];
for (int i = 0; i < n; i++) {
weight[i] = sc.nextInt();
value[i] = sc.nextInt();
}
// 1. 定义:dp[i][j] 表示从下标[0, i]的物品,每个物品可以取无限次,放进容量为j的背包,价值总和最大是多少
int[][] dp = new int[n + 1][m + 1];
// dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]);
for (int i = 0; i < n; i++) {
for (int j = 1; j <= m; j++) {
if (weight[i] <= j) {
dp[i + 1][j] = Math.max(dp[i][j], dp[i + 1][j - weight[i]] + value[i]);
} else {
dp[i + 1][j] = dp[i][j];
}
}
}
System.out.println(dp[n][m]);
}
}- 硬币数量无限
- 凑成总金额所需的最少硬币个数
class Solution {
public int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1];
// 除以2是为了防止溢出
Arrays.fill(dp, Integer.MAX_VALUE / 2);
// dp[i] = min(dp[i], dp[i - j] + 1)
dp[0] = 0;
for (int x : coins) {
for (int c = x; c <= amount; c++) {
dp[c] = Math.min(dp[c], dp[c - x] + 1);
}
}
// 需要判断是否能正好凑够
return dp[amount] < Integer.MAX_VALUE / 2 ? dp[amount] : -1;
}
}- 硬币数量无限
- 可以凑成总金额的硬币组合数(无序)
class Solution {
public int change1(int amount, int[] coins) {
int n = coins.length;
// 1. 定义:dp[i + 1][j] 表示使用 [0, i] 范围硬币,凑够j元的方案数
int[][] dp = new int[n + 1][amount + 1];
// 2. 递推公式:dp[i + 1][j] = dp[i][j] + dp[i + 1][j - coins[i]];
dp[0][0] = 1;
for (int i = 0; i < n; i++) {
for (int j = 0; j <= amount; j++) {
if (coins[i] <= j) {
dp[i + 1][j] = dp[i][j] + dp[i + 1][j - coins[i]];
} else {
dp[i + 1][j] = dp[i][j];
}
}
}
return dp[n][amount];
}
public int change(int amount, int[] coins) {
int[] dp = new int[amount + 1];
dp[0] = 1;
for (int x : coins) {
// 完全背包问题:顺序遍历!
for (int j = x; j <= amount; j++) {
dp[j] += dp[j - x];
}
}
return dp[amount];
}
}- 有序
- 恰好装满
class Solution {
public int combinationSum4(int[] nums, int target) {
int[] dp = new int[target + 1];
dp[0] = 1;
// 先遍历容量
for (int i = 1; i <= target; i++) {
// 再遍历物品
for (int x : nums) {
if (x <= i) {
dp[i] += dp[i - x];
}
}
}
return dp[target];
}
}- 非空子数组
- 前缀和
- 以
nums[i]结尾的最大子数组和
class Solution {
public int maxSubArray1(int[] nums) {
int ans = Integer.MIN_VALUE;
int minPreSum = 0; // 最小前缀和
int preSum = 0; // 当前前缀和
for (int x : nums) {
preSum += x;
// 先计算以当前元素结尾的子数组和,再更新最小前缀和,防止把空数组和0算入答案
ans = Math.max(ans, preSum - minPreSum);
minPreSum = Math.min(minPreSum, preSum);
}
return ans;
}
public int maxSubArray2(int[] nums) {
int n = nums.length;
int ans = Integer.MIN_VALUE;
// dp[i] 表示以nums[i]结尾的子数组的最大和
int[] dp = new int[n];
dp[0] = nums[0];
for (int i = 1; i < n; i++) {
dp[i] = Math.max(0, f[i - 1]) + nums[i];
// 需要不断更新记录最大子数组和,不能返回 dp[n - 1] ,因为其只表示以nums[n - 1]结尾的子数组最大和
ans = Math.max(ans, dp[i]);
}
return ans;
}
public int maxSubArray(int[] nums) {
int n = nums.length;
int ans = Integer.MIN_VALUE;
int dp = 0;
for (int x : nums) {
dp = Math.max(dp, 0) + x;
ans = Math.max(ans, dp);
}
return ans;
}
}- 连续子数组,定义
dp[i]表示以nums[i]为子数组最后一个元素时,子数组的最大乘积 - 对于
nums[i],如果为整数,则与整数相乘为增大;如果是负数的话,则需要与负数相乘才能更大 fMax[i]:表示以nums[i]结尾的子数组的乘积的最大值fMin[i]:表示以nums[i]结尾的子数组的乘积的最小值
class Solution {
public int maxProduct1(int[] nums) {
int n = nums.length;
int[] fMax = new int[n];
int[] fMin = new int[n];
int ans = fMax[0] = fMin[0] = nums[0];
for (int i = 1; i < n; i++) {
int x = nums[i];
// 1. 由 x 单个元素
// 2. x 和 以 nums[i - 1] 结尾的元素组合
// 2.1 当 x < 0 时,x 与负数相乘可以得到更大的正数
// 2.2 当 x >= 0 时,x 与正数相乘可以得到更大的正数
fMax[i] = Math.max(Math.max(x * fMax[i - 1], x * fMin[i - 1]), x); // 这里分别与 fMax[i - 1] 和 fMin[i - 1] 相乘,就不用判断正负了
fMin[i] = Math.min(Math.min(x * fMax[i - 1], x * fMin[i - 1]), x);
ans = Math.max(ans, fMax[i]);
}
return ans;
}
}- 求分连续的子序列乘积最大值
class Solution {
public long maxStrength(int[] nums) {
long mn = nums[0];
long mx = nums[0];
for (int i = 1; i < nums.length; i++) {
int x = nums[i];
// 因为 mx, mn 要同时更新,所以用临时变量先保存 mx
long tmp = mx;
mx = Math.max(Math.max(mx, x), Math.max(mx * x, mn * x));
mn = Math.min(Math.min(mn, x), Math.min(tmp * x, mn * x));
}
return mx;
}
}- 完全背包
- 恰好达到容量的最小值
class Solution {
public int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1];
Arrays.fill(dp, Integer.MAX_VALUE);
dp[0] = 0;
for (int x : coins) {
for (int c = x; c <= amount; c++) {
if (dp[c - x] != Integer.MAX_VALUE) {
dp[c] = Math.min(dp[c], dp[c - x] + 1);
}
}
}
return dp[amount] == Integer.MAX_VALUE ? -1 : dp[amount];
}
}- 完全背包
- 恰好达到容量的最小值
class Solution {
public int numSquares(int n) {
int[] dp = new int[n + 1];
// dp[i] = Math.min(dp[i], dp[i - j * j] + 1);
Arrays.fill(dp, Integer.MAX_VALUE);
dp[0] = 0;
for (int i = 1; i <= n; i++) {
for (int j = 1; j * j <= i; j++) {
// 这里可以不用if判断,因为 dp[i] 一定可以有 i 个 1^2 组成
if (dp[i - j] != Integer.MAX_VALUE) {
dp[i] = Math.min(dp[i], dp[i - j * j] + 1);
}
}
}
return dp[n];
}
}class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
int n = s.length();
boolean[] dp = new boolean[n + 1];
dp[0] = true;
for (int i = 1; i <= n; i++) {
for (String word : wordDict) {
int m = word.length();
if (m <= i) {
dp[i] |= word.equals(s.substring(i - m, i)) && dp[i - m];
}
}
}
return dp[n];
}
}class LRUCache {
// 以正整数作为容量capacity初始化LRU缓存
public LRUCache(int capacity) {
}
// 如果关键字key存在于缓存中,则返回关键字的值,否则返回-1
public int get(int key) {
}
// 如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该逐出最久未使用的关键字
public void put(int key, int value) {
}
}- 通过 Hash 算法将原始连接转换成一个 Hash 码
- 将生成的十进制哈希码转换为 62 进制
MurmurHash 算法
- 不关心反向解密的难度,更重要的是关注哈希的运算速度和冲突概率
public static String hashToBase62(String str) {
// 使用 MurmurHash 根据 原始链接 生成哈希码
// int的范围是 -2.1 * 10^9 ~ 2.1 * 10^9
// long的范围:-9.2 * 10^18 ~ 9.2 * 10^18
// 6位62进制:62^6 = 5.68 * 10^9
int i = MurmurHash.hash32(str);
// x<Optimize>l:优化10进制范围
// 1. 这里把生成的int数值范围映射到 [0, 4.2 * 10^9] 并不能够涵盖所有的 6位62进制范围
// 2. 同时也可能导致哈希冲突问题,MurmurHash算法导致
// [2.1 * 10^9 ~ 4.2 * 10^9] : [0, 2.1 * 10 ^ 9] ==> [0, 4.2 * 10 ^ 9]
long num = i < 0 ? Integer.MAX_VALUE - (long) i : i;
return convertDecToBase62(num);
}进制转换
Base62 编码是将数据转换为只包含数字和字母的一种方法。它使用了 62 个字符,分别是 0-9、a-z、A-Z,可以作为 URL 短链接、文件名等场景的字符串表示,相对于 16 进制或 64 进制等其他编码,Base62 具有更高的可读性和稳定性。
// 通过将哈希码与62位字符集不断取模的方式,将十进制转换为62进制
private static String convertDecToBase62(long num) {
StringBuilder sb = new StringBuilder();
while (num > 0) {
int i = (int) (num % SIZE);
sb.append(CHARS[i]);
num /= SIZE;
}
return sb.reverse().toString();
}哈希函数将输入的数据映射为一个固定长度的哈希值,而不同的输入可能会映射为相同的哈希值,这被称为哈希冲突。
在短链接生成过程中,原始长链接经过哈希函数进行计算,生成一个哈希值。如果两个不同的原始长链接经过哈希计算后得到相同的哈希值,那么它们将生成相同的短链接。
这种情况通常是由于哈希函数的输出空间有限,而输入空间却是无限的。因此,无论哈希函数的设计有多好,仍然存在一定的概率会出现冲突。
生成的短链接是需要保障在当前域名下唯一的,那这个唯一又如何体现呢?每次查询数据库中已有短链接数据来判断是否唯一么?性能有点低,我们使用了布隆过滤器来进行判断。
当我们发现冲突后(不同的原始链接生成相同的短链后缀),将原始长链接与一个随机生成的 UUID 字符串拼接,通过拼接后的内容继续查询布隆过滤器,直到不存在为止。
- 为什么不直接使用 UUID?
- 有位同学面试时被问到这个问题,其实是可以的。但是,有一个差强人意的理由,那就是生成 UUID 需要耗费时间,哪怕是极小的时间。
- 为什么不只使用原始链接?
- 先使用原始链接去生成,如果发现冲突了再使用拼接 UUID 方式解决冲突。
x<TODO>l:实际测试使用短链接+UUID和直接使用UUID比较
- 直接使用随机数从62个字符中挑选6个字符 来生成6位字符串
x<TODO>l猜测:直接使用随机数需要循环6次,生成6个随机数;而先hash再转62进制,仅进行一次随机操作?
一直冲突的概率是很小的,但是针对这种概率事件,我们就要考虑到极端情况。为此,我们在代码加了一个判断变量,如果超过指定次数,就抛出异常。
注意:这里的分布式锁使用全局锁
charliexlink:short-link:lock:create只要是为了保护数据库,防止同一时间大量查询请求达到数据库
- 基于布隆过滤器实现
生成短链接后,通过布隆过滤器判断是否存在(短链接全域名),不存在则说明短链接还没被创建,直接返回。如果存在,则重新生成重新判断。
使用布隆过滤器判断短链接是否存在,不需要到数据库中查询,降低数据库压力。
- 基于分布式锁实现
在创建短链接时,从数据库中查询短链接是否存在,如果存在则需要重新生成短链接,然后到数据库中重新判断!
关键点是需要到数据库中判断短链接是否存在,当同一时间有大量请求创建短链接时,都会到数据库中查询短链接是否存在。
为了减少同一时间到数据库中查询记录的请求,而只锁住查询部分,既要上锁,又要到数据库中查询。不如布隆过滤器
所以,使用分布式锁锁住整个创建过程
charliexlink:short-link:lock:create,这样是的创建流程串行执行,每次只会有一个线程去数据库中从查询。
因为分布式锁是串行的,而布隆过滤器可以做到并行。通过我在本地进行两种方式的压测,大概评估布隆过滤器是分布式锁的 6 倍性能。理论上说,当并发越高,这个性能差距就越明显。其次,通过分布式锁查询的是 MySQL 数据库,这里还要算上数据库的性能和缓存的差距。
而且,因为我们访问短链接跳转原始链接接口处理缓存穿透场景,需要使用布隆过滤器完成。所以在这里直接使用是刚好的。
布隆过滤器是基于redisson实现,redis支持数据持久化。在aof日志持久化时,设置ALWAYS,最多丢失一条指令。也可以通过设置定时任务,将数据库中的短链接加载到布隆过滤器中。
布隆过滤器不允许删除。
- 添加元素时是将相应的位置置1,删除置0的话可能导致误删其它元素。
- 数据一致性:布隆过滤器可以返回元素“可能存在”或“一定不存在”。删除会改变这个判断逻辑
- 已删除的短链接加一层Set缓存,如果判断布隆过滤器中存在,需要在去判断set集中中是否存在,如果存在则短链接可用。
优点:可以满足删除短链接后的复用问题。
缺点:需要进行多次网络查询,以及删除要维护多个数据
- 从短链接生成算法考虑,62^6
- 从数据库建表考虑,16张
t_link_?表,一张存2000万,可以存储3亿多
以短链接的表 t_link_0-15举例,一共 16 张表。我们假设一张表能存 2000万,乘以 16,那就是 3 亿两千万。
分片键:用于数据库(表)水平拆分的数据库字段。
我们将短链接表拆分了 16 张分表,那用户新增短链接,怎么知道短链接记录应该放到哪张表里?这就需要用到分片键了,通过分片键进行一定规则(短链接表 t_link 使用的 HASH_MOD 方式)的运算,最终得到一个下标,这也就是我们要插入的分表位置。
为什么选择分组
group_id/gid作为分片键?答:因为短链接支持分组功能,在进行分组查询时,查询参数只传入了
gid,如果不适用gid作为分片键的话,要找到gid相同的所有短链接就需要进行所有数据表的扫描。以小码短链接为例,如下是进行分组查询时的请求URL,https://portal.xiaomark.com/api/v1/short_link/projects/67b1a660208eeea3878e71d9/links/?page_num=1&page_size=10&group_id=67c9a1f74ce3b430afae5601&sort_by_non_robot=false请求参数中只传入了group_id,所以为了快速定位所有相同group_id的短链接就需要使用group_id作为分片键。
🔺:用户通过浏览器访问短链接时,仅有短链接值,没有gid,所以需要建立路由表t_link_goto进行缓存短链接和gid的关系。通过短链接full_short_url查询t_link_goto表,获取到对应的gid,进而再去查询t_link表,这样就不会出现读扩散问题。
缓存预热是指在应用程序启动或系统负载低峰期,提前将应用程序需要访问缓存的数据加载到缓存中,以便在实际的请求到来时能够快速响应。
在创建完短链接后就将短链接记录新增到缓存
stringRedisTemplate.opsForValue().set( String.format(GOTO_SHORT_LINK_KEY, fullShortUrl), requestParam.getOriginUrl(), LinkUtil.getLinkCacheValidTime(requestParam.getValidDate()), TimeUnit.MILLISECONDS ); // short-link_goto_localhost/I7ceb -> 原始链接
因为短链接可以设置过期时间,对于设置了过期时间的短链接,可以在缓存中也设置对应的时间即可。对于设置永久有效期的短链接,因为短链接一般具有时效性,很多时候只会在一定时间内使用,过了这个时间后用的人就少了。所以,即使短链接永久有效,我也设置了一个月的过期时间。如果一个月后还有人访问,就去数据库加载数据,再设置一个月的过期时间即可。
短链接项目中,并发量(TPS/QPS)可以回答核心的短链接创建和短链接跳转访问接口
短链接的数据因为会被高频访问对应原链接,所以数据存了两份:MySQL数据库和Redis缓存中。在修改短链接时,需要同时对两者进行变更,因为种种异常原因,如何保证数据库和缓存中短链接的一致性?
登录逻辑:
- 获取登录码
- 输入电话,后端校验手机号是否合法
- 合法,生成6位随机数字
- 保存登录码到redis中,
login:code:手机号-code - 发送验证码到手机
- 用户登录
- 输入手机号和验证码
- 后端校验手机号格式是否正确
- 根据
login:code:phone获取redis中的校验码 - 校验码存在且正确,则根据手机号到数据库中查询用户信息
- 如果用户不存在,则创建新用户
- 将用户信息保存到 redis中,便于登录校验。类型为Hash类型,key为
login:token:random_token,值为键值对 - 返回token给前端,用户登录校验
- 前端每次发送请求都会在请求头中携带该token
用户在请求时候,会从cookie中携带JsessionId到后台,后台通过JsessionId从session中拿到用户信息,如果没有session信息,则进行拦截;如果有session信息,则将用户信息保存到threadLocal中,并且放行。

Tomcat的运行原理:

- 当tomcat端的socket接受到数据后,监听线程会从tomcat的线程池中取出一个线程执行用户请求
- 每个用户的请求都由tomcat线程池中的一个线程来完成工作,使用完成后再进行回收。每个请求都是独立的,所以在每个用户访问工程时,可以使用
ThreadLocal来做线程隔离,每个线程操作自己的一份数据。
核心思路分析:
每个tomcat中都有一份属于自己的session,假设用户第一次访问第一台tomcat,并且把自己的信息存放到第一台服务器的session中,但是第二次这个用户访问到了第二台tomcat,那么在第二台服务器上,肯定没有第一台服务器存放的session,所以此时 整个登录拦截功能就会出现问题,我们能如何解决这个问题呢?早期的方案是session拷贝,就是说虽然每个tomcat上都有不同的session,但是每当任意一台服务器的session修改时,都会同步给其他的Tomcat服务器的session,这样的话,就可以实现session的共享了
但是这种方案具有两个大问题
1、每台服务器中都有完整的一份session数据,服务器压力过大。
2、session拷贝数据时,可能会出现延迟

1、登录验证码(string类型)
- key:
login:code:phone - value:
code
// 3. 符合,生成验证码
String code = RandomUtil.randomNumbers(6);
// // 4. 保存验证码到session
// session.setAttribute("code", code);
// 4. 保存验证码到redis set key value ex 120
stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY + phone, code);
// 设置验证码code过期时间
stringRedisTemplate.expire(LOGIN_CODE_KEY + phone, LOGIN_CODE_TTL, TimeUnit.MINUTES);2、用户登录信息(Hash类型)
- key:
login:code:random_token - value:
token
// 7. 保存用户信息到 redis 中
// 7.1 随机生成token,作为登录令牌
String token = UUID.randomUUID().toString(true);
// 7.2 将User对象转为HashMap存储
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// warn: userDTO中id属性为Long,beanToMap默认会保留value类型。但是stringRedisMap要求key和value都是String
// Map<String, Object> userMap = BeanUtil.beanToMap(userDTO);
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO, new HashMap<>(),
CopyOptions.create()
.setIgnoreNullValue(true)
.setFieldValueEditor((fieldKey, fieldValue) -> fieldValue.toString()));
String tokenKey = LOGIN_USER_KEY + token;
stringRedisTemplate.opsForHash().putAll(tokenKey, userMap);
// 设置token过期时间
stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);问题:当前登录拦截器LoginInterceptor只会拦截需要登录的路径,在拦截的同时刷新token有效期。而当用户访问了哪些不需要拦截的路径时,无法刷新token有效期
解决:添加一个拦截器,在第一个拦截器中拦截所有路径,在该拦截器RefreshInterceptor中获取token并刷新有效期
 |
 |
|---|
/**
* @Author: charlie
* @CreateTime: Created in 2025/2/23 18:44
* @Description: 登录状态刷新拦截器
* 1. 由于拦截器是手动创建的,spring不会管理其生命周期以及依赖注入。需要通过构造器注入属性
* 2. 拦截所有请求,刷新token有效期
*/
@RequiredArgsConstructor
public class RefreshInterceptor implements HandlerInterceptor {
private final StringRedisTemplate stringRedisTemplate;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1. 从请求头中获取登录token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
// 没有携带 authorization 请求头,说明还没有登录,直接放行。交给 LoginInterceptor 拦截器判断路径是否需要拦截
return true;
}
// 2. 基于Token获取redis中的用户
String tokenKey = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(tokenKey);
// 3. 判断用户是否存在或者过期
if (userMap.isEmpty()) {
return true;
}
// 5. 将查询到的Hash数据转为UserDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 6. 存在,保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
// 7. 刷新token有效期
stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8. 放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
UserHolder.removeUser();
}
}/**
* @Author: charlie
* @CreateTime: Created in 2025/2/23 18:44
* @Description: 登录拦截器
* 在刷新拦截中,如果已经登录,TheadLocal中会保存用户信息
*/
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1. 判断是否需要拦截(ThreadLocal中是否有用户)
if (UserHolder.getUser() == null) {
// 没有用户,拦截,设置状态码
response.setStatus(401);
// 拦截
return false;
}
// 有用户,则放行
return true;
}
}**缓存(Cache)**就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码
实际开发中,会构筑多级缓存来使系统运行速度进一步提升,例如:本地缓存与redis中的缓存并发使用
浏览器缓存:主要是存在于浏览器端的缓存
**应用层缓存:**可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
**数据库缓存:**在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
**CPU缓存:**当代计算机最大的问题是 cpu性能提升了,但内存读写速度没有跟上,所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。

- 内存淘汰:redis自动进行,当redis内存达到咱们设定的
max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式) - **超时剔除:**当我们给redis设置了过期时间
ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存 - **主动更新:**我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题

缓存的数据源自于数据库,而数据库的数据是会发生变化的。如果当数据库中数据发生变化,而缓存却没有同步,此时就会出现一致性问题。
有如下几种方案:
Cache Aside Pattern:人工编码方式,缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案Read/Write Through Pattern:由系统本身完成,数据库与缓存的问题交由系统本身处理Write Behind Caching Pattern:调用者只操作缓存,其它线程去异步处理数据库,实现最终一致。

先更新数据库,再更新缓存:
- 如果每次操作数据库后,都操作缓存,但是中间没有人查询,那么更新工作只有最后一次生效,中间的更新动作意义并不大
- 可以把缓存删除,等待再次查询时,将缓存中的数据加载出来
如何保证缓存与数据库的操作同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
查询:根据id查询店铺时,如果缓存命中,则直接返回;如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间。
public Result queryShopById(Long id) {
String key = CACHE_SHOPE_KEY + id;
// 1 从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2 判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3 存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 4. 不存在,根据id查询数据库
Shop shop = getById(id);
// 5 不存在,返回错误
if (shop == null) {
return Result.fail("店铺不存在!");
}
// 6. 存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30L, TimeUnit.MINUTES);
// 7 返回
return Result.ok(shop);
}修改:根据id修改店铺时,先修改数据库,再删除缓存
@Transactional
public Result update(Shop shop) {
Long id = shop.getById();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1 更新数据库
updateById(shop);
// 2 删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}缓存穿透:客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会达到数据库。
- 缓存空对象,并设置过期时间
- 布隆过滤器
- 增强id的复杂度,避免被猜测id规律
- 做好热点参数的限流。根据用户或者ip对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如对异常IP列入黑名单
常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能(布隆过滤器判断不存在,则一定不存在;判断存在,但可能不存在)

缓存雪崩是指同一时间段大量的缓存key同时失效或者Redis服务宕机,导致大量请求达到数据库,带来巨大的压力
解决方案:
针对Redis服务不可用的情况:
- 采用Redis集群,避免单机出现问题整个缓存服务都没办法使用
- 限流,避免同时处理大量的请求
- 多级缓存,例如本地缓存+Redis缓存的组合,当Redis缓存出现问题时,还可以从本地缓存中获取到部分数据
针对热点缓存失效的情况:
- 设置不同的TTL,如添加随机值等
- 缓存预热,也就是在程序启动后或运行过程中,主动将热点数据加载到缓存中。
缓存击穿也叫热点key问题,就是一个被高并发访问并且缓存重建业务复杂的key突然失效,大量请求访问会在瞬间到达数据库,给数据库带来巨大的冲击
缓存击穿的解决方案:
- 互斥锁
- 逻辑过期
逻辑分析:假设线程1在查询缓存不存在之后,本来应该去查询数据库,然后把这个数据重新加载到缓存。此时,只要线程1走完这个逻辑,其它线程就都能从缓存中加载这些数据了,但是假设在线程1还没有走完缓存重建流程的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法,那么这些线程都不能从缓存中查询道该数据,那么他们就会同一时刻去访问查询缓存,都没查到,接着同一时间去访问数据库,同时执行数据库代码,对数据库访问压力过大。
因为锁能实现互斥性。假设线程过来,只能一个一个地访问数据库,从而避免对数据库访问压力过大,但也会影响查询的性能,因为此时会让查询从并行变成了串行,可以采用tryLock+double check的方式来解决这样的问题。
假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。

核心思路:
- 原来从缓存中查询不到数据后直接查询数据库,现在方案是进行查询之后,如果从缓存中没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得了锁,如果没有获取到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询。
- 如果获取到锁的线程,再去进行查询数据库,查询后将数据写入redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿
- 利用redis的
setnx方法来表示获取锁
// 获取锁
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return Boolean.TRUE.equals(flag);
}
// 释放锁
private void unlock(String key) {
stringRedisTemplate.delete(key);
} public Shop queryWithMutex(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1、从redis中查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get("key");
// 2、判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 存在,直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
//判断命中的值是否是空值
if (shopJson != null) {
//返回一个错误信息
return null;
}
// 4.实现缓存重构
//4.1 获取互斥锁
String lockKey = "lock:shop:" + id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
// 4.2 判断否获取成功
if(!isLock){
//4.3 失败,则休眠重试
Thread.sleep(50);
return queryWithMutex(id);
}
//4.4 成功,根据id查询数据库
shop = getById(id);
// 5.不存在,返回错误
if(shop == null){
//将空值写入redis
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
//返回错误信息
return null;
}
//6.写入redis
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);
}catch (Exception e){
throw new RuntimeException(e);
}
finally {
//7.释放互斥锁
unlock(lockKey);
}
return shop;
}异步构建缓存,缺点在于构建完缓存之前,返回的都是脏数据
方案分析:之所以会出现缓存击穿问题,主要原因是在于对
key设置了过期时间,假设不设置过期时间,就不会有缓存击穿的问题,但是不设置过期时间,数据就一直占用内存,可以采用逻辑过期方案。
将过期时间设置在redis的value中,而非直接作用于redis,后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期,此时线程1去获取互斥锁,那么其它线程进行阻塞(直接返回脏数据),获得了锁的线程会开启一个新的线程去进行数据重构逻辑,直到新开的线程完成这个逻辑,才释放锁,而线程1直接进行返回。假设现在线程3过来访问,由于线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其它线程才能走返回正确的数据。

思路分析:
- 当用户开始查询redis时,判断是否命中,如果没有(逻辑过期策略下,缓存不存在说明缓存穿透,数据库中也不存在该数据)则直接返回空数据,不查询数据库
- 而一旦命中,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据
- 如果过期,则再开启独立线程后直接返回之前的数据,由独立线程去重构数据,重构完成后释放互斥锁
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire( Long id ) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(json)) {
// 3.存在,直接返回
return null;
}
// 4.命中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
// 5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())) {
// 5.1.未过期,直接返回店铺信息
return shop;
}
// 5.2.已过期,需要缓存重建
// 6.缓存重建
// 6.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
// 6.2.判断是否获取锁成功
if (isLock){
CACHE_REBUILD_EXECUTOR.submit( ()->{
try{
//重建缓存
this.saveShop2Redis(id,20L);
}catch (Exception e){
throw new RuntimeException(e);
}finally {
unlock(lockKey);
}
});
}
// 6.4.返回过期的商铺信息
return shop;
}方案对比:

- 互斥锁方案:
- 由于保证了互斥性,所以数据一致,且实现简单,因为仅仅需要加一把锁而已,也没其它事情需要操心,所以没有额外的内存消耗。
- 缺点:有锁就有死锁问题的发生,且只能串行执行性能肯定收到影响
- 逻辑过期方案:
- 线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据
- 缺点:在重构数据完成前,其它的线程只能返回之前的数据,且实现起来麻烦
常见的缓存预热方式两种:
- 使用定时任务。比如
xxl-job来定时触发缓存预热逻辑,将数据库中的热点数据查询出来并存入缓存中 - 使用消息队列。异步地进行缓存预热,将数据库中地热点数据地主键或者ID发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者ID查询数据库并更新缓存。
为什么需要全局唯一ID,而不使用数据库自增ID?
- id规律性太明显。用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
- 首单表数据量的限制。mysql单表的容量不易超过500w,数据量过大时,需要考虑分表。但是拆分表之后,他们从逻辑上是同一张表,所以他们的id不能是一样的,于是乎需要保证id的唯一性。
全局ID生成器,是一种在分布式系统下原来生成全局唯一ID的工具,一般满足以下特性:
- 唯一性
- 递增性
- 安全性
- 高可用
- 高性能

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生$2^{32}$个不同ID
@Component
@RequiredArgsConstructor
public class RedisIdWorker {
private final StringRedisTemplate stringRedisTemplate;
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1735689600L;
/**
* 时间戳位数
*/
private static final long COUNT_BITS = 32L;
/**
* 生成唯一id
* @param keyPrefix 业务key前缀
* @return
*/
public long nextId(String keyPrefix) {
// 1. 生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2. 生成序列号
// 2.1 获取当前日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2 自增长
Long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3. 拼接并返回
return timestamp << COUNT_BITS | count;
}
}下单时需要判断两点:
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。
超卖问题引入:
- 由于判断库存,扣减库存不是一个原子操作
- 多线程下,由于指令交错,导致库存超卖
- 悲观锁:悲观锁认为线程安全问题一定会发生,因此每次操作时都会进行加锁操作(
synchronized和Lock),确保线程串行执行 - 乐观锁:乐观锁认为线程安全问题不一定发生,因此操作时不加锁,只有在更新数据时去判断有没有其它线程对数据做了修改。如果没有修改则认为是安全的,自己才更新数据;如果已经被其它线程修改,说明发生了安全问题,此时可以重试或异常。
// 方式一:会有大量失败操作
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // stock = stock - 1
.eq("voucher_id", vocher_id) // where id = ? and stock = ?
.eq("stock", voucher.getStock())
.update();
// 方式二
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // stock = stock - 1
.eq("voucher_id", vocher_id) // where id = ? and stock > 0
.gt("stock", 0)
.update();问题:目前秒杀下单,一个用户可以同时下多单
具体操作逻辑:
- 秒杀是否开始/结束
- 库存是否充足
- 优惠券id和用户id是否已经下过单
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
// 5.一人一单逻辑
// 5.1.用户id
Long userId = UserHolder.getUser().getId();
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
//6,扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update();
if (!success) {
//扣减库存
return Result.fail("库存不足!");
}
//7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 7.1.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
voucherOrder.setUserId(userId);
// 7.3.代金券id
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
return Result.ok(orderId);
}存在问题:
- 和之前一样,并发访问查询数据库问题,可能会导致超卖和一人多单
- 乐观锁比较适合更新数据,现在插入数据,需要使用悲观锁操作
方式一:使用synchronized锁住整个创建秒杀券订单方法
@Transactional
public synchronized Result createVoucherOrder(Long voucherId) {
Long userId = UserHolder.getUser().getId();
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足!");
}
// 7.创建订单
// 7.返回订单id
return Result.ok(orderId);
}这样添加锁,锁的粒度太粗了,在使用锁过程中,控制锁粒度 是一个非常重要的事情,因为如果锁的粒度太大,会导致每个线程进来都会锁住,所以我们需要去控制锁的粒度。
方式二:对字符串常量池中的用户id加锁,此时不同用户之间不会相互阻塞
@Transactional
public Result createVoucherOrder(Long voucherId) {
Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if (count > 0) {
return Result.fail("用户已经购买过一次");
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足!");
}
// 7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
save(voucherOrder);
// 7.返回订单id
return Result.ok(orderId);
}
}问题一:因为当前方法被spring事务控制,如果在方法内部加锁,可能会导致当前事务还没有提交,但是锁已经释放
所以选择将当前方法整个包裹起来,确保事务不会出现问题
Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
return this.createVoucherOrder(voucherId);
}问题二:因为调用方法实际上是通过this的方式调用,事务要想生效,还得利用代理来生效,所以这个地方,需要获取到原始的事务对象,来操作事务
synchronized (userId.toString().intern()) {
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
}问题三:集群环境下的并发问题,通过加锁可以解决单机情况下的一人一单安全问题,但是在集群模式下就不行了
集群模式下,部署多个tomcat,每个tomcat都有一个属于自己的jvm,那么同一个用户在不同tomcat服务其上锁住的String类型的内容一样,但是并不是同一个对象,因此无法实现互斥。在这种情况下,可以使用分布式锁来解决。

分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
核心思想:让大家使用使用同一把锁,只要大家使用的同一把锁,就可以锁住进程,让程序串行执行。

分布式锁需要满足的条件?
- 可见性:多个线程都能看到相同的结果,即多个进程之间都能感知到变化的意思
- 互斥性:互斥是分布式锁的最基本条件,使得程序串行执行
- 高可用:程序不易崩溃,时时刻刻都保证较高的可用性
- 高性能:由于加锁本身就让性能降低,所以对于分布式锁本身需要他较高的加锁性能和释放锁性能
- 安全性:安全也是程序中必不可少的一环
常见的分布式锁实现?
- MySQL:mysql本身就带有锁机制,但是由于mysql性能本身一般,所以采用分布式锁的情况下,使用的较少
- Redis:利用
setnx方法,如果插入key成功,表示获得了锁,如果有人插入成功,其它人插入失败则表示无法获得锁,利用这个逻辑来实现分布式锁。 Zookeeper:zk利用节点的唯一性和有序性来实现互斥

使用Redis实现分布式锁的两个基本方法:
- 获取锁
- 互斥:确保只能有一个线程获取锁,
setnx key value - 非阻塞:尝试一次,成功返回true,失败返回false
- 互斥:确保只能有一个线程获取锁,
- 释放锁
- 手动释放:
del key - 超时释放:获取锁时添加一个超时时间
- 手动释放:
public interface ILock {
/**
* 尝试获取锁
* @param timeoutSec 锁过期时间,单位秒
* @return 成功返回true,失败返回false
*/
boolean tryLock(long timeoutSec);
/**
* 释放锁
*/
void unlock();
}class SimpleRedisLock implements ILock {
private String name;
private static final String KEY_PREFIX = "lock:";
private StringRedisTemplate stringRedisTemplate;
// 加锁,同时增加过期时间
public boolean tryLock(long timeoutSec) {
// 获取线程标识
String threadId = Thread.currentThread().getId();
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId + "", timeoutSec);
return Boolean.TURE.equals(success);
}
// 释放锁逻辑
public void unlock() {
// 通过 del 删除锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}逻辑说明:
持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放,这时其他线程,线程2来尝试获得锁,就拿到了这把锁,然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除,这就是误删别人锁的情况说明
解决方案:解决方案就是在每个线程释放锁的时候,去判断一下当前这把锁是否属于自己,如果属于自己,则不进行锁的删除,假设还是上边的情况,线程1卡顿,锁自动释放,线程2进入到锁的内部执行逻辑,此时线程1反应过来,然后删除锁,但是线程1,一看当前这把锁不是属于自己,于是不进行删除锁逻辑,当线程2走到删除锁逻辑时,如果没有卡过自动释放锁的时间点,则判断当前这把锁是属于自己的,于是删除这把锁。

private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
public void unlock() {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标示
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标示是否一致
if(threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}有关代码实操说明:
在我们修改完此处代码后,我们重启工程,然后启动两个线程,第一个线程持有锁后,手动释放锁,第二个线程 此时进入到锁内部,再放行第一个线程,此时第一个线程由于锁的value值并非是自己,所以不能释放锁,也就无法删除别人的锁,此时第二个线程能够正确释放锁,通过这个案例初步说明我们解决了锁误删的问题。

更极端的误删情况:
- 一人一单问题下,锁住的是用户的id,即
SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);,如lock:order:1, - 当多个线程持有相同的用户id时。在线程a已经判断锁是自己的准备删除时,锁过期,另一个线程b获取锁。此时线程a在执行删除锁的命令,就删除了线程b的锁。
- 问题所在:线程a拿锁、比较锁和删除锁的操作不是原子性的
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。
- Redis提供的调用函数:
redis.call('命令名称', 'key', '其它参数', ...) redis.call('set', 'name', 'jack')


如果脚本中的key,value不想写死,可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,脚本可以从KEYS和ARGV数组获取这些参数:

-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then
-- 一致,则删除锁
return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0Java代码
@AllArgsConstructor
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
private static final String KEY_PREFIX = "lock:";
/**
* 使用UUID标识不同JVM的线程
*/
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程表示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
// 调用lua脚本
stringRedisTemplate.execute(UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId()
);
}
}基于Redis的分布式锁实现思路:
- 利用
set nx ex获取锁,并设置过期时间 - 释放锁时先判断线程标识是否与自己一致,一致则删除锁
- 利用set nx满足互斥性
- 利用set ex保证故障时锁依然能释放,避免死锁,提高安全性
- 利用Redis集群保证高可用和高并发特性
重入问题:重入问题是指获得锁的线程可以再次进入相同的锁的代码块中,可重入锁的意义在于防止思索。synchronized和Lock锁都是可重入的
不可重试:目前分布式锁只能尝试一次,合理的情况应该是当线程获取锁失败后,应该能再次尝试获得锁
超时释放:在加锁时增加了过期时间,这样可以防止死锁,但是如果卡顿时间超长,虽然采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患。
主从一致性:如果Redis提供了主从集群,当我们向集群中写入数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。

Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
<!--1. 引入redisson依赖-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.27.2</version>
</dependency>// 2. 配置Redission客户端
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer()
.setAddress("redis://192.168.150.101:6379")
.setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
}注入redisson,并使用
@Resource
private RedissonClient redissonClient;
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
Long userId = UserHolder.getUser().getId();
//创建锁对象 这个代码不用了,因为我们现在要使用分布式锁
//SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);
RLock lock = redissonClient.getLock("lock:order:" + userId);
//获取锁对象
boolean isLock = lock.tryLock();
//加锁失败
if (!isLock) {
return Result.fail("不允许重复下单");
}
try {
//获取代理对象(事务)
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
} finally {
//释放锁
lock.unlock();
}
}Lock和synchronized可重入原理:
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
Redisson支持可重入锁
在分布式锁中,redisson采用
hash结构来存储锁,其中大key表示这把锁是否存在,小key表示当前锁被那个线程持有。lock-key:
- 线程表示:重入计数
以下是
lock.tryLock(lockKey)加锁,底层指定的lua脚本,一共有三个参数:
- KEYS[1]:锁名称
- ARGV[1]:锁失效时间
- ARGV[2]:id+":"+threadId;锁的小,key,即线程标识
// 1. exists 判断是否存在 key 为 lockKey 的,0表示不存在
// hset 往redis中写入数据,写成一个hash结构
// Lock { id + ":" + threadId: 1 }
// 2. hexists 判断 lockKey 中的线程标识(ARGV[2])是否是当前线程
// 如果是,则计数加1。并更新过期时间
// 3. 如果以上两个条件都不满足,则返回 锁过期时间,退出抢锁逻辑
// 4. 如果返回 nil,则代表对应前两个条件成立;如果返回的不是null,则走第三个分支,在源码处会进行while(true)的自旋抢锁。
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"Redisson中watchDog机制
现在下单的流程是:1.查询优惠卷、2.判断秒杀库存是否足够、3.查询订单、4.校验是否是一人一单、5.扣减库存、6.创建订单
在这6步中,有很多操作是要操作数据库的,而且还是一个线程串行执行,这就会导致程序执行地很慢,可以异步执行。
优化方案:将耗时比较短地逻辑判断放入到redis中,比如是否库存足够、一人一单等,只要这种逻辑可以完成,就意味着一定可以下单完成,只需要快速的逻辑判断,不用等下单逻辑走完,我们直接给用户返回成功,然后再在后台开一个线程,后台线程慢慢的去执行
queue里边的消息。

- 新增秒杀优惠卷的同时,将优惠卷信息保存到Redis中(在添加优惠卷时,就优惠卷信息加载到redis缓存中)
- 基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
-- 1. 参数列表
-- 1.1 优惠券id
local voucherId = ARGV[1]
-- 1.2 用户id
local userId = ARGV[2]
-- 2. 数据key
-- 2.1 库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2 订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3. 脚本业务
-- 3.1 判断库存是否充足 get stockKey
if (tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2 库存不足,返回1
return 1
end
-- 3.3 判断用户是否下单 sismember orderKey userId
if (redis.call('sismember', orderKey, userId) == 1) then
-- 3.4 用户重复下单,返回2
return 2
end
-- 3.5 扣减库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.6 下单 sadd orderKey userId
redis.call('sadd', orderKey, userId)
return 0VoucherOrderServiceImpl
@Override
public Result seckillVoucher(Long voucherId) {
// 获取用户
Long userId = UserHolder.getUser().getId();
// 1. 执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(),
userId.toString()
);
// 2. 判断结果是否为0
int r = result.intValue();
if (r != 0) {
// 2.1 不为0,代表没有购买资格
return Result.fail(r == 1 ? "库存不足~" : "不能重复下单");
}
// 2.2 为0,有购买资格,把下单信息保存到阻塞队列
// 保存下单信息到阻塞队列
VoucherOrder voucherOrder = new VoucherOrder();
// 2.3 订单id
long orderId = redisIdWorker.nextId("voucher-order");
voucherOrder.setId(orderId);
// 2.4 用户id
voucherOrder.setUserId(userId);
// 2.5 代金券id
voucherOrder.setVoucherId(voucherId);
// 基于rabbitmq消息队列实现秒杀异步下单 exchange routingKey queue
rabbitTemplate.convertAndSend(SECKILL_ORDER_EXCHANGE, SECKILL_ORDER_SUCCESS_KEY, voucherOrder);
// 3. 返回订单id
return Result.ok(orderId);
}通过lua脚本去原子执行判断逻辑,如果判断出来不为0,则要么是库存不足,要么是重复下单,返回错误信息;如果是0,则把下单的逻辑保存到队列中,然后异步执行
//异步处理线程池
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
//在类初始化之后执行,因为当这个类初始化好了之后,随时都是有可能要执行的
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
// 用于线程池处理的任务
// 当初始化完毕后,就会去从对列中去拿信息
private class VoucherOrderHandler implements Runnable{
@Override
public void run() {
while (true){
try {
// 1.获取队列中的订单信息
VoucherOrder voucherOrder = orderTasks.take();
// 2.创建订单
handleVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("处理订单异常", e);
}
}
}
private void handleVoucherOrder(VoucherOrder voucherOrder) {
//1.获取用户
Long userId = voucherOrder.getUserId();
// 2.创建锁对象
RLock redisLock = redissonClient.getLock("lock:order:" + userId);
// 3.尝试获取锁
boolean isLock = redisLock.lock();
// 4.判断是否获得锁成功
if (!isLock) {
// 获取锁失败,直接返回失败或者重试
log.error("不允许重复下单!");
return;
}
try {
//注意:由于是spring的事务是放在threadLocal中,此时的是多线程,事务会失效
proxy.createVoucherOrder(voucherOrder);
} finally {
// 释放锁
redisLock.unlock();
}
}
//a
private BlockingQueue<VoucherOrder> orderTasks =new ArrayBlockingQueue<>(1024 * 1024);
@Override
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
VoucherOrder voucherOrder = new VoucherOrder();
// 2.3.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 2.4.用户id
voucherOrder.setUserId(userId);
// 2.5.代金券id
voucherOrder.setVoucherId(voucherId);
// 2.6.放入阻塞队列
orderTasks.add(voucherOrder);
//3.获取代理对象
proxy = (IVoucherOrderService)AopContext.currentProxy();
//4.返回订单id
return Result.ok(orderId);
}
@Transactional
public void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherOrder.getVoucherId()).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
log.error("用户已经购买过了");
return ;
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherOrder.getVoucherId()).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
log.error("库存不足");
return ;
}
save(voucherOrder);
}- 先利用Redis完成库存余量预减,一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
- 基于阻塞队列的异步秒杀存在哪些问题?
- 内存限制问题:阻塞队列使用JVM内存,下单量有限制。超过限制的下单会阻塞
- 数据安全问题:基于阻塞队列,消息丢失无法重试
消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息

使用消息队列的好处在于解耦,我们下单之后,利用redis去进行校验下单条件,再通过消息队列把消息发送出去,然后再启动一个线程去消费这个消息,完成解耦,同时也加快响应速度。
基于Redis实现的消息队列:
- List结构模拟消息队列:list是一个双向链表,利用
lpush和rpop或者rpush和lpop来实现,当队列中没有消息时pop结果会返回null - 基于PubSub的消息队列:PubSub(发布订阅),消费者可以订阅一个或多个channel,生产者可以像对应的channel发送消息后,所有订阅者都能收到相关消息。
- 基于Stream的消息队列:

TODO: RabbitMQ
探店笔记类似点评网站的评价,往往是图文结合。对应的表有两个:
tb_blog:探店笔记,包含笔记中的标题、文字、图片等tb_blog_comments:其它用户对探店笔记的评价
上传图片
@PostMapping("blog")
public Result uploadImage(@RequestParam("file") MultipartFile image) {
try {
// 获取原始文件名称
String originalFilename = image.getOriginalFilename();
// 生成新文件名
String fileName = createNewFileName(originalFilename);
// 保存文件
image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName));
// 返回结果
log.debug("文件上传成功,{}", fileName);
return Result.ok(fileName);
} catch (IOException e) {
throw new RuntimeException("文件上传失败", e);
}
}需求:
- 同一个用户只能点赞一次,再次点赞则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显式
实现步骤:
- 给Blog类添加一个
isLiked字段,标识是否被当前用户点赞 - 修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞则点赞+1,已点赞则点赞数-1
- 修改根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLiked字段
- 修改分页查询Blog业务,判断当前用户是否点赞过
具体步骤:
- 在Blog字段添加一个字段
@TableField(exist = False)
private Boolean isLiked;- 修改代码:使用
sorted_set保存当前博客点赞用户的id和点赞时间,可以实现点赞用户按顺序显示
/**
* 给博客点赞
* @param id 笔记id
* @return
*/
@Override
public Result likeBlog(Long id) {
// 1. 判断当前登录用户
Long userId = UserHolder.getUser().getId();
// 2. 用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
// Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
// sorted_set中通过查询用户的分数(score)来判断元素是否存在,如果score为null,则代表不存在,反之存在
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 2.1 如果未点赞,可以点赞
// 3. 数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
if (isSuccess) {
// // 3.2 保存用户到redis的set结合
// stringRedisTemplate.opsForSet().add(key, userId.toString());
// 3.3 为实现点赞顺序排序,改用sorted_set存储,score为时间戳
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 4. 如果已点赞,取消点赞
// 4.1 数据库点赞数 - 1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
if (isSuccess) {
// 4.2 把用户从redis的set集合移除
// stringRedisTemplate.opsForSet().remove(key, userId.toString());
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();
}
/**
* 查询笔记是否被当前用户点赞,填充Blog的isLiked字段
*
* @param blog 笔记
*/
private void isBlogLiked(Blog blog) {
UserDTO user = UserHolder.getUser();
if (user == null) {
// 用户未登录(如访问首页面时),直接返回
return;
}
Long userId = user.getId();
String key = BLOG_LIKED_KEY + blog.getId();
// Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
// blog.setIsLike(Boolean.TRUE.equals(isMember));
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score != null);
}点赞列表查询(按点赞顺序排序)
BlogController
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") Long id) {
return blogService.queryBlogLikes(id);
}BlogService
/**
* 显示笔记点赞排行榜
* @param id 笔记id
* @return
*/
@Override
public Result queryBlogLikes(Long id) {
String key = BLOG_LIKED_KEY + id;
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if (top5 == null || top5.isEmpty()) {
// 没有人点赞,返回空集合
return Result.ok(Collections.emptyList());
}
// 2. 解析其中的用户id
List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
// 3. 根据用户id查询用户 listByIds(ids) --> select * from tb_user where id in (1010, 5) 结果不会按照 () 中id顺序给出
// 🔺解决方案: select * from tb_user where id in (1010, 5) order by field(id, 1010, 5)
String idStr = StrUtil.join(",", ids); // 1010,5
List<UserDTO> userDTOS = userService
// .listByIds(ids)
.query().in("id", ids).last("ORDER BY FIELD (id," + idStr + ")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(userDTOS);
}针对用户的操作,可以对用户进行关注和取消关注功能
FollowController
@RestController
@RequiredArgsConstructor
@RequestMapping("/follow")
public class FollowController {
private final IFollowService followService;
/**
* 关注或取关
* @param followUserId 目标用户id
* @param isFollow 关注/取关
*/
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {
return followService.follow(followUserId, isFollow);
}
/**
* 判断当前用户是否关注 followUserId 用户
* @param followUserId 目标用户id
*/
@GetMapping("/or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUserId) {
return followService.isFollow(followUserId);
}
/**
* 查看当前用户和 id 用户的共同关注列表
* @param id 目标用户 id
* @return 共同关注列表
*/
@GetMapping("/common/{id}")
public Result followCommons(@PathVariable("id") Long id) {
return followService.followCommons(id);
}
}FollowServiceImpl
@Service
@RequiredArgsConstructor
public class FollowServiceImpl extends ServiceImpl<FollowMapper, Follow> implements IFollowService {
private final StringRedisTemplate stringRedisTemplate;
private final IUserService userService;
// 关注/取关 目标用户(followUserId)
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 1. 判断是关注还是取关
String key = "follows:" + userId;
if (Boolean.TRUE.equals(isFollow)) {
// 2. 关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
// 更新数据库成功后,添加到缓存
if (isSuccess) {
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
} else {
// 3. 取关,删除
QueryWrapper<Follow> queryWrapper = new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId);
boolean isSuccess = remove(queryWrapper);
if (isSuccess) {
// 把关注用户从redis的set集合移除
stringRedisTemplate.opsForSet().remove(key, followUserId.toString());
}
}
return Result.ok();
}
// 判断当前用户是否关注了目标用户(followeUserId)
@Override
public Result isFollow(Long followUserId) {
// 获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 查询是否关注 select count(*) from tb_follow where user_id = ? and follow_user_id = ?
Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();
// 判断
return Result.ok(count > 0);
}
}共同关注实现:
利用Redis的set集合,实现共同关注功能。
/**
* 查询当前用户 和 目标用户 的共同关注列表
* @param id 目标用户id
* @return
*/
@Override
public Result followCommons(Long id) {
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
String key2 = "follows:" + id;
Set<String> followCommons = stringRedisTemplate.opsForSet().intersect(key, key2);
if (followCommons == null || followCommons.isEmpty()) {
return Result.ok(Collections.emptyList());
}
List<Long> ids = followCommons.stream().map(Long::valueOf).collect(Collectors.toList());
List<UserDTO> users = userService.listByIds(ids).stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}需求:
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须使用Redis的数据结构实现
- 查询收件箱时,可以实现分页查询
@Override
public Result saveBlog(Blog blog) {
// 获取登录用户
Long userId = UserHolder.getUser().getId();
blog.setUserId(userId);
// 保存探店博文
boolean isSuccess = save(blog);
// 把笔记推送给粉丝
if (!isSuccess) {
return Result.fail("发送笔记失败");
}
// 获取当前用户的所有粉丝 select * from tb_follow where follow_user_id = userId
List<Follow> follows = followService.query().eq("follow_user_id", userId).list();
// 将发布的笔记推送给所有粉丝 zadd "feed:followId" System.currentMillis() userId
follows.stream()
.map(Follow::getUserId) // 获取粉丝id
.forEach(userId1 -> { // 将笔记推送到 key 为 feed:粉丝id 的 sorted_set
String key = FEED_KEY + userId1;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
});
// 返回id
return Result.ok(blog.getId());
}- url:
/blog/of/follow?&lastId=17430863704420
具体操作:
- 每次查询完成后,分析出查询出数据最小时间戳,将这个值作为下一次查询的条件
- 需要找到与上一次查询相同的查询个数作为偏移量(去掉相同时间点已经查询过的数),下次跳过这些查询过的数,拿到需要的数据
综上:请求参数中携带lastId:上一次查询的最小时间戳,和偏移量(最小时间戳重复查复查询的个数)
一、定义出来具体的返回值实体类
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}BlogController和BlogServiceImpl
/**
* 关注推送,查询当前用户关注的用户发布的笔记
* @param max 上一次查询结果的最小时间戳
* @param offset 查询偏移量,本次查询需要跳过多少记录数量,才能从上次查询结果的下一条开始获取数据
* @return
*/
@GetMapping("/of/follow")
public Result queryBlogOfFollow(@RequestParam("lastId") Long max,
@RequestParam(value = "offset", defaultValue = "0") Long offset) {
return blogService.queryBlogOfFollow(max, offset);
}
@Override
public Result queryBlogOfFollow(Long max, Long offset) {
// 1. 获取当前用户
Long userId = UserHolder.getUser().getId();
// 2. 查询收件箱 zrevrangebyscore key max min
String key = FEED_KEY + userId; // feed:1010
// 获取 [0, max] 之间偏移掉 offset 个后的 2 个数据
// 5 5 5 4 4 2 1
// 第一次拿到 [0, currTime] offset=0 -> 5 5 -> currTime=5,offset=2
// 第二次拿到 [0, 5] offset=2 -> 5 4 -> currTime=4,offset=1
// ...
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3. 非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4. 解析数据:blogId, score(时间戳),offset(偏移量,)
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0; // 最小时间戳
int os = 1; // 偏移量,即score等于最小时间戳的个数
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
// 4.1 获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2 获取分数(时间戳),最后一个元素即为最小时间戳
long time = tuple.getScore().longValue();
// 每次都更新minTime,时间戳是降序排序的,所以最后会获得最小时间戳,并拿到最小时间戳重复次数
if (time == minTime) {
os++;
} else {
minTime = time;
os = 1;
}
}
String idsStr = StrUtil.join(",", ids);
// 5.1 根据id查询blog,按照在 ids 集合中的顺序排序(即推送时间从最近到之前)
List<Blog> blogs = query().in("id", ids).last("order by field(id, " + idsStr + " )").list();
// 5.2 查询blog用户和是否被点赞
blogs.forEach(
blog -> {
queryBlogUser(blog); // 填充笔记的用户信息
isBlogLiked(blog); // 查询笔记是否被当前用户顶赞
}
);
// 5. 封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setMinTime(minTime);
r.setOffset(os);
return Result.ok(r);
}思考:如果使用mysql记录签到(如下图),用户一次签到就是一条记录,假如有1000万用户,平均每人每年签到次数为10次,则这张表一年的数据量为 1亿条

思路:可以把年和月作为bitMap的key,然后保存到一个bitMap中,每次签到就到对应的位上把数字从0变成1,只要对应是1,就表明这一天已经签到了,反之则没有签到
// 用户签到
@Override
public Result sign() {
// 1. 获取当前用户
Long userId = UserHolder.getUser().getId();
// 2. 获取档期那日期
LocalDateTime now = LocalDateTime.now();
// 3. 拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
// sign:1010:202503 -> 001000100
String key = USER_SIGN_KEY + userId + keySuffix;
// 4. 获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5. 写入redis setbit key offset 1
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
return Result.ok();
}用户签到统计
连续签到天数:从当前天开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数

如何获取本月到今天为止的所有签到数据?:bitfield key get u 0
@Override
public Result signCount() {
// 获取本月截止今天为止所有的签到记录
// 1. 获取当前用户
Long userId = UserHolder.getUser().getId();
// 2. 获取档期那日期
LocalDateTime now = LocalDateTime.now();
// 3. 拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 4. 获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5. 获取本月截止今天为止的所有的签到记录,返回的是一个十进制数字 bitfield key get udayOfMonth 0
List<Long> result = stringRedisTemplate.opsForValue().bitField(
key,
BitFieldSubCommands.create()
.get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));
if (result == null || result.isEmpty()) {
return Result.ok(0);
}
Long num = result.get(0);
if (num == null || num == 0) {
return Result.ok(0);
}
// 6. 计算从今天开始向前连续签到的天数
int count = 0;
while ((num & 1) != 0) {
count++;
num >>>= 1;
}
return Result.ok(count);
}