Fullfillment (workflow) 개선 사항 건의 #2
Description
수집 데이터 Domain Java Class
대체적으로 모든 NexCloud 제품군이 수집 데이터에 대한 Domain 을 Java 클래스로 해석하고 있습니다.
이 서비스를 만약 실서비스로 1년 이상 유지한다고 하면, 수집대상의 원천소스 (Mesos,Host,Docker) 가 버전업 등의 이유로 도메인의 변경이 일어났을 때...
UnkownProperty 에 관한 json 옵션들을 주셨으니 어느 한 서비스의 작은 도메인 변경사항이 큰 파급을 미치지는 않겠지만, 제일 좋은 것은 원천소스에 대한 도메인 클래스 관리를 아예 안하고 원천소스 그대로 주고받아서, 이로 인해 발생하는 이슈를 발생시키지 않고 코드량을 줄이는 것이 좋아보입니다.
각 서비스는 자신의 비즈니스 로직으로 이용해야 할 대상만 그때그때 JsonPath 등의 라이브러리로 읽는것을 추천합니다. https://github.com/json-path/JsonPath
이것만 해도 소스코드의 절반은 날아갈 것 같습니다.
Ex) marathon apps parsing using jsonpath
String source = "원천소스";
{
"apps": [
{
"id": "/myapp",
"cmd": "env && sleep 60",
"args": null,
"user": null,
"env": {
"LD_LIBRARY_PATH": "/usr/local/lib/myLib"
},
"instances": 3,
"cpus": 0.1,
"mem": 5,
"disk": 0,
"executor": "",
"constraints": [
[
"hostname",
"UNIQUE",
""
]
],
"uris": [
"https://raw.github.com/mesosphere/marathon/master/README.md"
],
"ports": [
10013,
10015
],
"requirePorts": false,
"backoffSeconds": 1,
"backoffFactor": 1.15,
"maxLaunchDelaySeconds": 3600,
"container": null,
"healthChecks": [],
"dependencies": [],
"upgradeStrategy": {
"minimumHealthCapacity": 1,
"maximumOverCapacity": 1
},
"labels": {},
"acceptedResourceRoles": null,
"version": "2015-09-25T15:13:48.343Z",
"versionInfo": {
"lastScalingAt": "2015-09-25T15:13:48.343Z",
"lastConfigChangeAt": "2015-09-25T15:13:48.343Z"
},
"tasksStaged": 0,
"tasksRunning": 0,
"tasksHealthy": 0,
"tasksUnhealthy": 0,
"deployments": [
{
"id": "9538079c-3898-4e32-aa31-799bf9097f74"
}
]
}
]
}
# I need marathon apps deploymentsIds
List<Map> apps = JsonPath.read(source, "$.apps");
For(app in apps){
List<String> deploymentsIds = JsonPath.read(app, "$.deployments[*].id");
}
# If marathon app syntax changed via version up, fix
카프카 채널 운영 및 컨슈머 등록의 단순화
spring-kafka 또는 spring-kafka-reactive 프로젝트를 사용하셔서 소스코드를 단순화하시는 걸 추천드립니다.
Annotaion 을 통해 컨슈머를 간단하게 등록하고, 토픽 자동생성, 세션 관리, 커밋 관리, 풀 관리 등은 기본 세팅 또는 Bean 으로 관리하는게 좋아보입니다.
//메시지가 docker 채널로 들어올 때마다 receiveMetric 를 실행
@StreamListener
public void receiveMetric(channel="docker" Flux<String> inbound) {
....
}
metric type 별로 채널을 다수 운용하는 것 보다 하나의 채널안에 메트릭 타입별로 구분짓는 것이 좋아 보입니다.
Kafka 채널은 "일의 성격" 에 따라 채널을 나누는 것이 추후 확장에 유리합니다.
예를 들면
- collection: 수집 데이터 구독 채널
- rule: 알림 룰 구독 채널
- notification: 알림 구독 채널
식입니다.
따라서 수집 데이터 채널은,
Channel: collection
{
metricType: "docker/mesos/k8s/etc..",
message: 원본데이터
}
이 될 수 있겠습니다.
*이것을 이행할 경우 소스코드의 Consumer.class 클래스들은 삭제가 가능합니다.
멀티 인스턴스 상황에서 스케쥴 작업의 정합성
다음의 스케쥴 작업들을 찾아봤습니다. 소스코드를 모두 보진 못했지만, 대충 이것들의 용도가 실시간성으로 제공되야 하는 정보를 Redis 에 저장하거나, Redis 정보를 가져와 Low Level 의 이슈체크(Host check 등) 을 수행하는 것을 알 수 있었습니다.
- scheduleCrawling
- scheduleRule
- scheduleIncidentCrawling
- scheduleAgentList
- scheduleTraceCrawling
- agentStatus
현재 아키텍처는 인스턴스 마다 독립적으로 스케쥴 작업을 모두 시행하는 것으로 보입니다. 다음 그림처럼 Redis Lock 또는 Mysql Lock 을 통해 각 배치 잡을 실행할 리더를 선출하여, 멀티 인스턴스 환경에서 동일한 스케쥴을 중복 실행하지 않도록 설계하시는 걸 추천드립니다.

Batch Processing 을 리액티브 프로그래밍 활용한 Stream Processing 으로 변환.
추후 제일 문제가 될 소지가 있다고 보이는 부분입니다.
현재 아키텍처의 스케쥴링 흐름을 살펴보겠습니다. 대다수(거의 모든) 프로세스 흐름이 Batch Processing, 즉 초당(혹은 10초당) 한꺼번에 모든 데이터 셋을 불러와 로직을 수행하는 방식으로 되어있습니다.
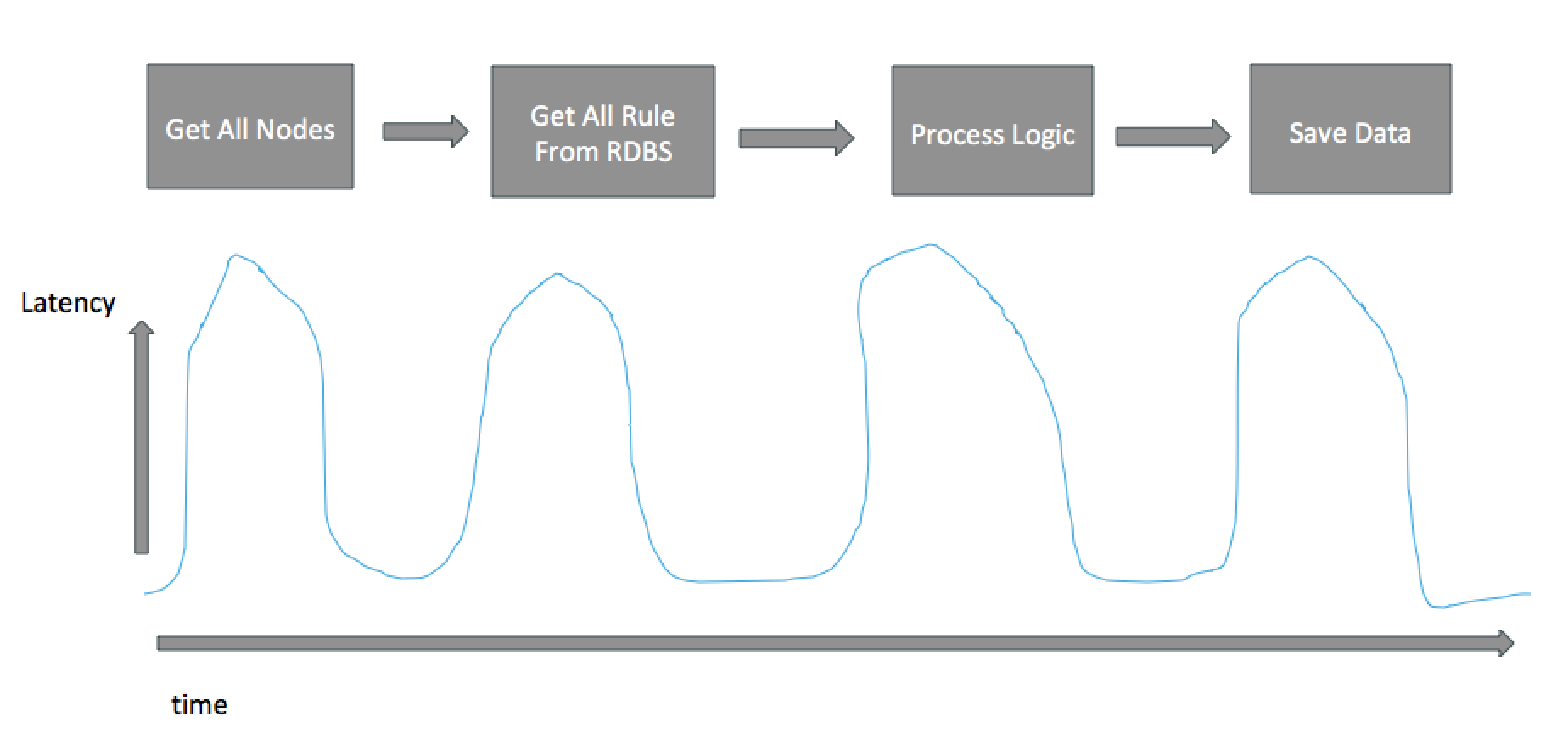
그림처럼 현재 방식을 유지할 경우 사용자가 늘어나는 만큼 각 Task 마다 latency 가 증가하는 구조로 되어있어, 스케일 아웃을 통해 문제를 해결할 수 없고, 처리해야 하는 데이터 셋이 커질수록 시스템을 보존하기 위해 배치 시간을 조절하거나, 취합하는 데이터 량을 줄이게 되는 등의 회피성 해결을 하게 됩니다.
Batch Processing 은 "설치형 솔루션" 또는 "대용량 데이터 분석" 작업에서 유효하고, Saas 형 서비스는 기본적으로 실시간 대용량 처리를 기본으로 생각해야 하기 때문에 Stream Processing 을 기준으로 설계해야 합니다.
Strem Processing 이란 데이터 원본을 하나의 파이프라인을 수립하여 "구독" 하고, 데이터 한건이 발생할 때마다 이를 판독하고 실행하는 함수로 구성됩니다. 최근에는 판독/실행 함수를 Lamda 방식의 1차함수를 정의하여 사용하는 추세입니다.
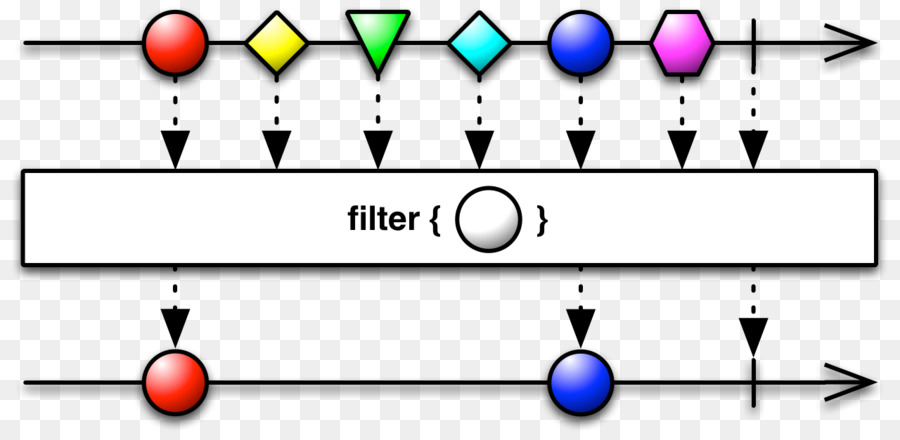
Stream Processing 은 예전부터 쓰여왔던 방식이고, 주로 센서 데이터 또는 로그 데이터를 실시간으로 처리하기 위한 프로그래밍 방식이었습니다만, 최근에는 Native Cloud 를 지향하는 회사들에서 일반 비즈니스 로직에도 적용하고 있습니다. Spring boot 를 위한 프로젝트도 있습니다. https://projectreactor.io/
참조:
그럼, 소스코드의 CustomAgentWorkflow 에 위의 시나리오를 적용해 본다면 다음과 같습니다.
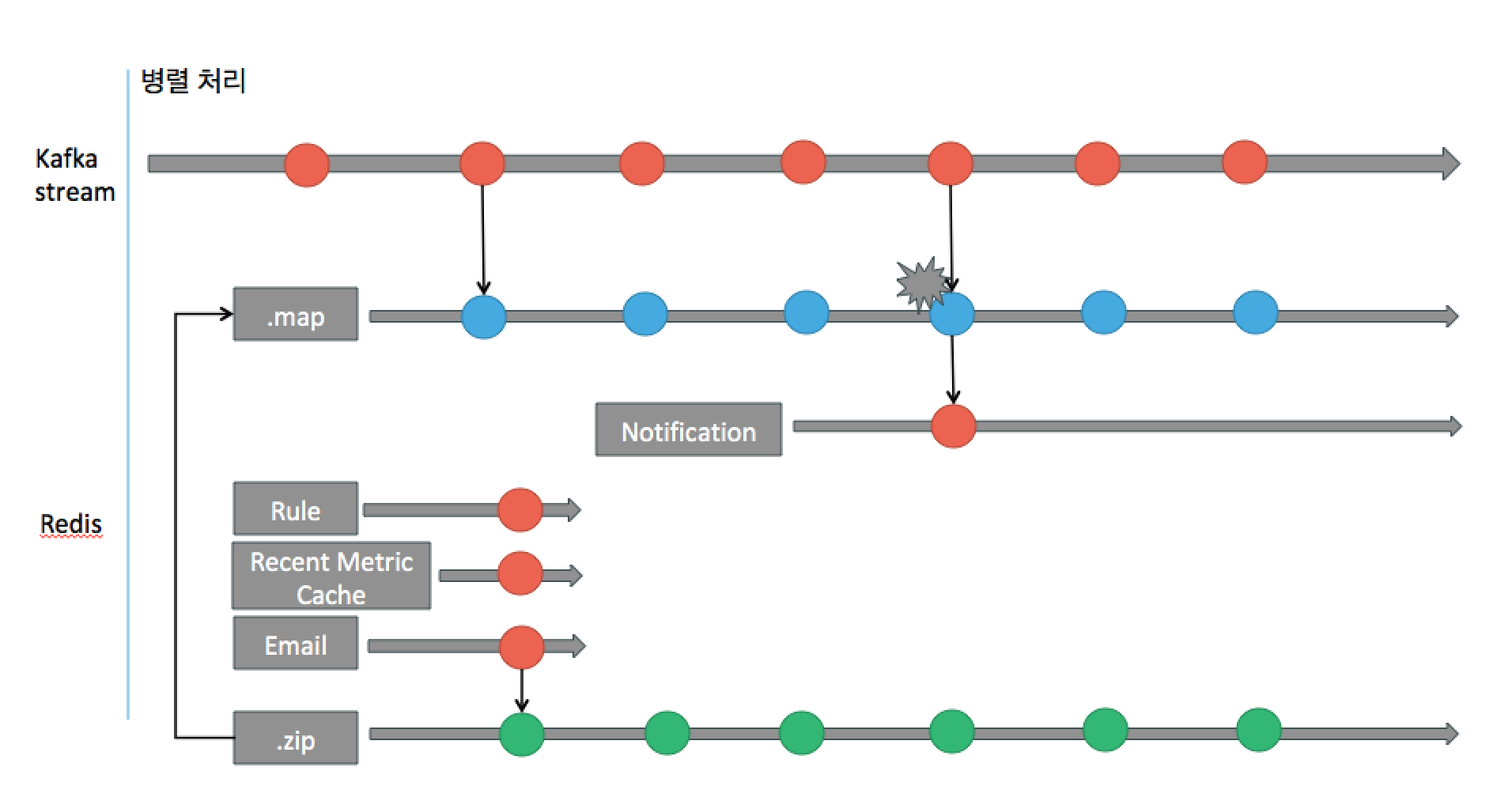
확장성 및 유지보수성을 고려한 워크플로우 룰엔진
CustomAgentWorkflow 의 rule 모델을 influx DB 쿼리로 변환하여 조회 후 판독하는 부분에서, 걱정되는 부분은 코드의 복잡성이 있어서 추후 유지보수의 어려움이 있을까 걱정입니다. 또한 Metic 기반 rule 이외에는 InfluxDB 쿼리 조합으로 만들어 지기 힘들 수 있습니다. 보통 이런 rule engine 을 적용시에는 Decision table 을 사용하는 것을 추천드립니다.
Decision table 은 아래 그림과 같이 데이터와 Condition 의 조합으로 이루어져 있고, Condition 을 한개 또는 복수개 통과한 데이터 셋에 대해 취해야 할 행동인 Action 으로 구성되어 있는 논리 테이블입니다.
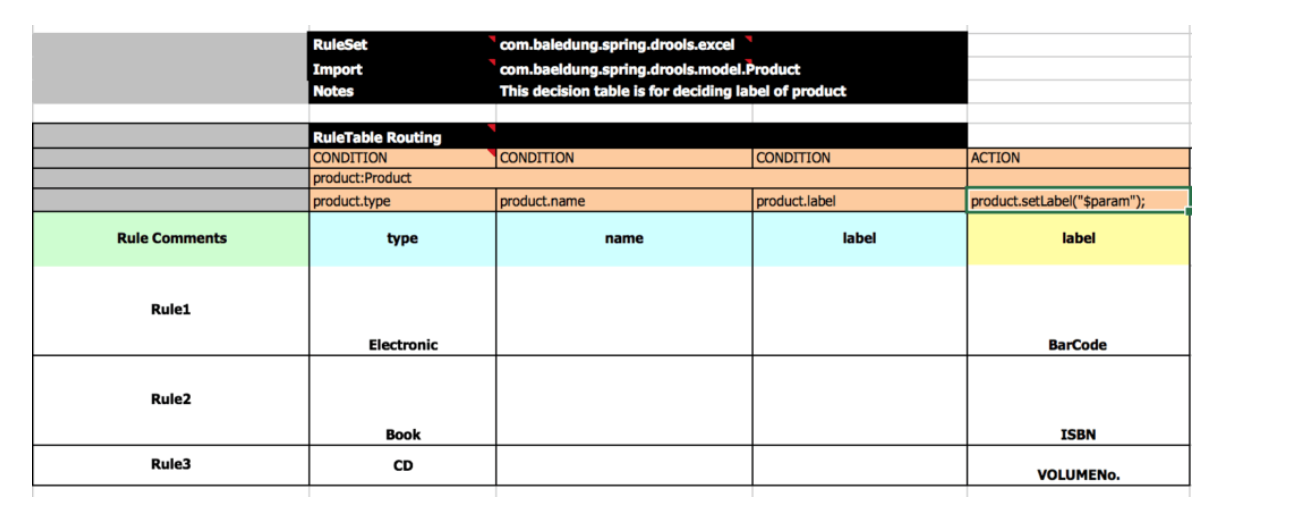
Spring 으로 구현된 Desicion table 은 Spring Drools 프로젝트가 있습니다.