Spring Cloud源码分析 - 负载均衡-Ribbon #13
Description
负载均衡
众所周知,随着用户量的增加,应用的访问量也会随之增加,单台服务器已经远不能满足高并发的业务需求,这时就需要多台服务器组成集群来应对高并发带来的业务压力,同时也需要负均衡器来对流量进行合理分配。
负载均衡是一种基础的网络服务,它的核心原理是按照指定的负载均衡算法,将请求分配到后端服务集群上,从而为系统提供并行处理和高可用的能力。
负载均衡的方式有很多种,在 Spring Cloud 体系中,Ribbon 就是负载均衡的组件,所有的请求都是通过 Ribbon 来选取对应的服务信息的。
目前主流的负载方案分为两种:
- 集中式负载均衡,在消费者和服务提供方中间使用独立的代理方式进行负载,有硬件的负载均衡器,比如 F5,也有软件,比如 Nginx。
- 客户端负载均衡,客户端根据自己的请求情况做负载,Ribbon 就属于客户端自己做负载的框架。
集中式负载均衡
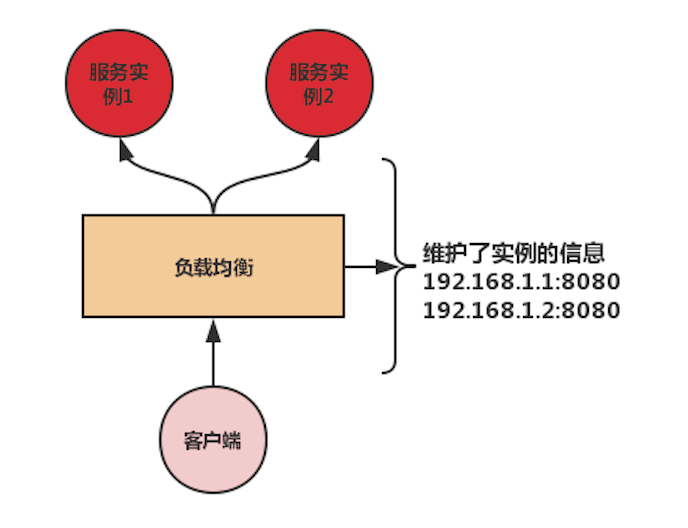
首先我们来看下集中式负载均衡,如上图所示,就是集中式负载均衡的工作原理,负载均衡器负责维护需要负载的服务实例信息,如:192.168.1.1:8080 和 192.168.1.2:8080 这两个实例。
客户端不直接请求 192.168.1.1:8080 和 192.168.1.2:8080 这两个实例,而是通过负载均衡器来进行转发,客户端的请求到了负载均衡器这里,负载均衡器会根据配置的算法在 192.168.1.1:8080 和 192.168.1.2:8080 这两个实例中选取一个实例,转发到具体的实例上。
这样的好处是客户端不需要关心对应服务实例的信息,只需要跟负载均衡器进行交互,服务实例扩容或缩容,客户端不需要修改任何代码。
客户端负载均衡
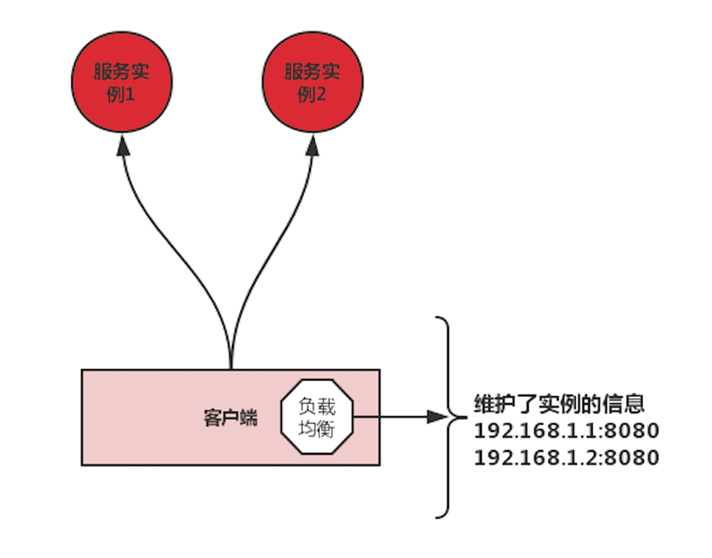
如上图所示,为客户端负载均衡,客户端负载均衡需要自己维护服务实例的信息,然后通过某些负载均衡算法,从实例中选取一个实例,直接进行访问。
最后我们总结集中式负载均衡和客户端负载均衡最大的区别:对服务实例信息的维护。集中式负载均衡的信息是集中进行维护的,比如 Nginx,都会在配置文件中进行指定。客户端负载均衡的信息是在客户端本地进行维护的,我们可以手动配置,但最常见的是从注册中心进行定时拉取。
Ribbon
Ribbon 是由 Netflix 发布的负载均衡器,它有助于控制 HTTP 和 TCP 的客户端的行为。Ribbon 属于客户端负载均衡。
为 Ribbon 配置服务提供者地址后,Ribbon 就可基于某种负载均衡算法,自动的帮助服务消费者进行请求。同时 Ribbon 默认为我们提供了很多负载均衡算法,例如:轮询、随机算法等。
主要组件
我们使用 Ribbon 主要用于负载均衡场景,实现一个通用的负载均衡框架,则需要很多组件支持,Ribbon 中就提供了这些组件,有了这些组件,整个框架的扩展性便会更好,更灵活,我们可以根据业务需求,选择是否要自定义对应的组件来满足特定场景下的需求。
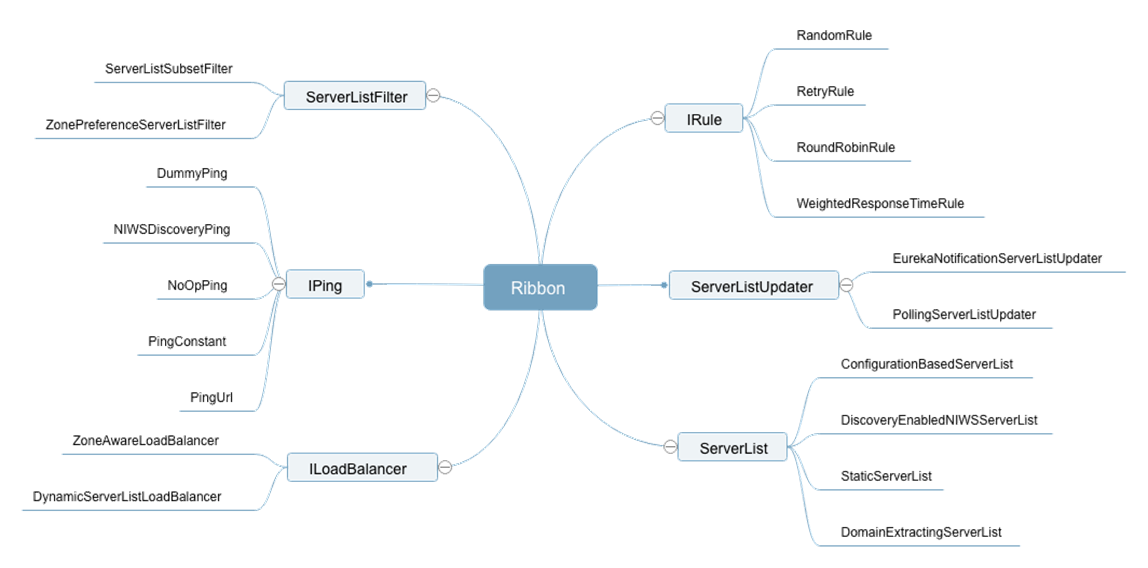
如上图所示为 Ribbon 中的主要组件,以及每个组件下目前已有的一些实现,但这里并没有把所有的内容都整理出来,需要课后自己去补充。
下面我们通过 Ribbon 的使用场景来分别介绍这些组件,当我们需要通过 Ribbon 选择一个可用的服务实例信息,进行远程调用时,Ribbon 会根据指定的算法从服务列表中选择一个服务实例进行返回。
在这个选择服务实例的过程中,服务实例信息是怎么来的呢?
最后做下总结,从 Ribbon 的核心功能出发,我们分析了 Ribbon 内部的主要组件,以及每个组件的职责,并且这些组件都支持自定义,扩展性很强。
各组件作用如下图所示。

- ILoadBalancer:定义一系列的操作接口,比如选择服务实例。
- IRule:算法策略,内置算法策略来为服务实例的选择提供服务。
- ServerList:负责服务实例信息的获取,可以获取配置文件中的,也可以从注册中心获取。
- ServerListFilter:过滤掉某些不想要的服务实例信息。
- ServerListUpdater:更新本地缓存的服务实例信息。
- IPing:对已有的服务实例进行可用性检查,保证选择的服务都是可用的。
使用方式
Ribbon 的使用方式主要分为下面这三种,
- 原生 API,Ribbon 是 Netflix 开源的,如果你没有使用 Spring Cloud,也可以在项目中单独使用 Ribbon,在这种场景下就需要使用 Ribbon 的原生 API。
- Ribbon + RestTemplate,当我们项目整合了 Spring Cloud 时,就可以用 Ribbon 为 RestTemplate 提供负载均衡的服务。
- Ribbon + Feign,关于 Feign 的使用方式会在后面的章节中进行详细的讲解。
负载均衡策略
内置负载均衡策略
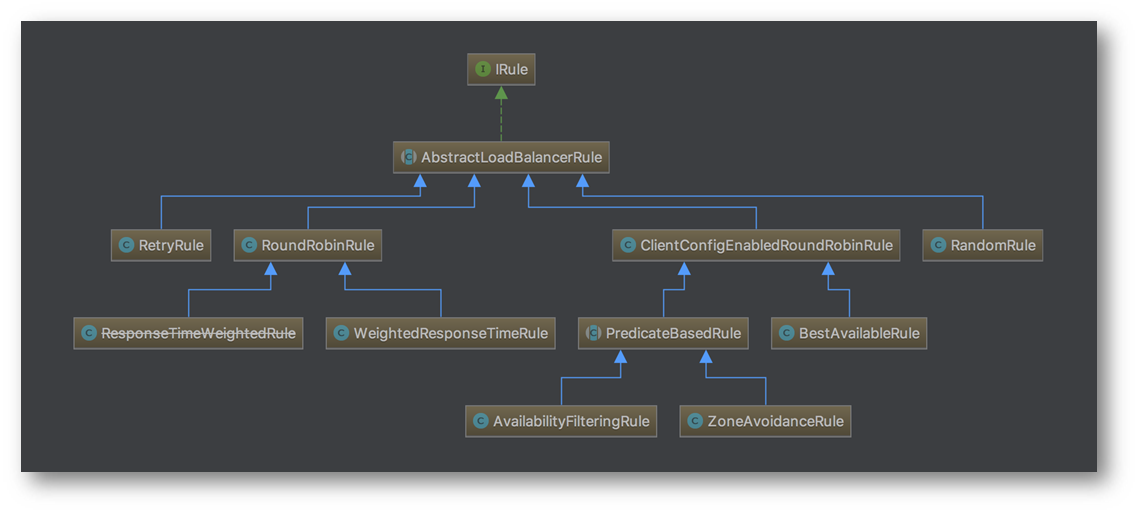
IRule 是算法的接口。AbstractLoadBalancerRule 是实现了 IRule 接口的抽象类,所有内置的算法都是继承 AbstractLoadBalancerRule 来实现的。
RoundRobinRule 是轮询的算法,如果有 A、B 两个实例,那么该算法的逻辑是选择 A,再选择B,再选择A,轮询下去。
RandomRule 是随机算法,这个就比较简单了,在服务列表中随机选取。
BestAvailableRule 选择一个最小的并发请求 server,如果有 A、B 两个实例,当 A 有 4 个请求正在处理中,B 有 2 个请求正在处理中,下次选择的时候会选择 B,因为 B 处理的数量是最少的,认为它压力最小,这种场景适合于服务所在机器的配置都相同的情况下,否则不太适用。
应用场景
Ribbon 中内置了很多的负载均衡算法供我们使用,同时也支持让用户自定义负载均衡算法。自定义负载均衡算法我个人觉得是 Ribbon 中最核心的功能,也是我们开发人员必须要掌握的技能。不是说你会简单的去定制一个算法,然后在 Ribbon 中可以生效,你就掌握了它,而是你能熟练的在各种场景中去使用。
这里总结了 4 种自定义负载均衡算法的使用场景。
-
定制跟业务更匹配的策略
这点是在开发过程中相关度比较大的,就是某些场景可能更适合轮询算法,但是单纯的轮询算法可能不是你想要的,这个时候就需要在轮询的基础上,加上一些你自己的逻辑,组成一个新的算法,让 Ribbon 使用这个算法来进行服务实例的选择。 -
灰度发布
灰度发布是能够平滑过渡的一种发布方式,在发布过程中,先发布一部分应用,让指定的用户使用刚发布的应用,等到测试没有问题后,再将其他的全部应用发布。如果新发布的有问题,只需要将这部分恢复即可,不用恢复所有的应用。 -
多版本隔离
多版本隔离跟灰度发布类似,为了兼容或者过度,某些应用会有多个版本,这个时候如何保证 1.0 版本的客户端不会调用到 1.1 版本的服务,就是我们需要考虑的问题。 -
故障隔离
当线上某个实例发生故障后,为了不影响用户,我们一般都会先留存证据,比如:线程信息、JVM 信息等,然后将这个实例重启或直接停止。然后线下根据一些信息分析故障原因,如果我能做到故障隔离,就可以直接将出问题的实例隔离,不让正常的用户请求访问到这个出问题的实例,只让指定的用户访问,这样就可以单独用特定的用户来对这个出问题的实例进行测试、故障分析等。
上面这 4 种场景在实际工作中是非常有用的,特别是在面试过程中,如果你能详细的说出怎么去实现这些场景,绝对是大的加分项。那么这 4 个场景跟 Ribbon 有什么关系呢?
前面我说 Ribbon 最核心的功能点是自定义负载均衡算法,这是有实际依据的。首先能自定义负载均衡算法,也就表示我们可以控制 Ribbon 的服务选择,Ribbon 选择出的服务信息是要进行接口交互的,比如说我想要实现故障隔离,就得不让正常的请求调用到这个出问题的实例,在策略中将这个出问题的实例过滤,这样选择出来的实例就不会是出故障的那个。
总的来说就是一句话,控制了 Ribbon 的服务选择,你就可以实现很多你想实现的功能。
Ribbon 饥饿加载模式
Ribbon 在进行客户端负载均衡时并不是在启动时就加载上下文,而是在第一次请求时才去创建,因此第一次调用会比较慢,有可能会引起调用超时。可以通过指定 Ribbon 客户端的名称,在启动时加载这些子应用程序上下文的方式,来避免这个问题。
enabled 要设置成 true,clients 表示要加载的客户端,也就是我们要调用的服务名称,可以配置多个。
如果在面试过程中,面试官刚好问了你这个问题,你将配置的内容都回答了,然后面试官进一步追问,这个配置是在哪个类中体现的?这种问题很明显面试官是在考察你有没有看过源码,有没有去对这个问题做深入的了解。
对应的代码在 RibbonAutoConfiguration 中,找到 ribbonApplicationContextInitializer 这个方法,通过 @ConditionalOnProperty 注解来指定启用的配置,进入 RibbonApplicationContextInitializer 中,在 onApplicationEvent 方法中会进行初始化,也就是循环的根据每个客户端获取上下文。
那么为什么说第一次初始化后,后面就变快了,那是因为初始化后进行了缓存操作,进入 getContext 方法中,可以看到如果在 contexts 中不存在才会创建缓存,创建的时候会用 synchronized 加锁,并进行二次判断,防止并发下出现创建多次的问题。最后进行增加操作,如果有的话就直接从 contexts 获取返回。contexts 就是一个 ConcurrentHashMap。
配置方式自定义 Ribbon Client

从 1.2.0 版本开始,支持通过属性配置的方式来定义 Ribbon Client。配置格式也是标准的,clientName 就是服务名称,比如 user-service,当我们需要配置一个自定义算法的时候,那就是 user-service.ribbon.NFLoadBalancerRuleClassName = 算法类的路径。
通过配置定义的好处在于,我们在不同环境下,可以在启动时进行指定,使用代码类配置的方式,写好就固定了,灵活度不高。