Bootstrapping until certain values are reached #38
Description
Hi all,
I am trying to bootstrap (with replacement) from a dataframe, repeatedly until the column sums for each of the data columns reaches a predefined value.
My dataframe is small and pretty simple. It looks like this:
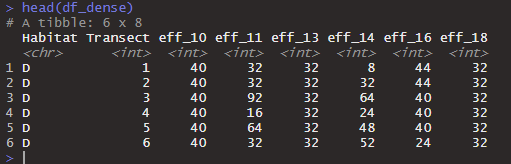
with these dimensions:
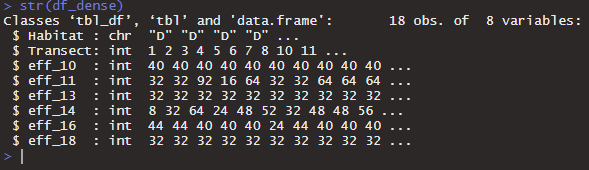
The data columns I am interested in summing after each resampling loop are columns 3:8, i.e. all those starting with "eff_"
What I have tried
So far, I have tried (with some success) using a repeat loop. My first example below is where I have told it to stop after only the first data column reaches the pre-defined value of 720. The code is as follows
first <- sample_n(df_dense, 5, replace = TRUE) ## create the first bootstrap sample
eff_10_lim <- 720 ## set the limit after which the loop should stop
repeat {
subseq <- sample_n(df_dense, 1, replace = TRUE) ## do the next bootstrap
first <- rbind(first,subseq) ## join the first sample with each subsequent sample
N10 <- colSums(first[ ,3]) ## sum the eff_10 column
if(N10 > eff_10_lim ) {
break ## tell it to stop once the column sum is greater than the defined value
}
}
This appears to work. The loop stops, and first is a dataframe where the eff_10 column has a colSum of just over 720.
Just a note - I am taking a sample of 1 row in each subsequent bootstrap above on purpose - I think if I increase the number of samples then after each iteration the colSum will have jumped up a lot, meaning that when the loop stops the colSum will be quite a lot larger than the defined stop value.
Next I tried to add more conditions, using the following code:
set.seed(42)
first <- sample_n(df_dense, 5, replace = TRUE) ## Create first bootstrap sample
eff_10_lim <- 720
eff_11_lim <- 756 ## these are the limits for the other data columns
eff_13_lim <- 560
eff_14_lim <- 660
eff_16_lim <- 660
eff_18_lim <- 576
repeat {
subseq <- sample_n(df_dense, 1, replace = TRUE)
first <- rbind(first,subseq)
N10 <- colSums(first[ ,3])
N11 <- colSums(first[ ,4])
N13 <- colSums(first[ ,5]) ## now I am summing all of the data columns
N14 <- colSums(first[ ,6])
N16 <- colSums(first[ ,7])
N18 <- colSums(first[ ,8])
if(N10 > eff_10_lim & N11 > eff_11_lim & N13 > eff_13_lim &
N14 > eff_14_lim & N16 < eff_16_lim & N18 > eff_18_lim) {
break
}
## above I have tried to tell it to stop when N10 is greater than its limit, AND N11 is greater that its limit, etc.etc
}
I don't think the above had worked though, as R seems to just run and run and run, so I think I may have accidentally created some infinite loop!
My questions are:
- Is the code in the first example doing what I think/want it to do?
- How would I add more conditions, like in the second example?
- Is there a simpler/more efficient way of doing this? I feel like I'm over-complicating it...
Reproduce the problem
Here is some code to reproduce a simplified version of the data for you:
df_dense <- data.frame(Habitat = rep("D", times=18),
Transect=c(1:8,10:12,15,18:19,28,32:33,36),
eff_10 = rep(40, times=18),
eff_11 = rep(32, times=18),
eff_13 = rep(32, times=18),
eff_14 = rep(48, times=18),
eff_16 = rep(44, times=18),
eff_18 = rep(32, times=18))
Many thanks in advance!!!