Useful code snippets #34
Replies: 4 comments
-
|
This isn't a snippet, but in case you need to draw waterfall charts in Python! https://github.com/actuarialopensource/modelx-samples/blob/master/waterfall.ipynb draw_waterfall(df, title="Cashflows")
|
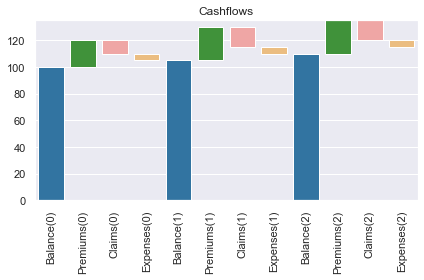
Beta Was this translation helpful? Give feedback.
-
|
thank you very much for this. I already briefly googled this topic earlier today but didn't find one with nice colours. |
Beta Was this translation helpful? Give feedback.
-
|
This is a simplified version of waterfalls, just using series data and fewer colours, but with labels to select base, and data labels. df = pd.Series({ "Premiums": 20,
"Claims": -10,
"Expenses": -5})
df['Total']=df.sum()
draw_waterfall(df, title='demo', stocks=['Total'], show=True)
|
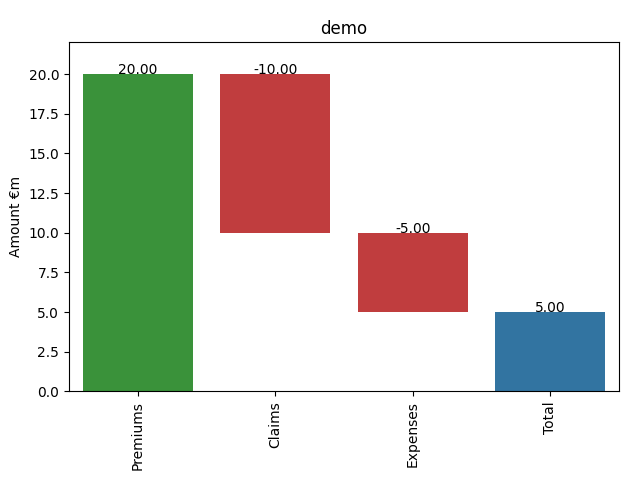
Beta Was this translation helpful? Give feedback.
-
|
Here's an R script I used in my lossrx R Package (WIP) that quickly simulates transactional claims data for P&C reserving - GitHub.com | jimbrig/lossrx > claims_transactional.R (Note that the original version of this script was a GitHub Gist. View Script
# ------------------------------------------------------------------------
#
# Title : Transactional Loss Data Simulation
# By : Jimmy Briggs
# Date : 2020-11-06
#
# ------------------------------------------------------------------------
# simulate transactions on insurance claims
# transactions will include claim closures, payments and changes in case reserves
# this is all completely made up and does not accurately resemble actual claims
library(lubridate)
library(dplyr)
library(tibble)
library(randomNames)
library(tidyr)
# source("R/utils.R")
devtools::load_all()
# number of claims
n_claims <- 10000
# start/end dates & accident range
beg_date <- as.Date("2015-01-01")
end_date <- end_of_month(start_of_month(Sys.Date()) - 1)
accident_range <- as.numeric(end_date - beg_date)
set.seed(1234)
accident_date <- sample(0:accident_range, size = n_claims, replace = TRUE)
payment_fun <- function(n) rlnorm(n, 7.5, 1.5)
claims <- tibble::tibble(
claim_num = 1:n_claims,
claim_id = paste0("claim-", 1:n_claims),
accident_date = beg_date + lubridate::days(accident_date),
state = sample(c("TX", "CA", "GA", "FL"), size = n_claims, replace = TRUE),
claimant = randomNames::randomNames(n_claims),
report_date = rnbinom(n_claims, 5, .25),
# 0 if claim closed when reported
status = rbinom(n_claims, 1, 0.96),
# initial payment amount
payment = payment_fun(n_claims)) %>%
dplyr::mutate(report_date = accident_date + report_date,
# set payment to zero if closed when reported
payment = ifelse(status == 0, 0, payment),
case = payment * runif(n_claims, 0.25, 8.0),
transaction_date = report_date) %>%
dplyr::arrange(accident_date)
## simulate transaction dates
# simulate number of transactions for each claim
n_trans <- rnbinom(n_claims, 3, 0.25)
# simulate lag to each transaction
trans_lag <- lapply(n_trans, function(x) rnbinom(x, 7, 0.1))
trans_lag <- lapply(trans_lag, function(x) {
if (length(x) == 0) 0 else x
})
for (i in seq_len(n_claims)) {
trans_lag[[i]] <- data_frame(
"trans_lag" = trans_lag[[i]],
"claim_id" = paste0("claim-", i),
"claim_num" = i
)
}
trans_tbl <- bind_rows(trans_lag) %>%
group_by(claim_id, claim_num) %>%
# switch from incremental to cumulative lag
mutate(trans_lag = cumsum(trans_lag)) %>%
ungroup()
# separate all zero claims from the claims that have payments
zero_claims <- dplyr::filter(claims, status == 0)
first_trans <- dplyr::filter(claims, status == 1)
subsequent_trans <- left_join(trans_tbl, first_trans, by = c("claim_num", "claim_id")) %>%
filter(!is.na(accident_date))
n_trans <- nrow(subsequent_trans)
# simulate subsequent transaction payments
subsequent_trans <- subsequent_trans %>%
mutate(payment = payment_fun(n_trans),
case = pmax(case * rnorm(n_trans, 1.5, 0.1) - payment, 500),
transaction_date = report_date + trans_lag) %>%
select(-trans_lag)
trans <- bind_rows(zero_claims, first_trans, subsequent_trans) %>%
arrange(transaction_date)
# add in a transaction number
trans$trans_num <- 1:nrow(trans)
# set final trans status to closed and case to 0
trans <- trans %>%
arrange(trans_num) %>%
group_by(claim_num, claim_id) %>%
mutate(final_trans = ifelse(trans_num == max(trans_num), TRUE, FALSE),
status = ifelse(final_trans, 0, 1),
case = ifelse(final_trans, 0, case),
status = ifelse(status == 0, "Closed", "Open"),
paid = round(cumsum(payment), 0),
case = round(case, 0),
payment = round(payment, 0)) %>%
select(-final_trans) %>%
arrange(accident_date) %>%
ungroup() %>%
# filter out any transactions past latest eval
filter(.data$transaction_date <= end_date)
fs::dir_create("data-raw/cache")
qs::qsave(trans, file = paste0("data-raw/cache/", Sys.Date(), "-transactional-claims.qs"))
claims_transactional <- trans
usethis::use_data(claims_transactional, overwrite = TRUE)Further, I functionalized this workflow into an R function View Function
#' simulate_claims
#'
#' @description A function to simulate *transactional* actuarial claims/loss
#' data for Property Casualty Insurance.
#'
#' @param n_claims Numeric - Number of claims to be simulated.
#' @param start_date,end_date Character/Date - Start and End dates for simulation to create claims within (experience_period).
#' @param seed Numeric - the seed is used to isolate randomness during statistical simulations.
#' @param loss_distribution Character - must be one of the distributions mentioned in the details below. Defaults to lognormal.
#' @param params Parameters associated with the specified `loss_distribution`
#' in a list (i.e. `list(mean_log = 7.5, sd_log = 1.5)` for lognormal distribution).
#' @param status_prob_open Numeric - must be within `0 < x < 1` and represents
#' probability a claim is open when running binomial simulations for claims'
#' status.
#' @param cache Boolean/Logical - enable caching?
#' @param ... If needed
#'
#' @details
#'
#' Severity/Loss Distributions:
#' - Normal: `norm`
#' - Lognormal: `lnorm`
#' - Gamma: `gamma`
#' - LogGamma: `lgamma`
#' - Pareto: `pareto`
#' - Weibull: `weibull`
#' - Generalized Beta: `genbeta`
#'
#' @return The return value, if any, from executing the function.
#'
#' @importFrom dplyr mutate arrange bind_rows group_by ungroup filter left_join select
#' @importFrom lubridate days
#' @importFrom randomNames randomNames
#' @importFrom stats rlnorm rnbinom rbinom runif rnorm
#' @importFrom tibble tibble
#' @importFrom rlang .data .env
simulate_claims <- function(n_claims = 1000,
start_date = "2015-01-01",
end_date = Sys.Date(),
seed = 12345,
loss_distribution = "lnorm",
params = list(mean_log = 7.5, sd_log = 1.5),
status_prob_open = 0.96,
cache = FALSE,
...) {
# loss_distribution <- match.arg("loss_distribution")
stopifnot(
is.numeric(n_claims) && n_claims > 0,
class(as.Date(start_date)) == "Date",
class(as.Date(end_date)) == "Date" &&
as.Date(end_date) > as.Date(start_date),
is.numeric(seed),
loss_distribution %in% c(
"lnorm",
"lognormal",
"normal",
"gamma",
"lgamma",
"pareto",
"weibull",
"genbeta"
),
is.numeric(status_prob_open),
status_prob_open > 0 && status_prob_open < 1
)
beg_date <- as.Date(start_date)
end_date <- as.Date(end_date)
accident_range <- as.numeric(end_date - beg_date)
set.seed(seed)
accident_date <- sample(0:accident_range, size = n_claims, replace = TRUE)
# mean_log <- 7.5
# sd_log <- 1.5
payment_fun <- function(n) stats::rlnorm(n, params$mean_log, params$sd_log)
claims <- tibble::tibble(
claim_num = paste0("claim-", 1:n_claims),
accident_date = beg_date + lubridate::days(accident_date),
state = sample(c("TX", "CA", "GA", "FL"), size = n_claims, replace = TRUE),
claimant = randomNames::randomNames(n_claims),
report_lag = stats::rnbinom(n_claims, 5, .25), # 0 if claim closed when reported
status = stats::rbinom(n_claims, 1, 0.96), # initial payment amount
payment = payment_fun(n_claims)
) %>%
dplyr::mutate(
report_date = .data$accident_date + .data$report_lag,
payment = ifelse(.data$status == 0, 0, .data$payment),
case = .data$payment + stats::runif(.env$n_claims, 0.25, 8.0),
transaction_date = .data$report_date
) %>%
dplyr::arrange(.data$accident_date)
n_trans <- stats::rnbinom(n_claims, 3, 0.25)
trans_lag <- lapply(n_trans, function(x) stats::rnbinom(x, 7, 0.1)) %>%
lapply(function(x) { if (length(x) == 0) 0 else x })
for (i in seq_len(n_claims)) {
trans_lag[[i]] <- tibble::tibble(
"trans_lag" = trans_lag[[i]],
"claim_num" = paste0("claim-", i)
)
}
trans_tbl <- dplyr::bind_rows(trans_lag) %>%
dplyr::group_by(.data$claim_num) %>%
dplyr::mutate(trans_lag = cumsum(.data$trans_lag)) %>%
dplyr::ungroup()
# separate all zero claims from the claims that have payments
zero_claims <- dplyr::filter(claims, .data$status == 0)
first_trans <- dplyr::filter(claims, .data$status == 1)
subsequent_trans <- dplyr::left_join(trans_tbl, first_trans, by = "claim_num") %>%
dplyr::filter(!is.na(.data$accident_date))
n_trans <- nrow(subsequent_trans)
subsequent_trans <- subsequent_trans %>%
dplyr::mutate(payment = payment_fun(.env$n_trans),
case = pmax(.data$case * stats::rnorm(.env$n_trans, 1.5, 0.1) - .data$payment, 500),
transaction_date = .data$report_date + .data$trans_lag) %>%
dplyr::select(-.data$trans_lag)
trans <- dplyr::bind_rows(zero_claims, first_trans, subsequent_trans) %>%
dplyr::arrange(.data$transaction_date)
# add in a transaction number
trans$trans_num <- 1:nrow(trans)
# set final trans status to closed and case to 0
trans <- trans %>%
dplyr::arrange(.data$trans_num) %>%
dplyr::group_by(.data$claim_num) %>%
dplyr::mutate(final_trans = ifelse(.data$trans_num == max(.data$trans_num), TRUE, FALSE),
status = ifelse(.data$final_trans, 0, 1),
case = ifelse(.data$final_trans, 0, .data$case),
status = ifelse(.data$status == 0, "Closed", "Open"),
paid = round(cumsum(.data$payment), 0),
case = round(.data$case, 0),
payment = round(.data$payment, 0)) %>%
dplyr::select(-.data$final_trans) %>%
dplyr::arrange(.data$accident_date) %>%
dplyr::ungroup() %>%
dplyr::arrange(.data$claim_num, dplyr::desc(.data$transaction_date))
if (cache) { saveRDS(trans, file = "trans.RDS") }
trans
} |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I start a thread for code snippets people find useful, but probably not meaningful enough to justify a dedicated place in a repo.
I will start the ball rolling with something that I use every day and saves me a ton of time. I write to most of my model output to pickle files, which I think are great since they preserve data types and structure (particularly a date- or period-indexed data frame). Often it is nice to inspect the content of the .pkl without opening a IDE and loading it. I discovered context_menu, which seems to work very well on Windows 10.
The following code, when run from a script, adds an 'unpickle' option to .pkl files. So when you right click the file you can choose to unpickle it, to an xlsx file in the same location with the same name. Double-click also seems to work since this is the only option associated with .pkl on my machine.
Beta Was this translation helpful? Give feedback.
All reactions