Feature Request: CLIP Interrogate #40
Description
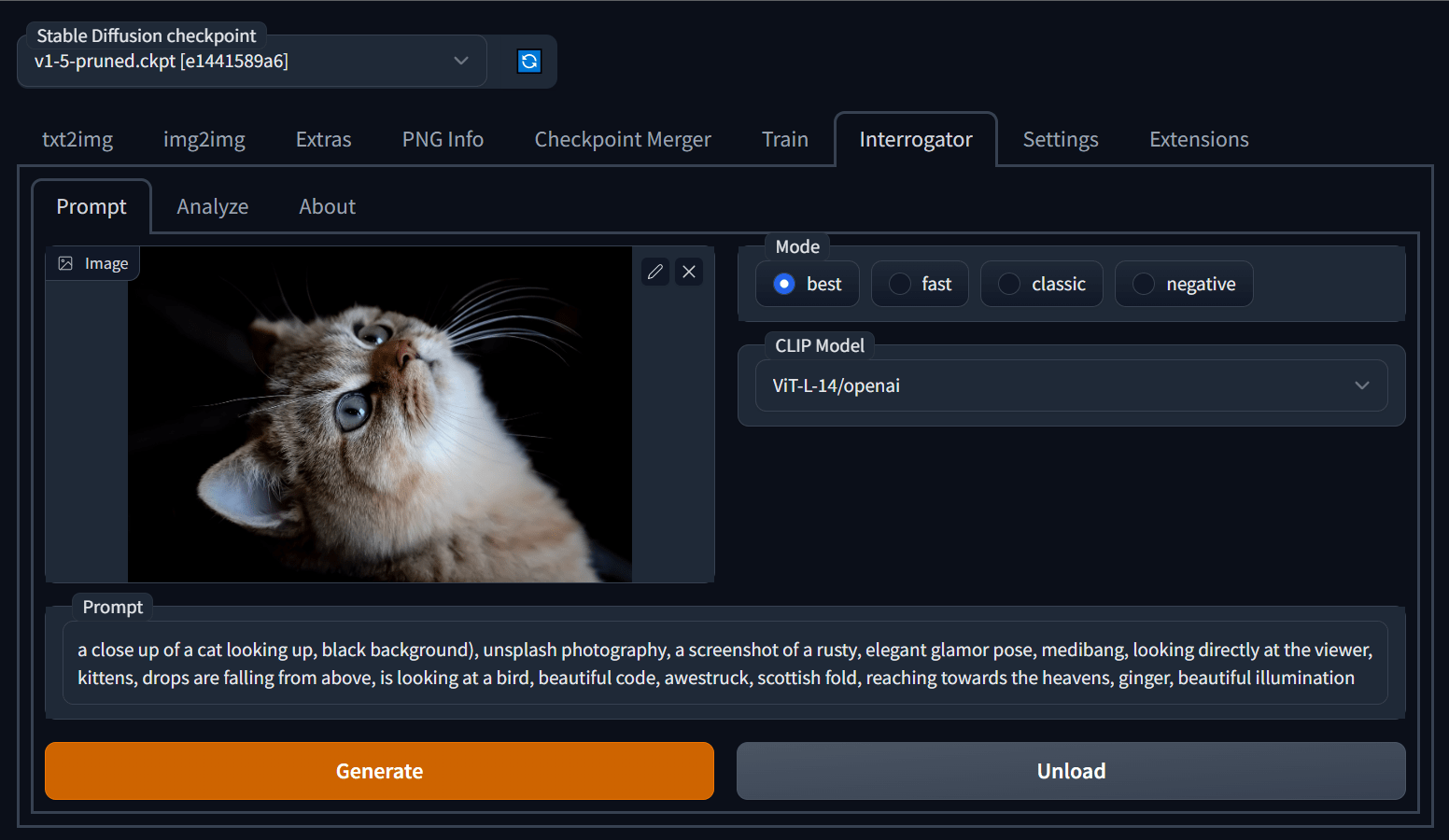
Akin to the A1111 functionality.
{kind=link}
While CLIP/JoyCaption/WD-Tagger may be very similar to using a VLM-LLM to caption an image, the use-case and mechanics are, for the user, very different. That kind of captioning is super useful but not a replacement in a situation where you want to quickly print a list of tags.
As far as the extension itself goes, some of us just like local/private things vs online/cloud-based and running these things local can be burdensome on local hardware. The ComfyUI workflows, even ones like FloCap are self-contained VLM loader/runner/unloader that will load the VLM, query it, print the response, and unload it. That would be -super- useful, I think, if possible in an extension.
Here's an explanation as to why I/we want what we want. Lets say I want to make an image of some character, take Minfilia for example. Most models may not know her, whatever - fine. However, if we google a pic of her, throw it in CLIP/WD-Tagger etc., it will give us a list of tags, using the same words image gen models understand that usually work, very well, to reporoduce the character, art-style pose in the image. Those tags etc work well in tag-based img models and also in modern llm based models like Flux, Wan, Qwen.
I still decide, once in a while that I want to borrow aspects from an image but cant think of the words. When I used A1111, I could ask CLIP and I would often learn new names for things, terms, art-styles even artist names that way. Something like that would be very useful.
paste image > load clip/llm > interogate > print tags > unload clip/llm.
Using the clip models, joycaption and wd-tagger worked especially good because you didnt need to fuss with setting up ollama or any sort of a llm backend. It would just use whatever was built-in to it.
Yeah, stuff like using an LLM to apply the Qwen system prompt as a prompt enhancer would be nice, that and Urabewe's idea of asking the LLM to write a motion-prompt for you for Wan would also be superuseful. Doesnt seem possible or likely without the burdern/overhead of a cloud-based-api or llm-backend so I get it that we dont have "Just press a button" for these LLM specific tasks. The CLIP Interogate was something A1111 had built-in, and there are minimalist workflows for comfyui to perform similar tasks with other tagging models like JoyCaption & WD-Tagger.